Abstract: Speech enhancement (SE) is used as a frontend in speech applications including automatic speech recognition (ASR) and telecommunication. A difficulty in using the SE frontend is that the appropriate noise reduction level differs depending on applications and/or noise characteristics. In this study, we propose "signal-to-noise ratio improvement (SNRi) target training"; the SE frontend is trained to output a signal whose SNRi is controlled by an auxiliary scalar input. In joint training with a backend, the target SNRi value is estimated by an auxiliary network. By training all networks to minimize the backend task loss, we can estimate the appropriate noise reduction level for each noisy input in a data-driven scheme. Our experiments showed that the SNRi target training enables control of the output SNRi. In addition, the proposed joint training relatively reduces word error rate by 4.0\% and 5.7\% compared to a Conformer-based standard ASR model and conventional SE-ASR joint training model, respectively. Furthermore, by analyzing the predicted target SNRi, we observed the jointly trained network automatically controls the target SNRi according to noise characteristics.
NOTE: Noisy samples were generated by mixing samples from two datasets: speech from the same dataset as WaveGrad [1] and noise from the TAU Urban Audio-Visual Scenes 2021 dataset [2]. Therefore, there is a discrepancy between training and test samples.
Contents:
Audio examples for output SNRi control
Output examples for joint SE-ASR training
References
Audio examples for output SNRi control
Example 1
Text: I can't speak for Scooby, but have you looked in the Mystery Machine? Noisy input 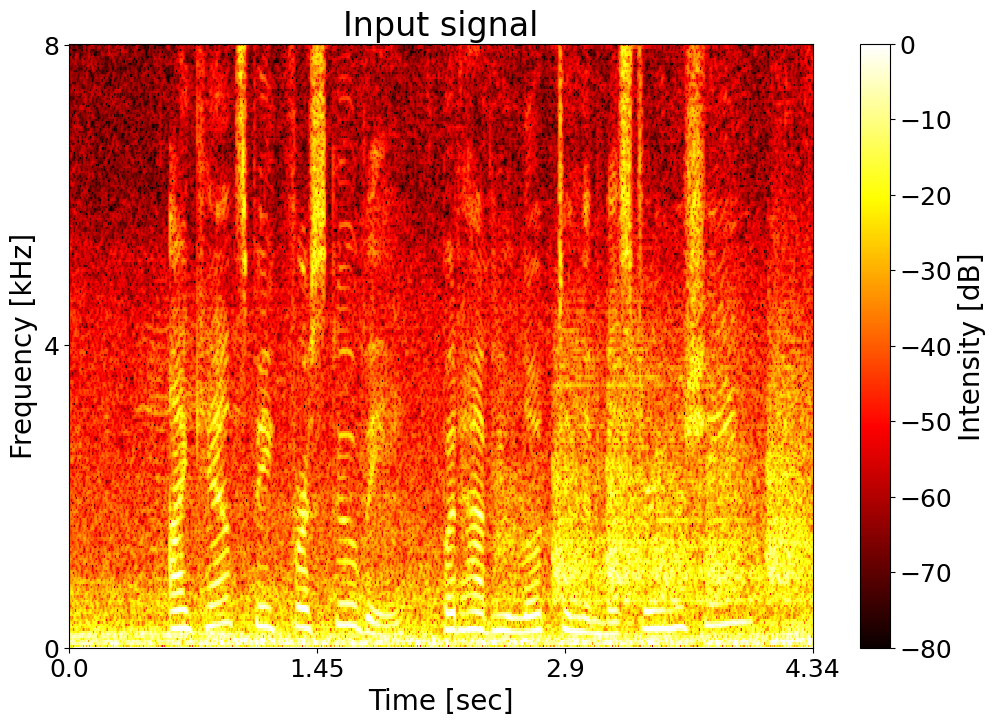 |
Clean speech 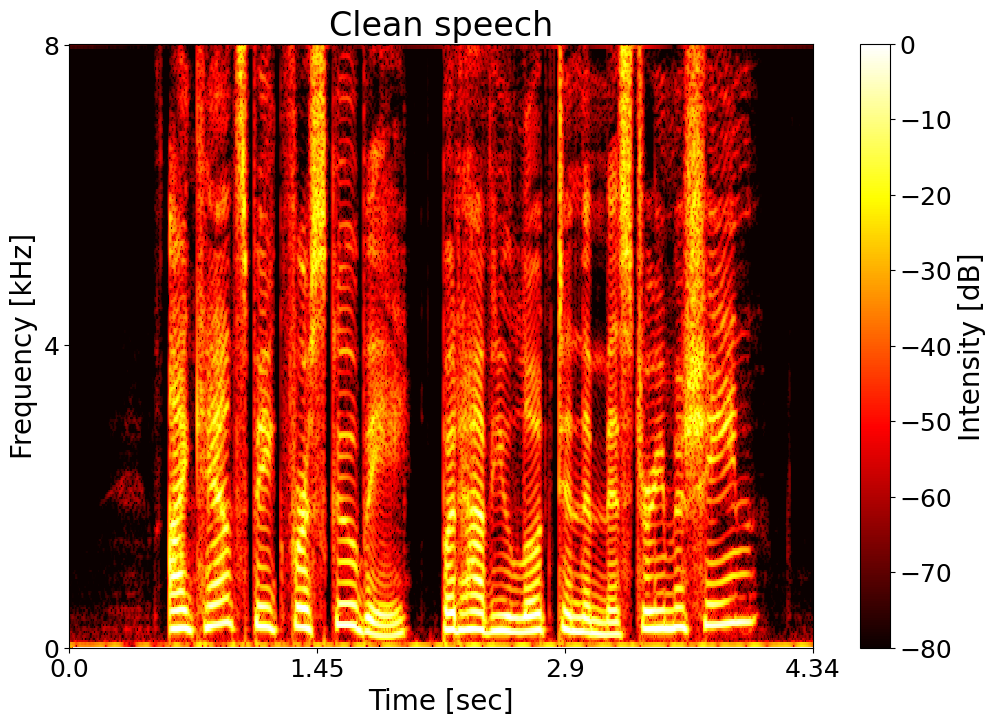 |
Target SNRi = 3.0 dB 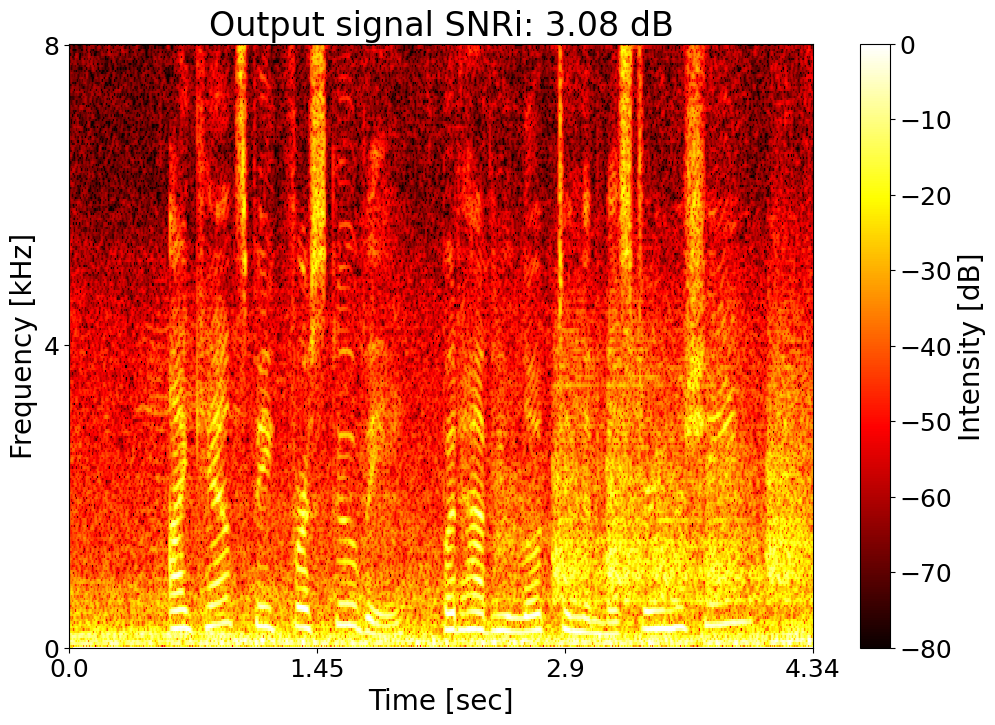 |
Target SNRi = 6.0 dB 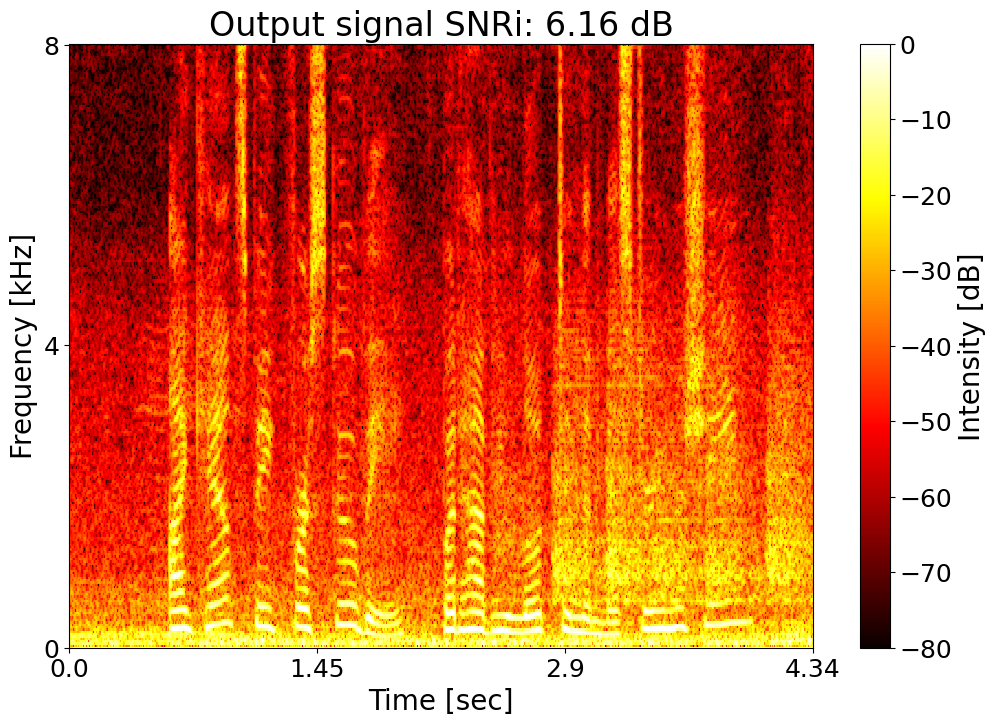 |
Target SNRi = 9.0 dB 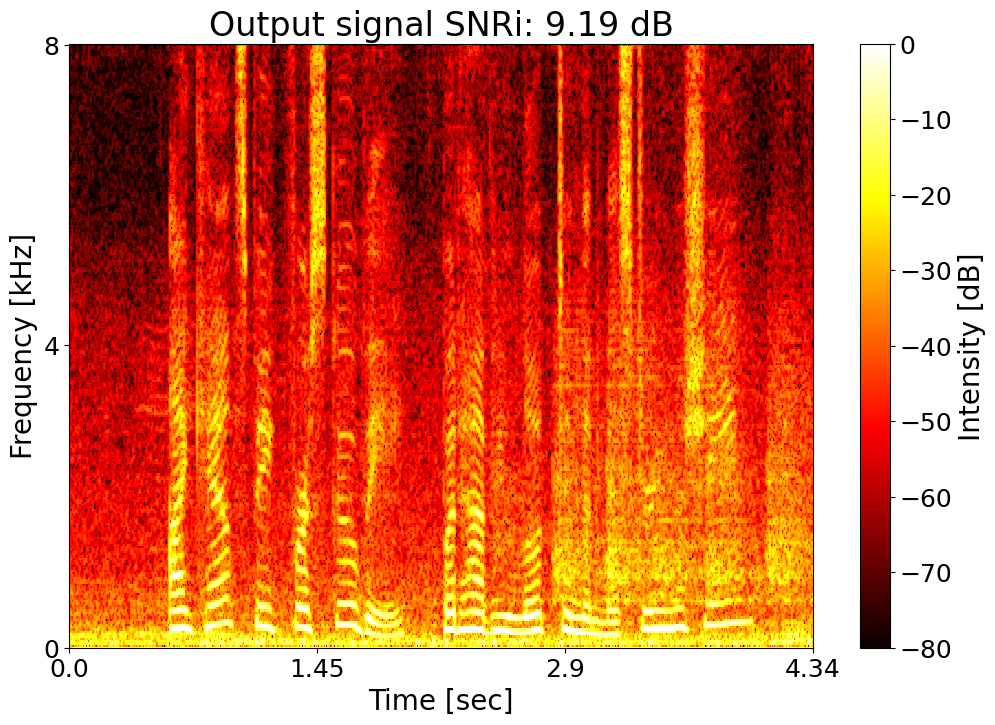 |
Target SNRi = 12.0 dB 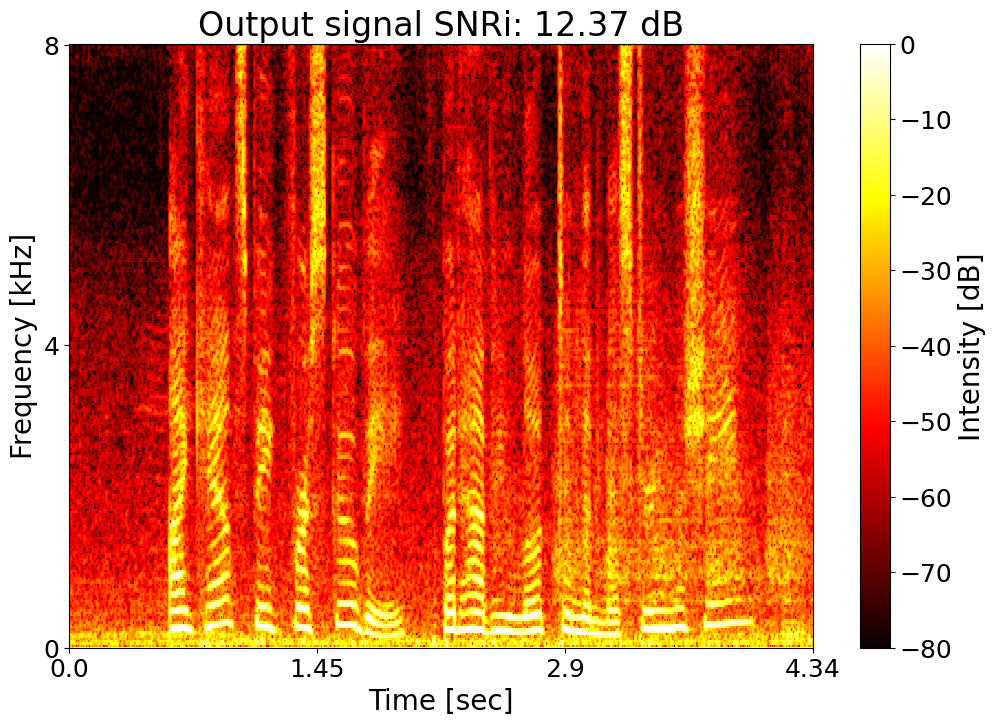 |
Example 2
Text: The dreaded, head pounding, body aching, feverish, nauseating, cough fest packs equal parts misery and inconvenience.Ground truth:
Noisy input 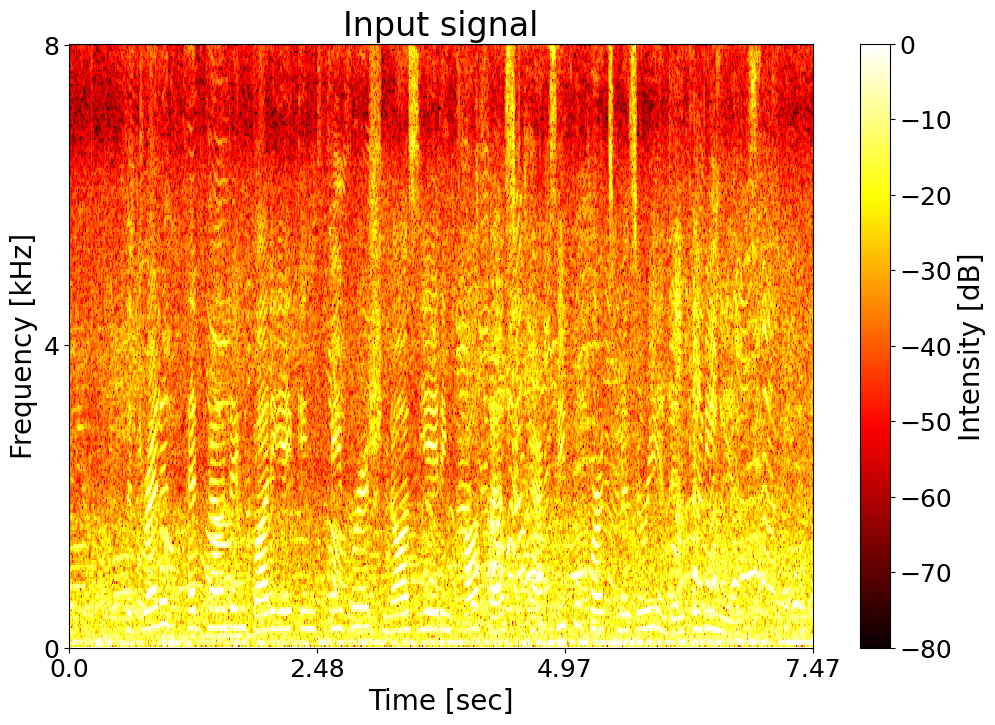 |
Clean speech 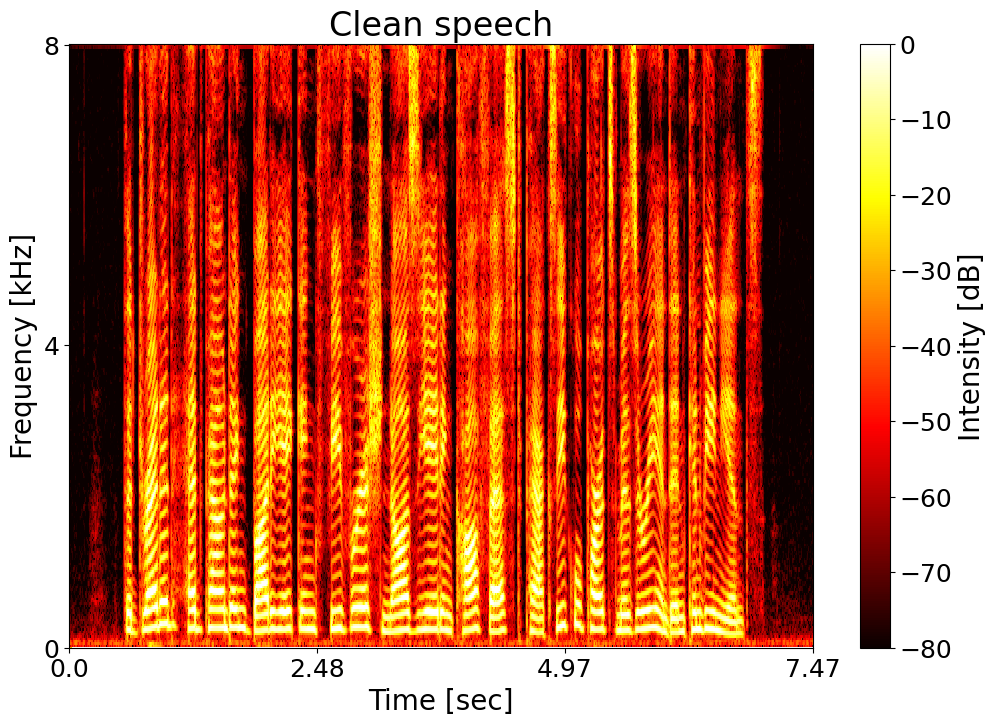 |
Target SNRi = 3.0 dB 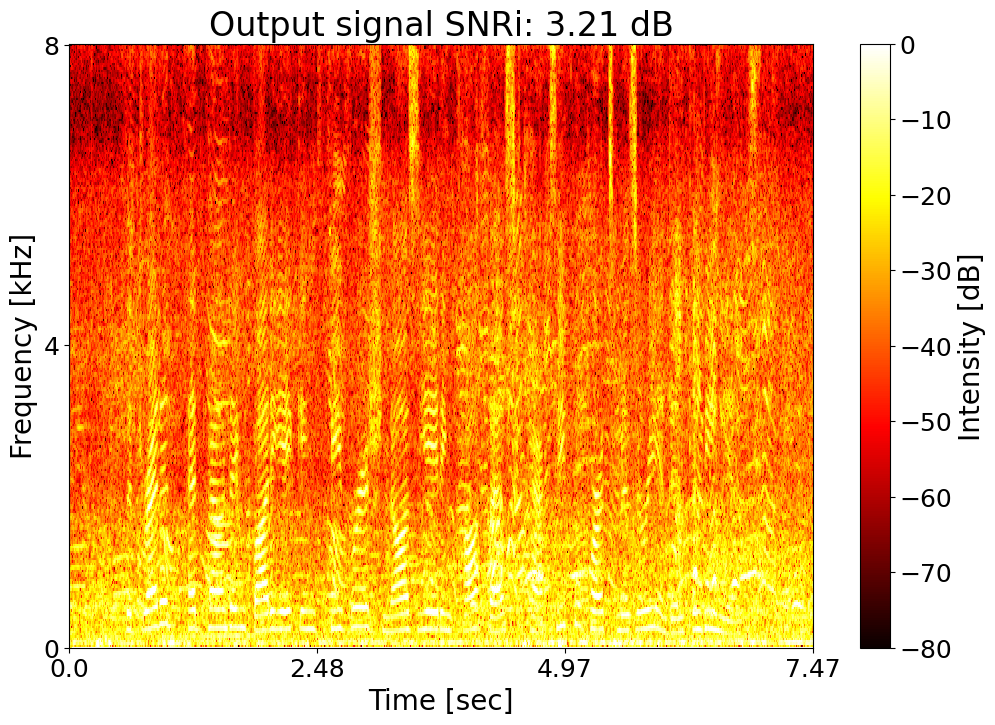 |
Target SNRi = 6.0 dB  |
Target SNRi = 9.0 dB 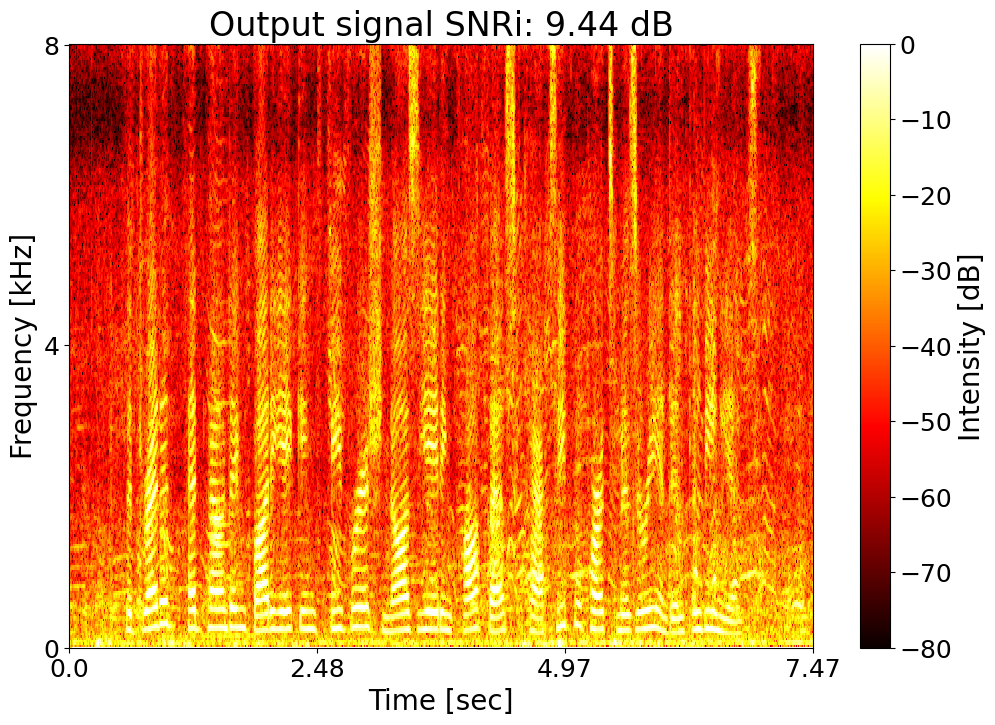 |
Target SNRi = 12.0 dB 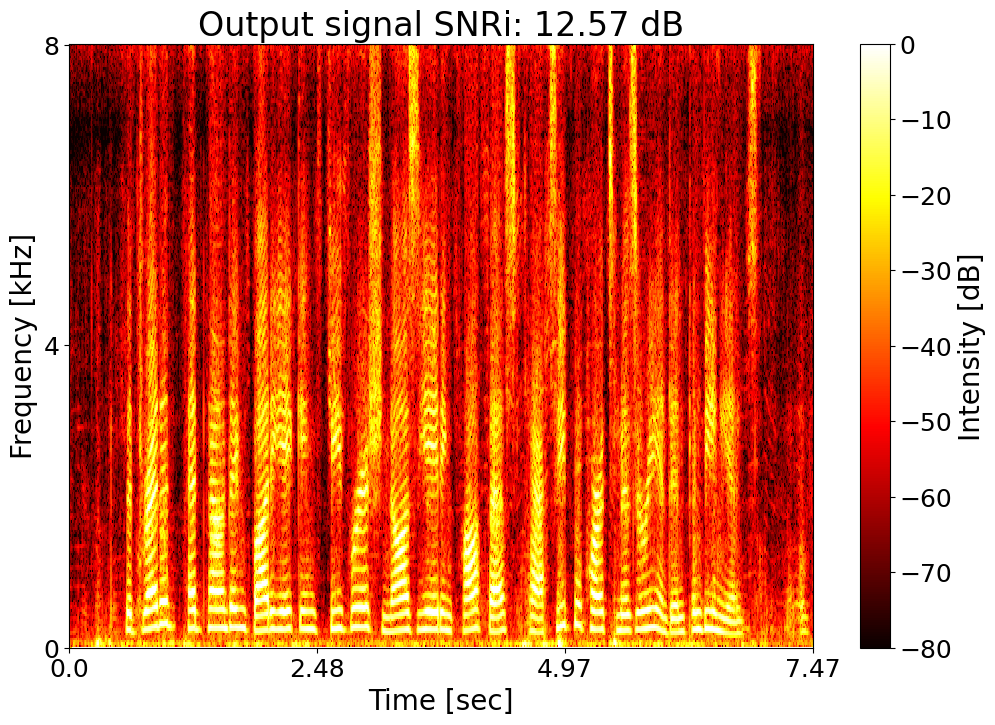 |
Example 3
Text: There are many talented actors in the world. Noisy input 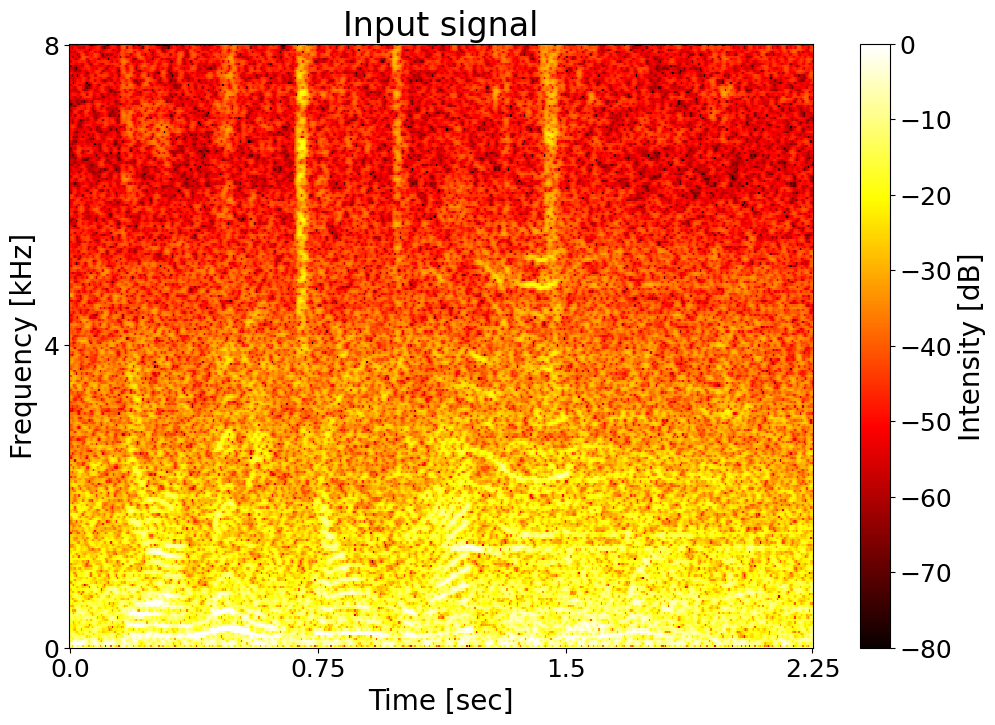 |
Clean speech 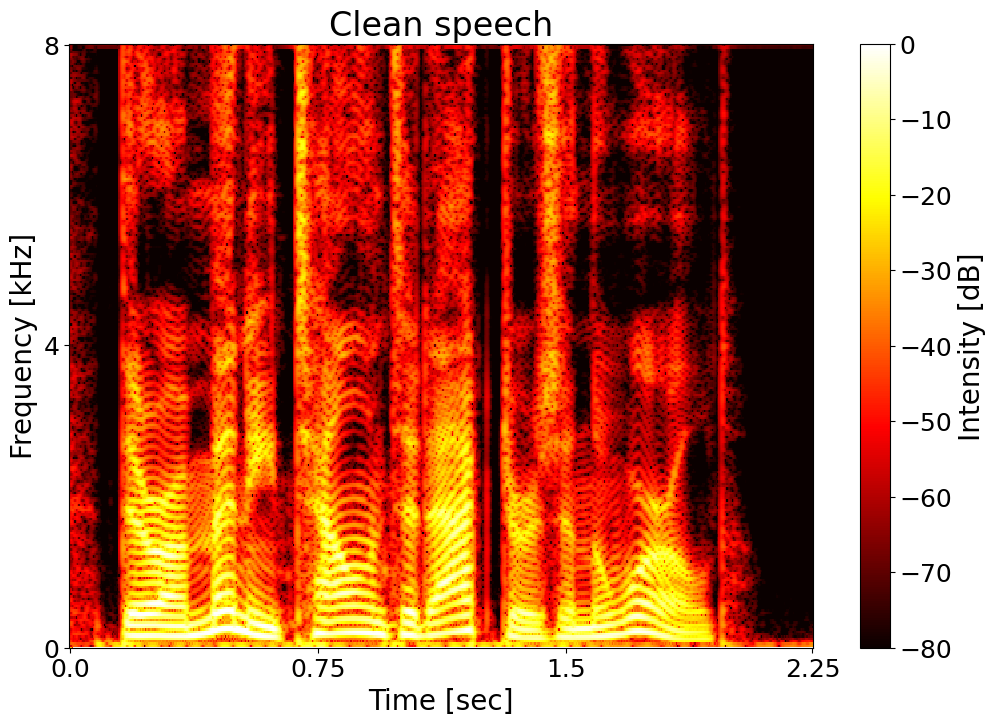 |
Target SNRi = 3.0 dB 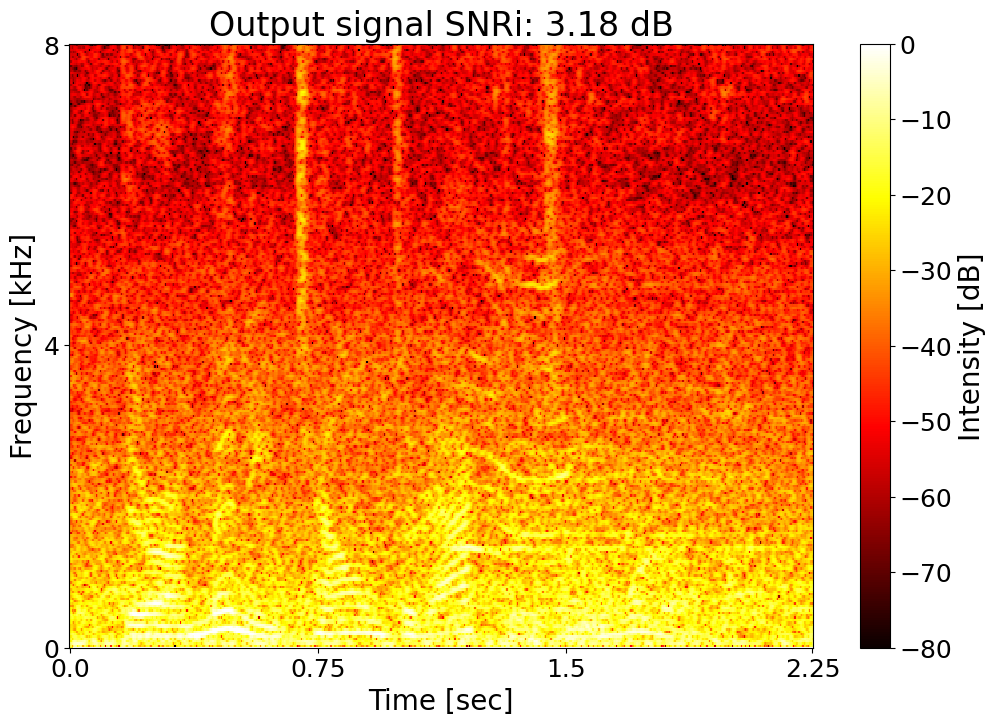 |
Target SNRi = 6.0 dB 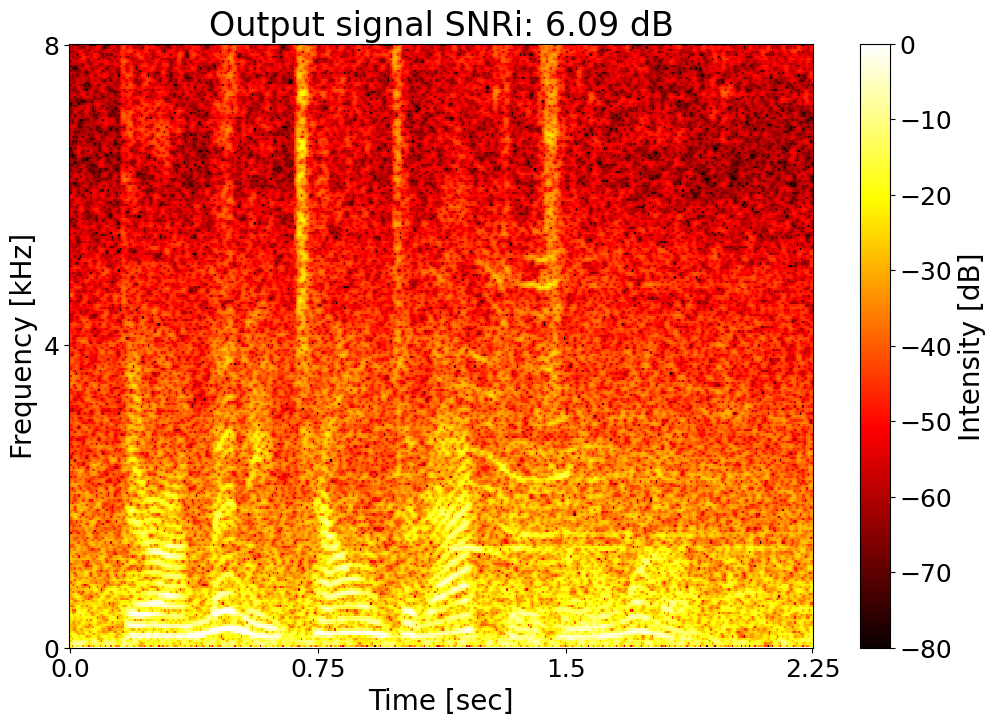 |
Target SNRi = 9.0 dB 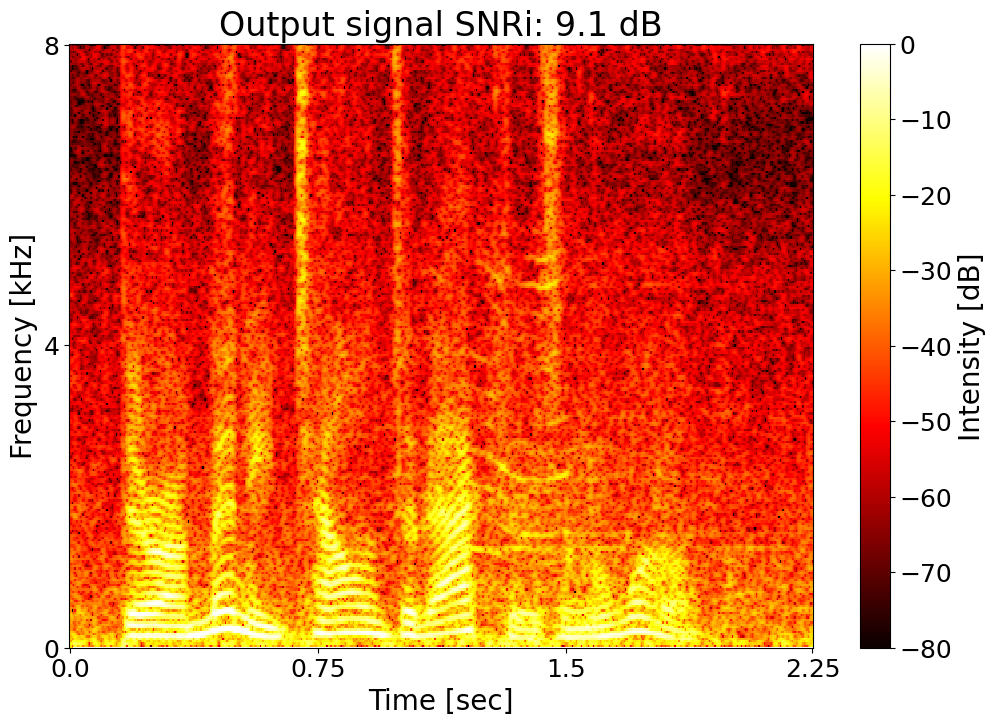 |
Target SNRi = 12.0 dB 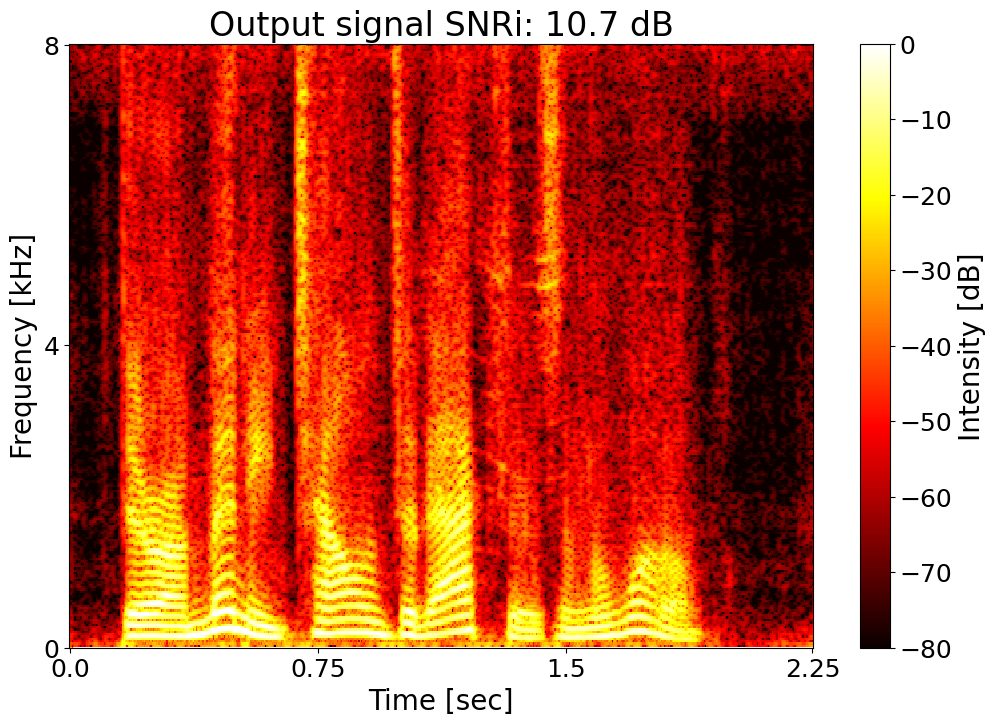 |
Example 4
Text: Aromatherapy. The use of aromatic plant extracts and essential oils in massage or baths. Noisy input 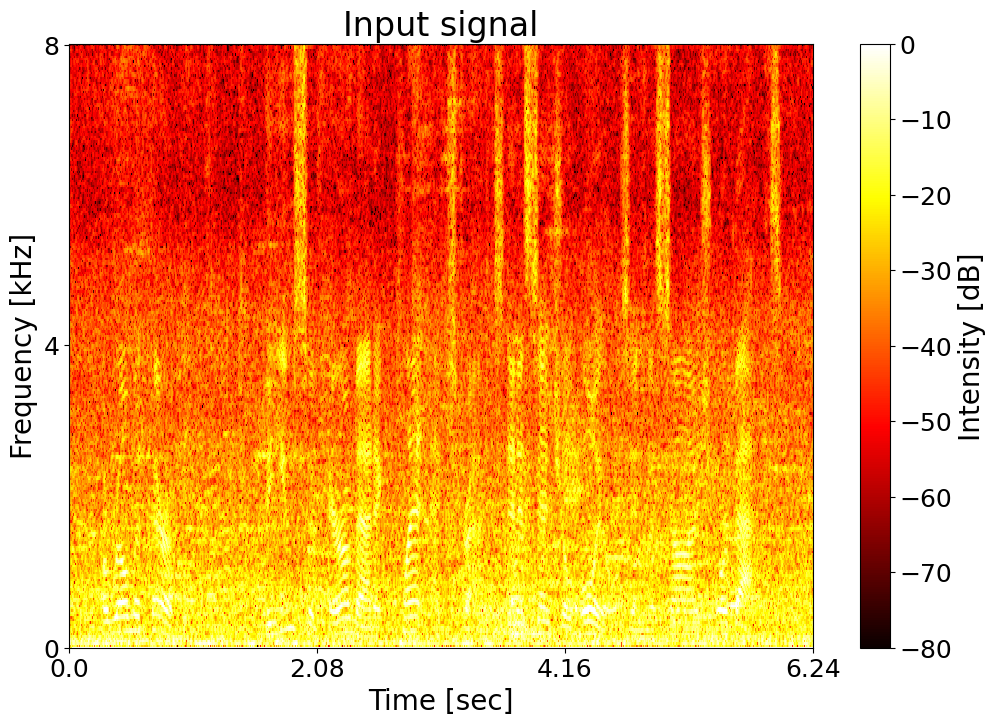 |
Clean speech 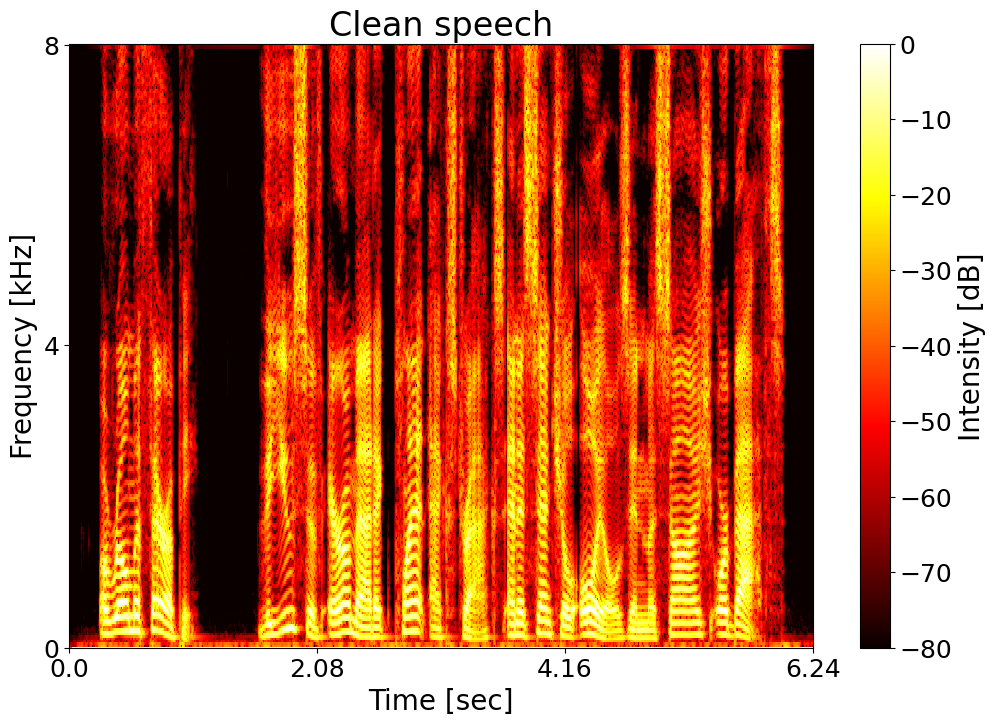 |
Target SNRi = 3.0 dB 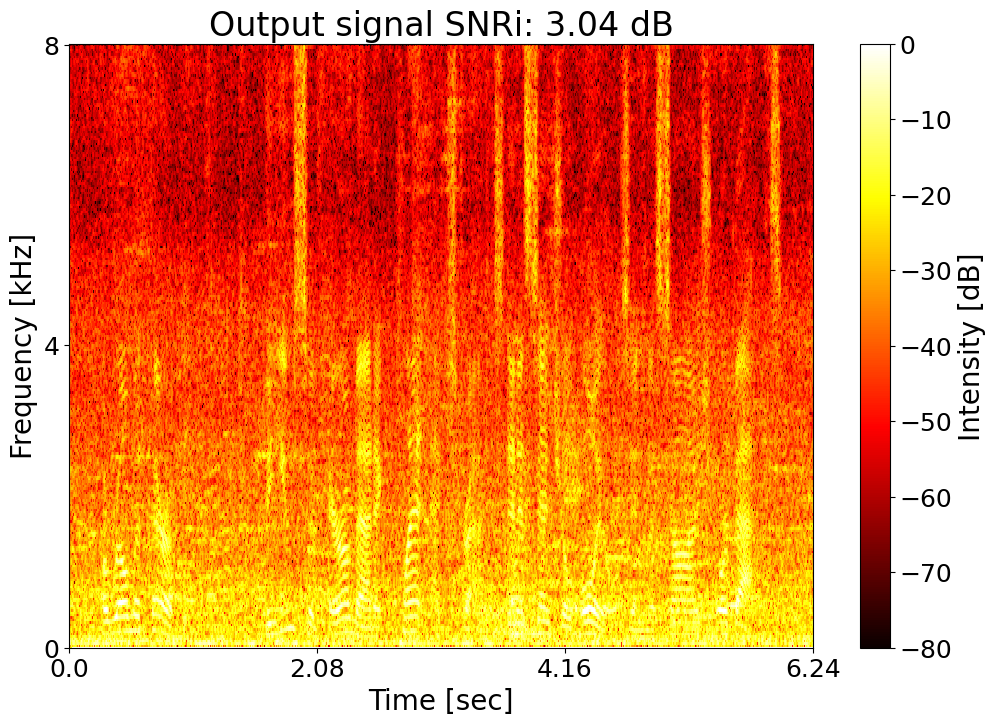 |
Target SNRi = 6.0 dB 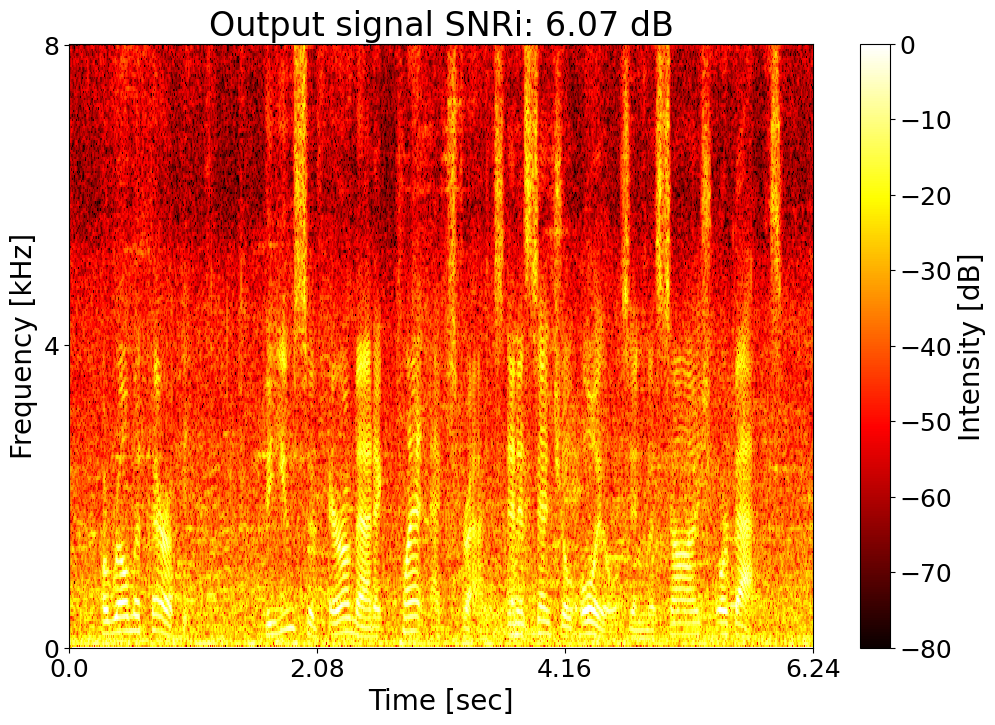 |
Target SNRi = 9.0 dB 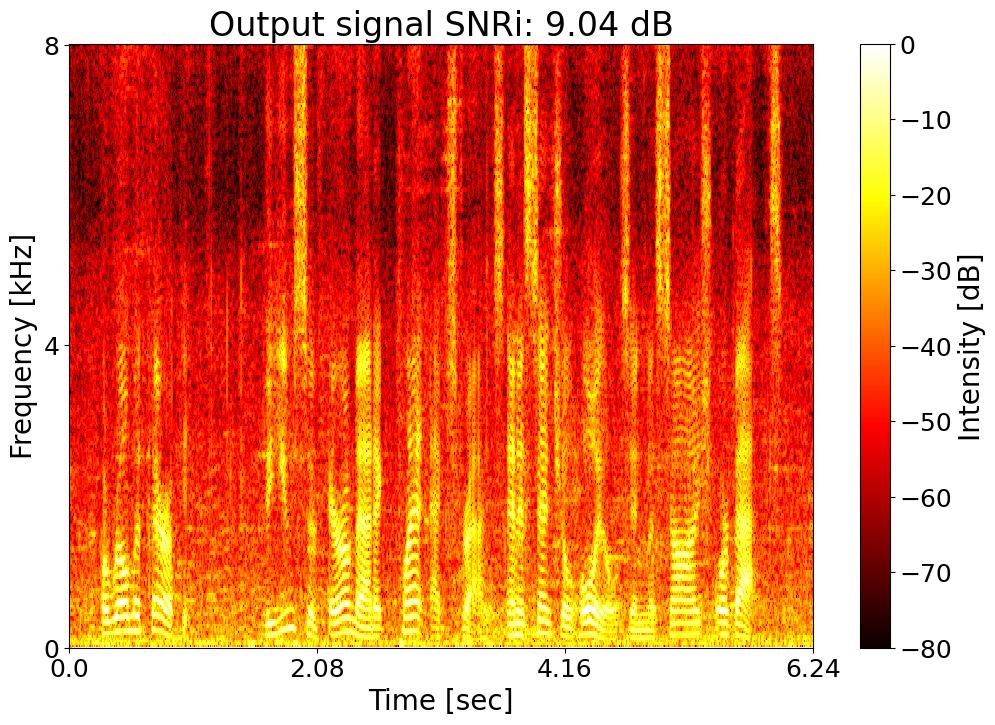 |
Target SNRi = 12.0 dB 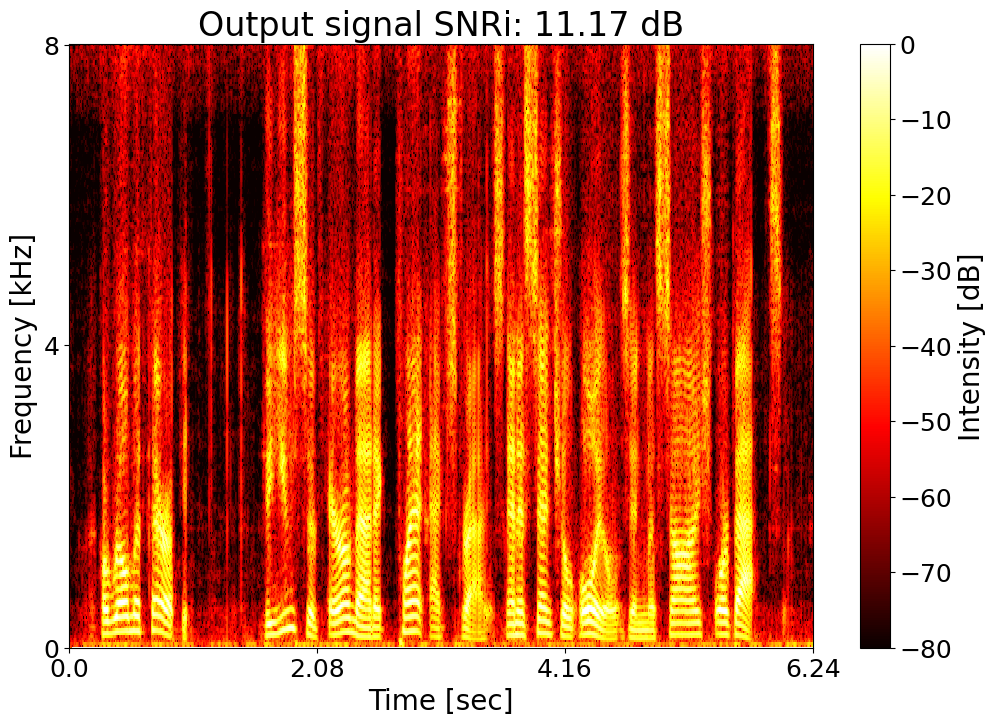 |
Example 5
Text: Nine hundred kilowatts times twenty four is a lot of watts. Noisy input 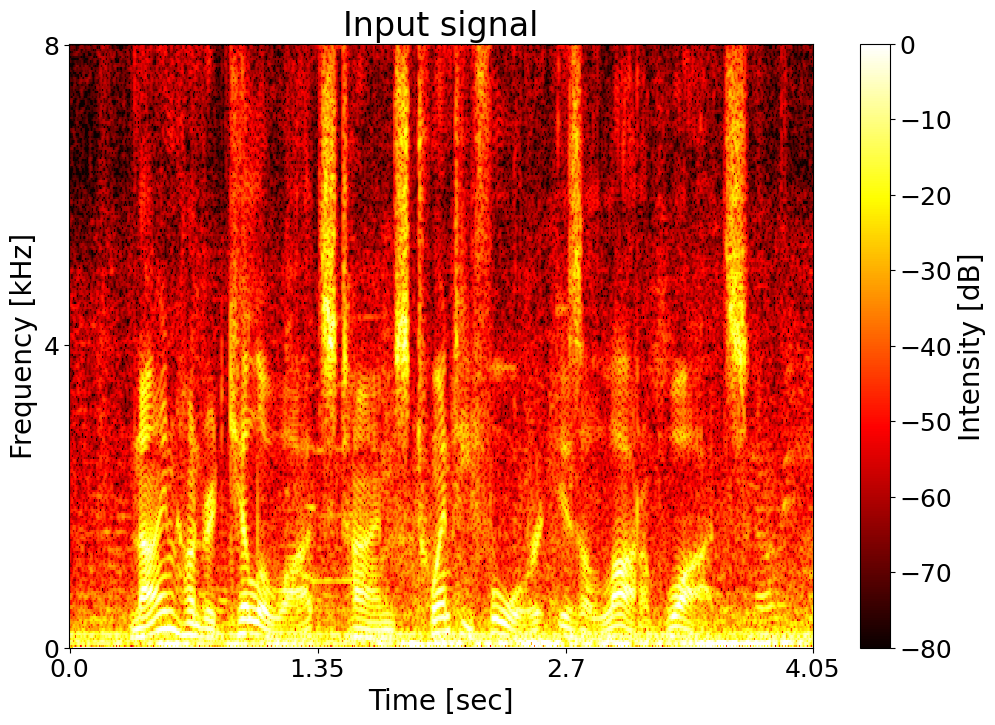 |
Clean speech 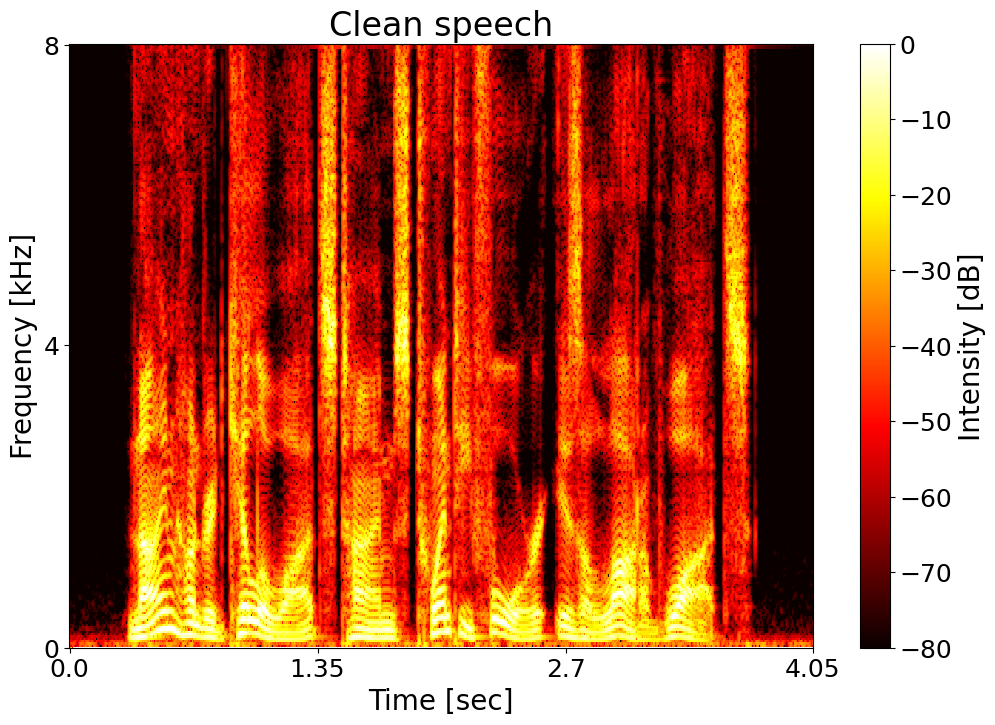 |
Target SNRi = 3.0 dB 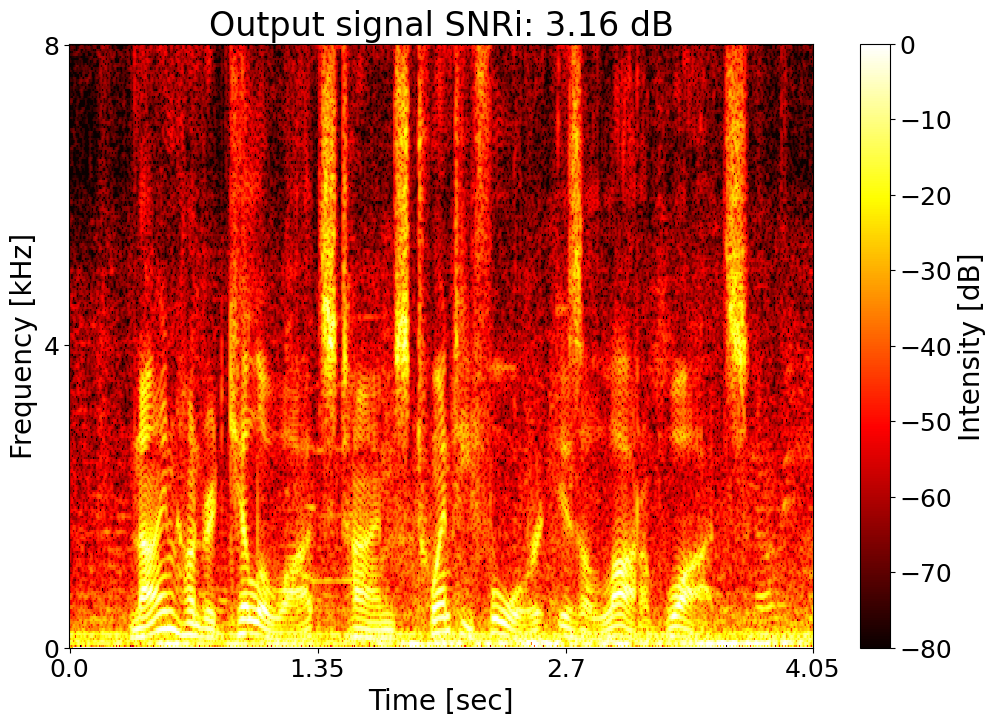 |
Target SNRi = 6.0 dB 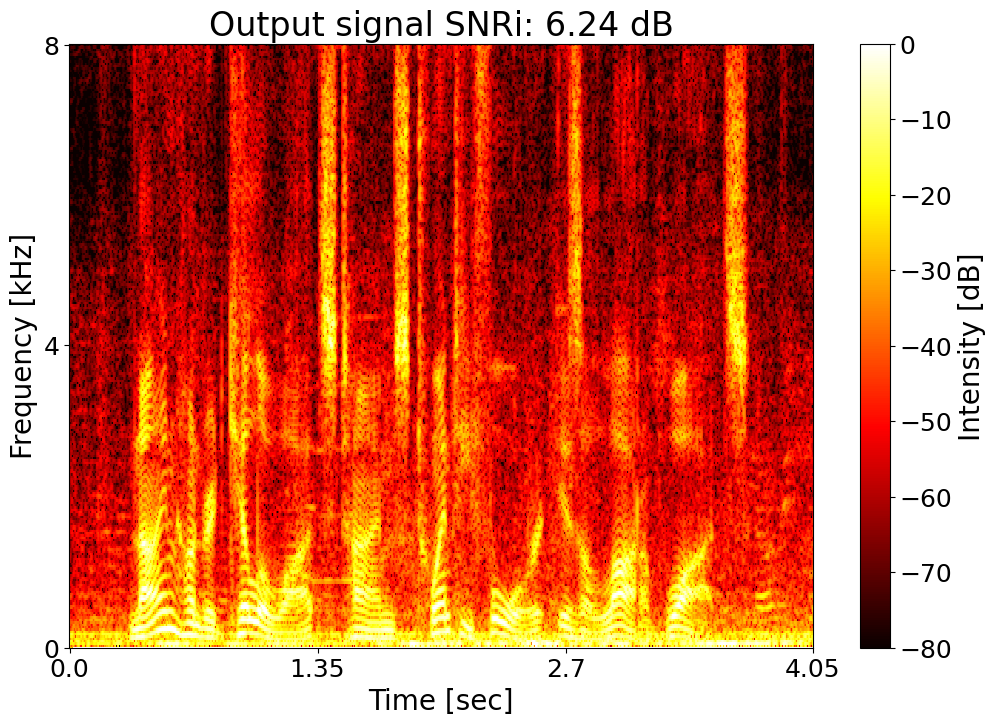 |
Target SNRi = 9.0 dB 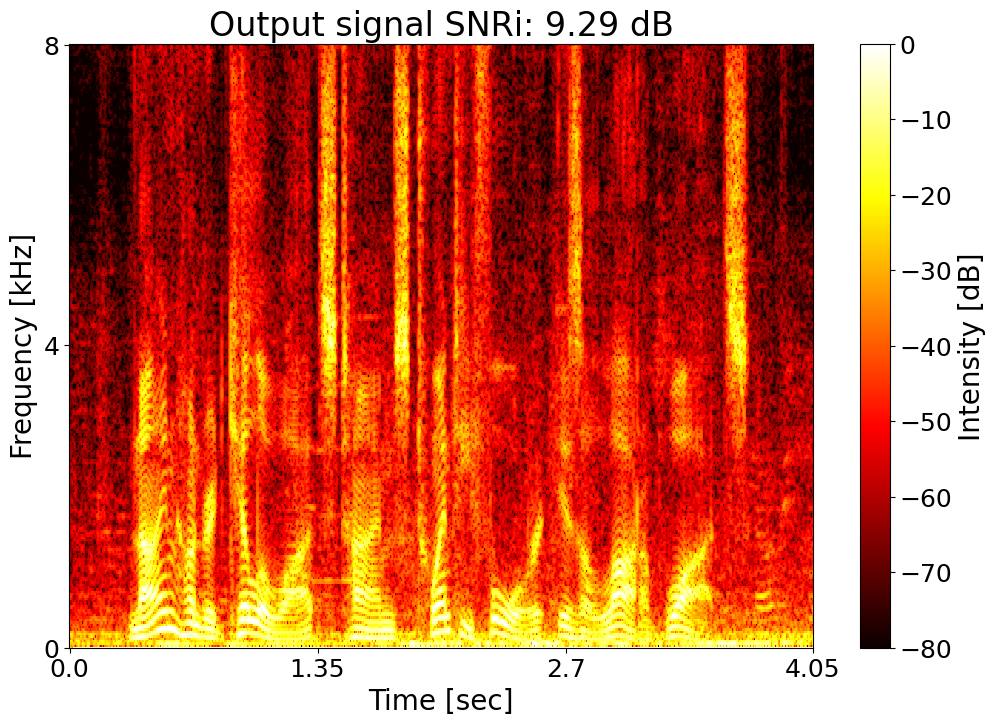 |
Target SNRi = 12.0 dB 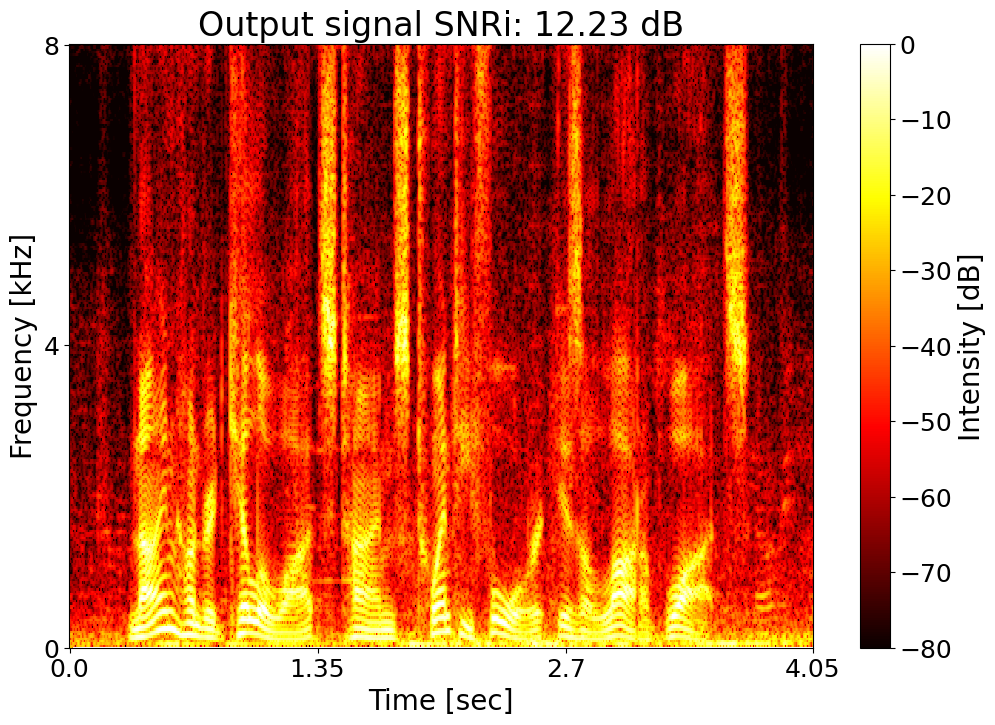 |
Output examples for joint SE-ASR training
Example 1Example 2
Example 3
Example 4
Example 5
Example 1
|
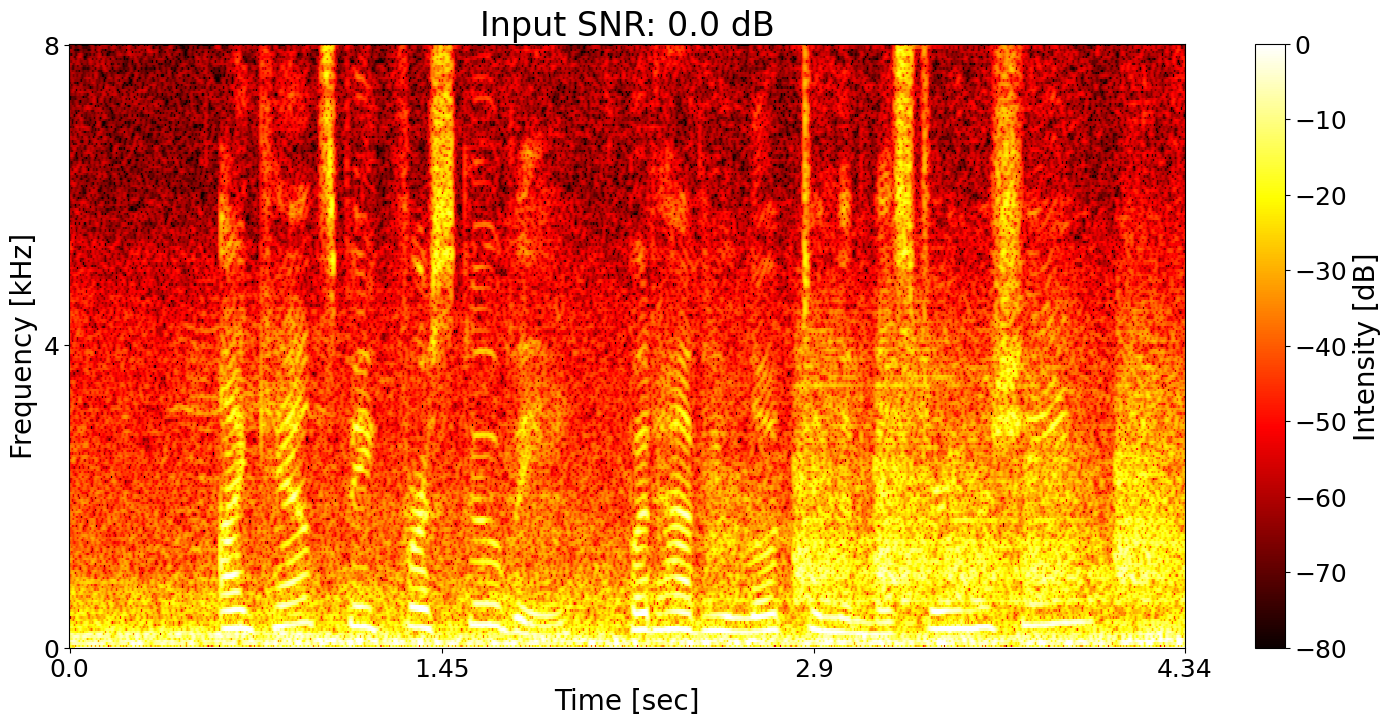
Noisy input Ground-truth transcript: I can't speak for Scooby, but have you looked in the Mystery Machine?
|
|
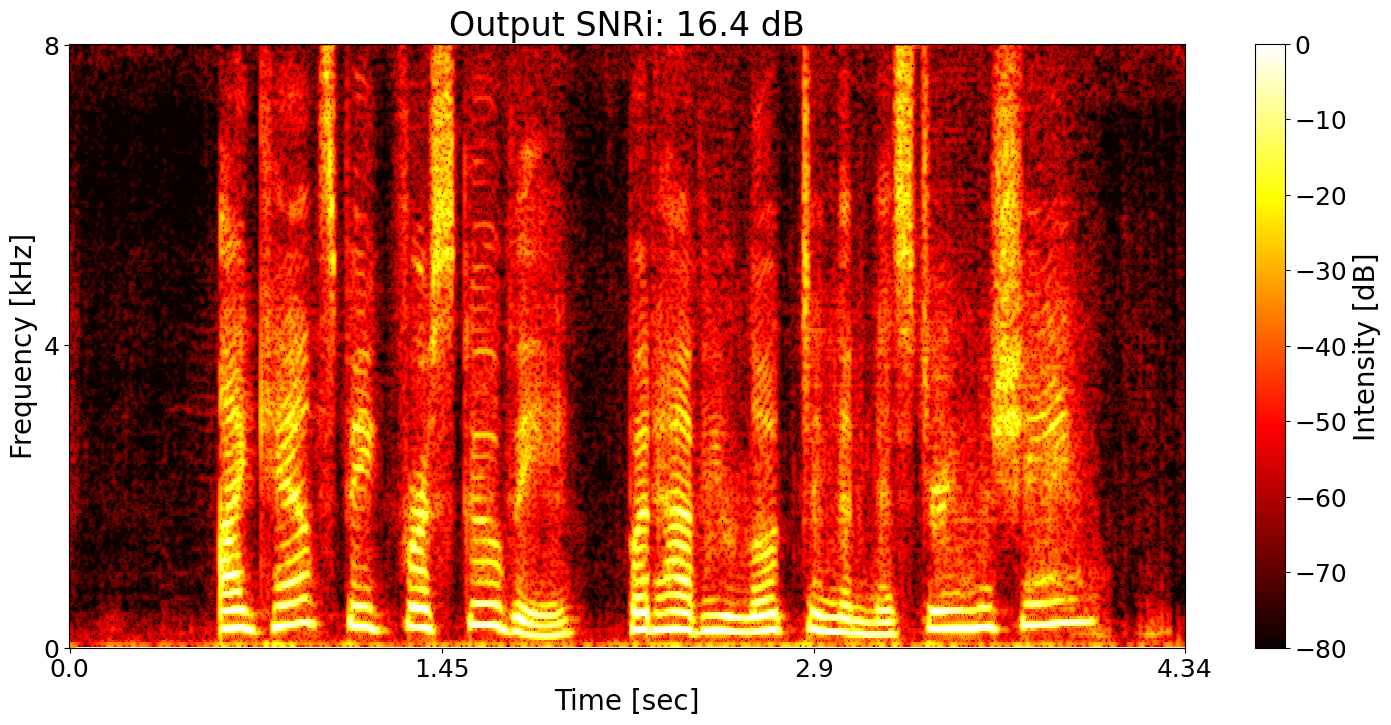
Conventional SE + ASR joint training Predicted transcript: I can't speak for Scooby but have you looked in the Mystery Machine
|
|
SNRi target training + ASR joint training Predicted transcript: I can't speak for Scooby but have you looked in the Mystery Machine
|
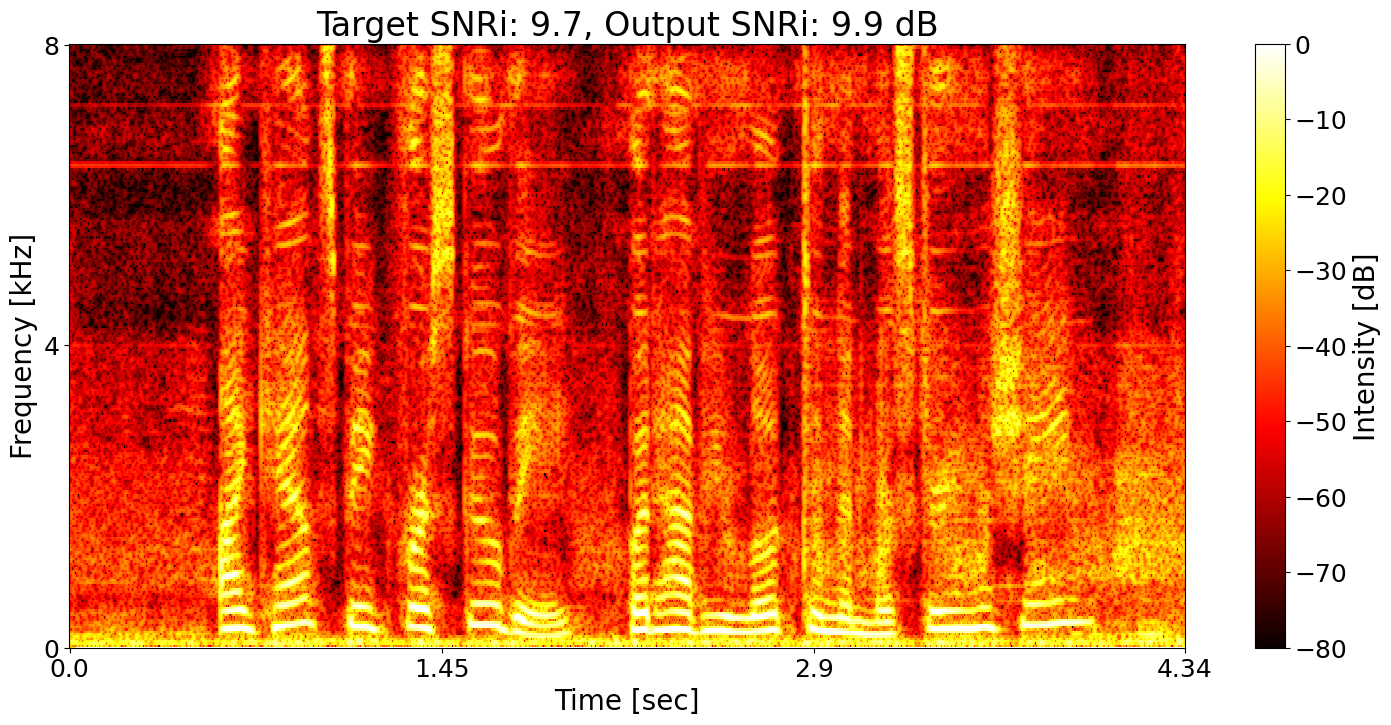
Example 2
|
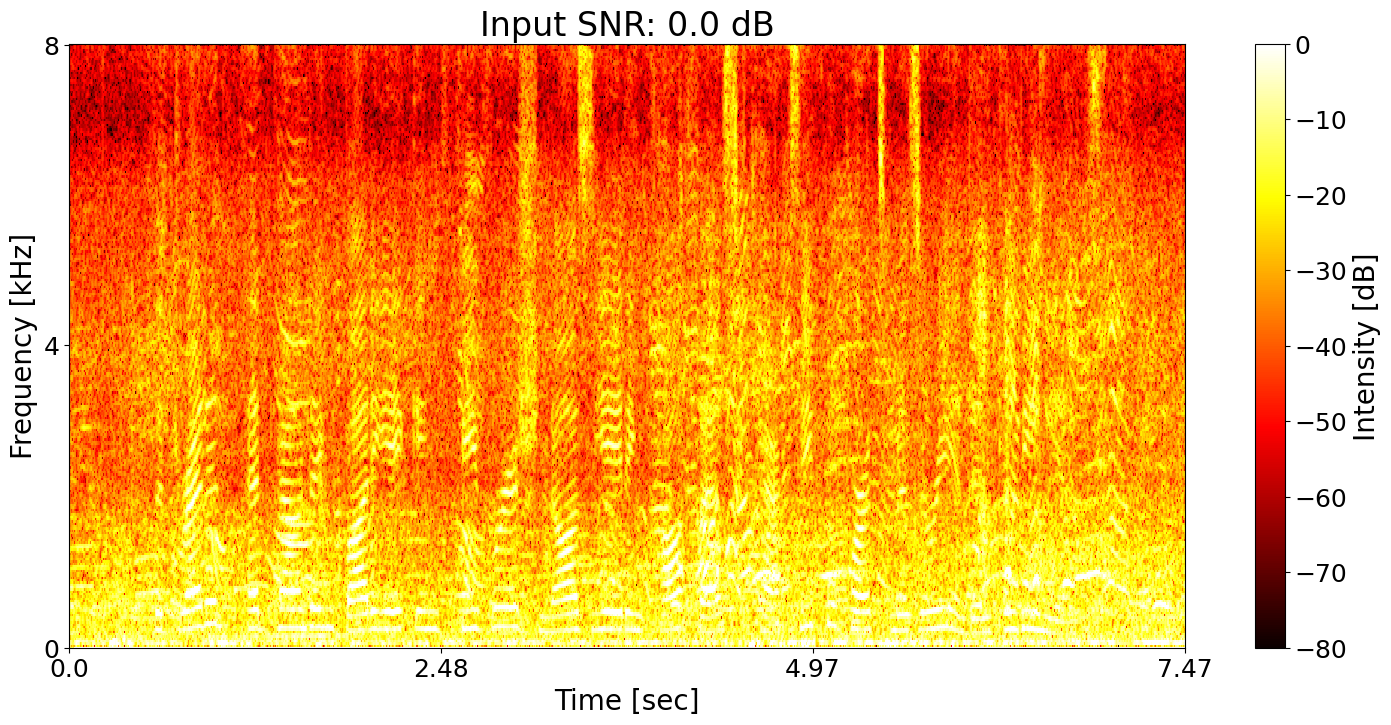
Noisy input Ground-truth transcript: The dreaded, head pounding, body aching, feverish, nauseating, cough fest packs equal parts misery and inconvenience.
|
|
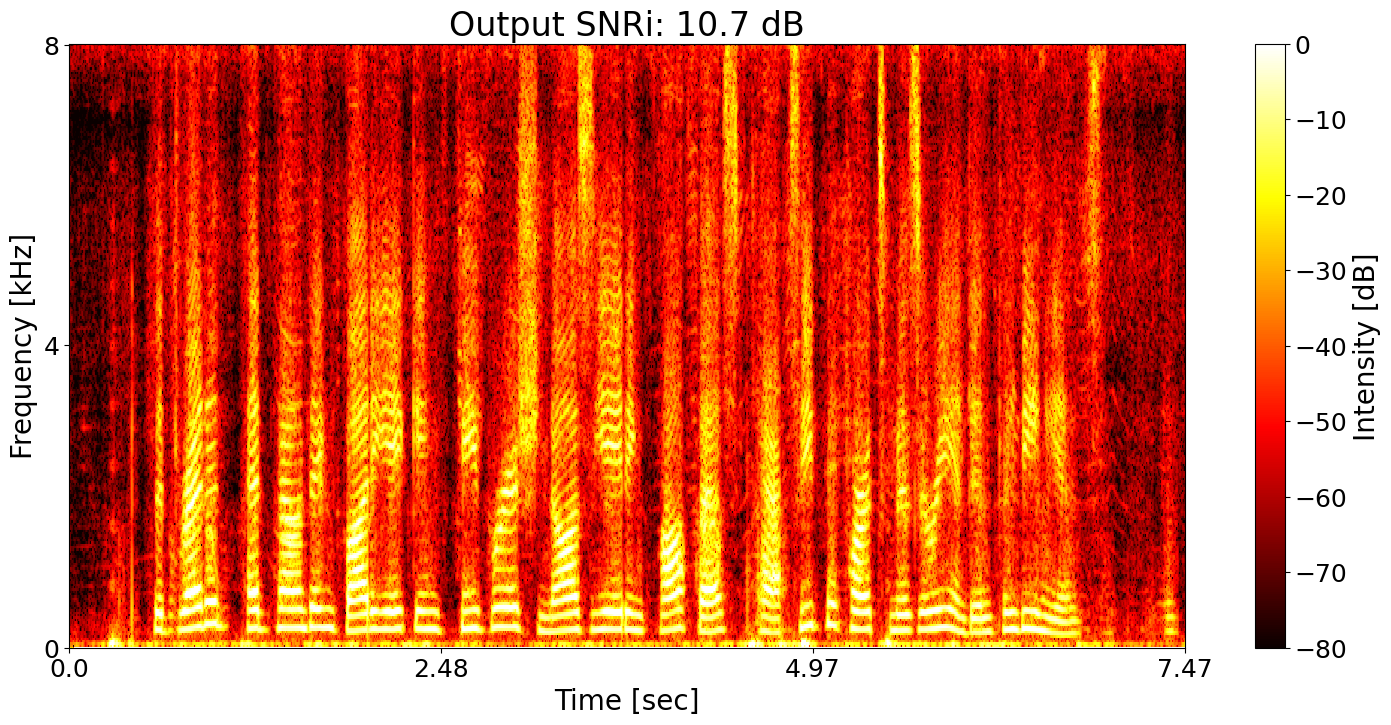
Conventional SE + ASR joint training Predicted transcript: The dreaded head founding bodying feverish nosiating confess perhaps equal parts misery and inconvenience.
|
|
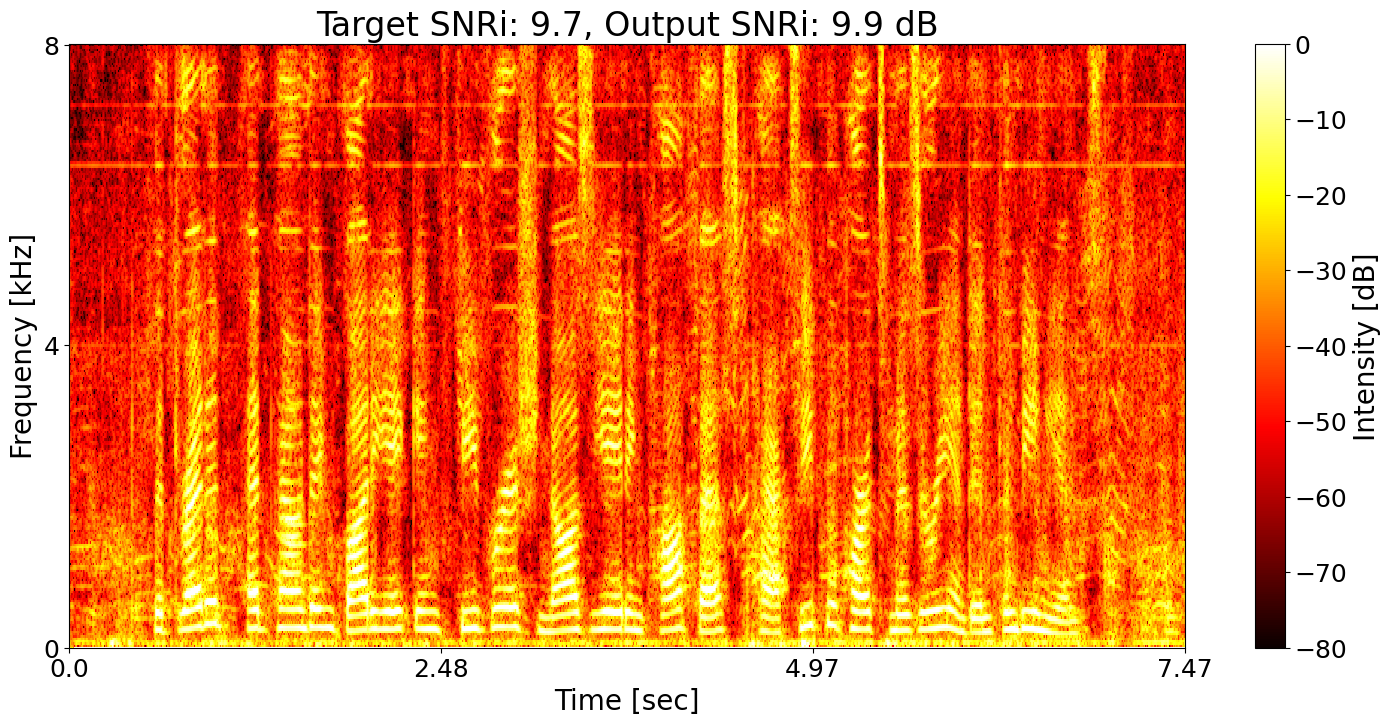
SNRi target training + ASR joint training Predicted transcript: The dreaded head founding body aching feverish nauseating confess taxi pro parts misery and inconvenience
|
Example 3
|
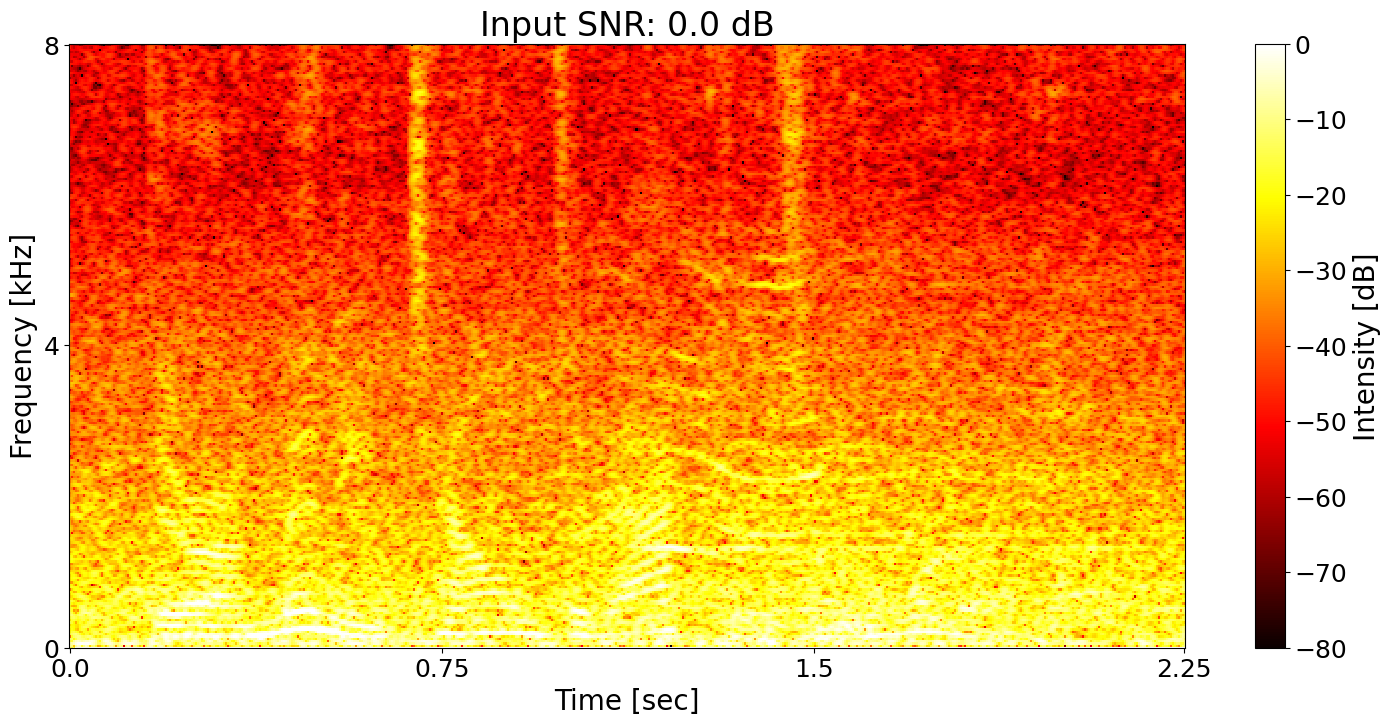
Noisy input Ground-truth transcript: There are many talented actors in the world.
|
|
Conventional SE + ASR joint training Predicted transcript: There are many town to the actors in the world.
|
|
SNRi target training + ASR joint training Predicted transcript: There are many talented actors in the world.
|
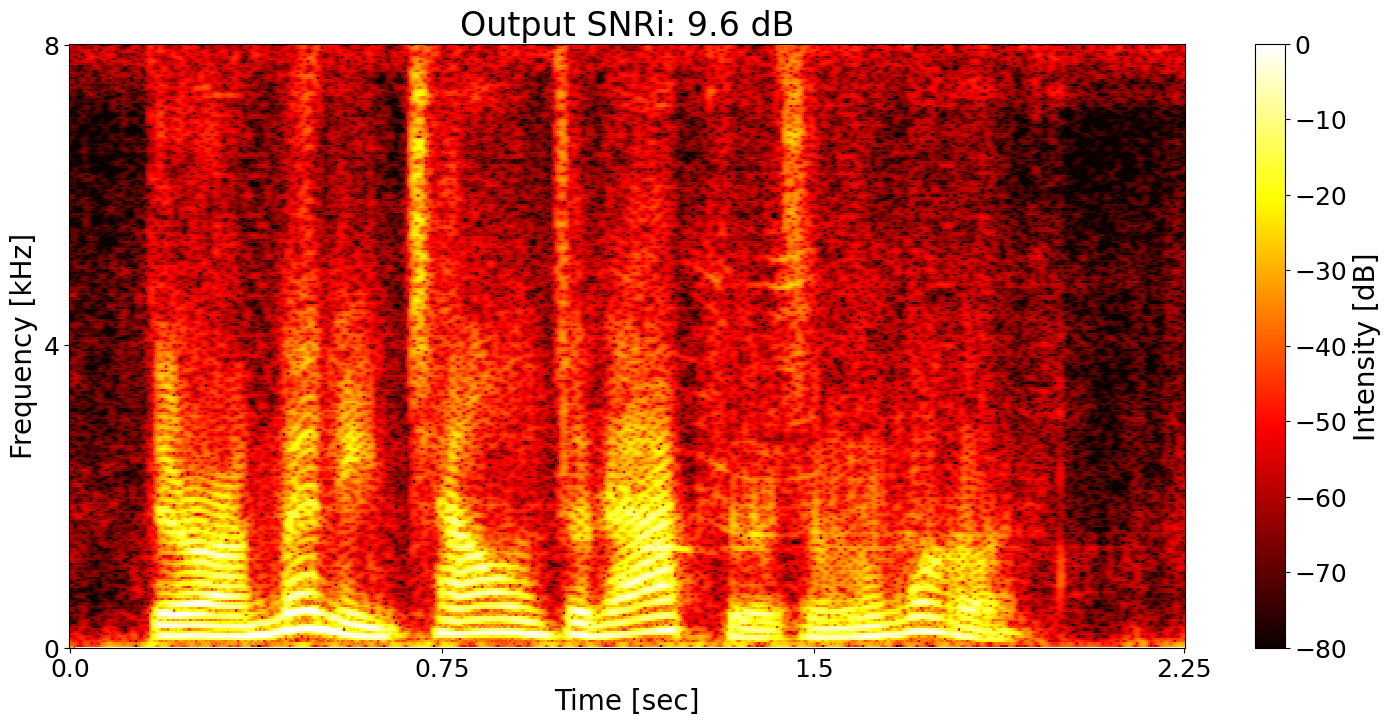
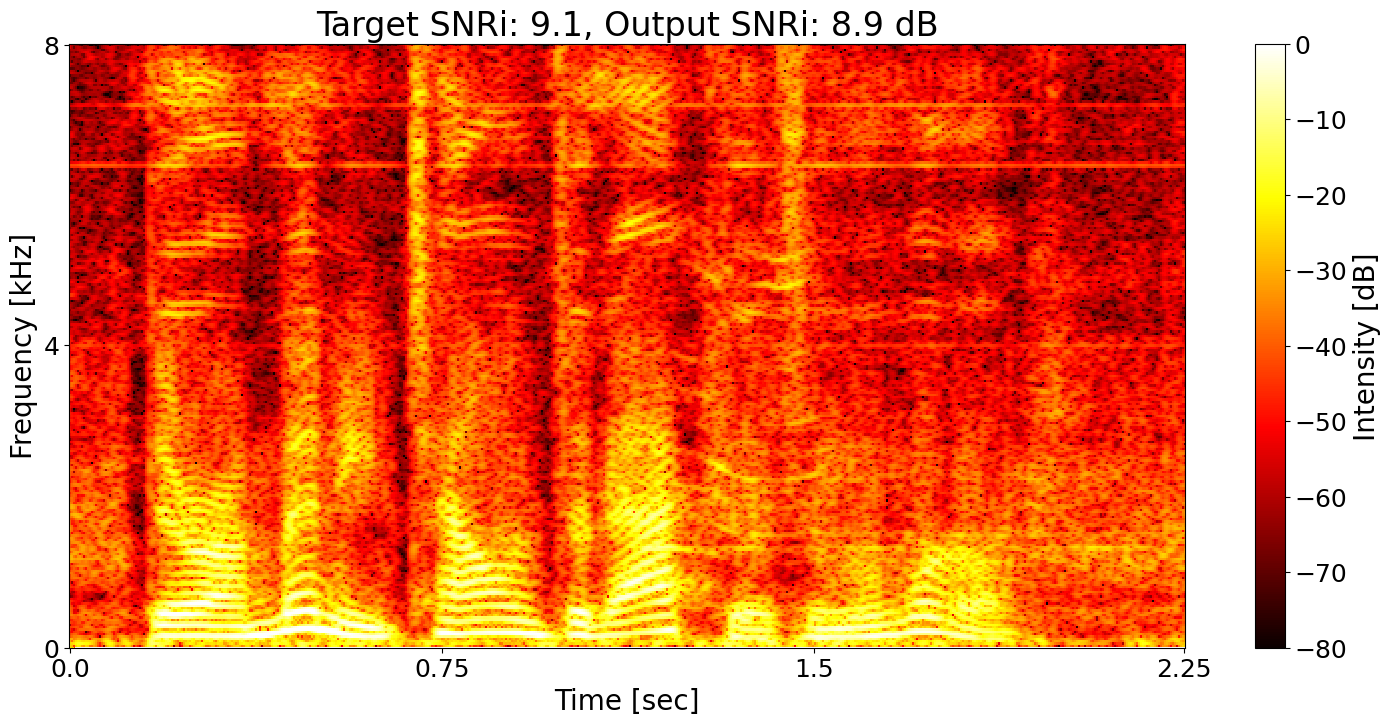
Example 4
|
Noisy input Ground-truth transcript: Aromatherapy. The use of aromatic plant extracts and essential oils in massage or baths.
|
|
Conventional SE + ASR joint training Predicted transcript: A Roman therapy the use of aramatic plant extracts and essential loyals in massage or backs.
|
|
SNRi target training + ASR joint training Predicted transcript: A Rome therapy the use of aromatic plant extracts and essential oils in massage or bats.
|
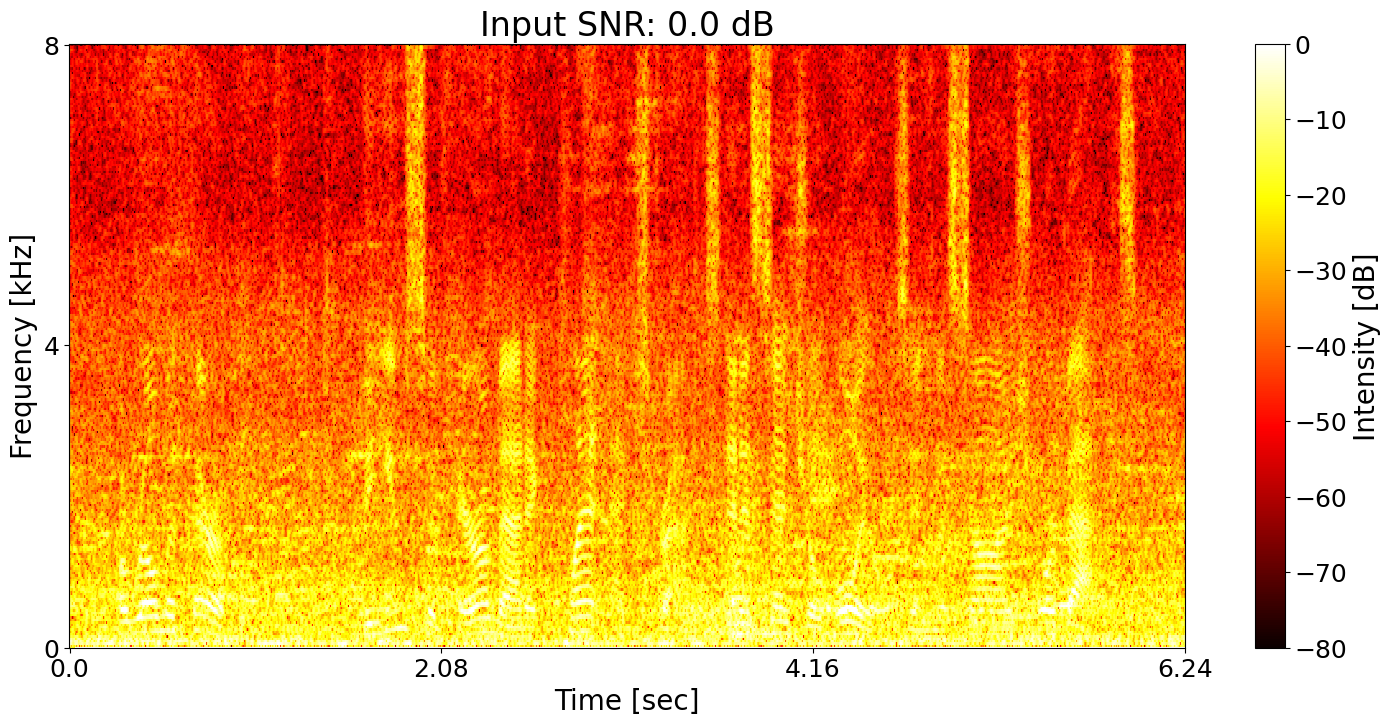
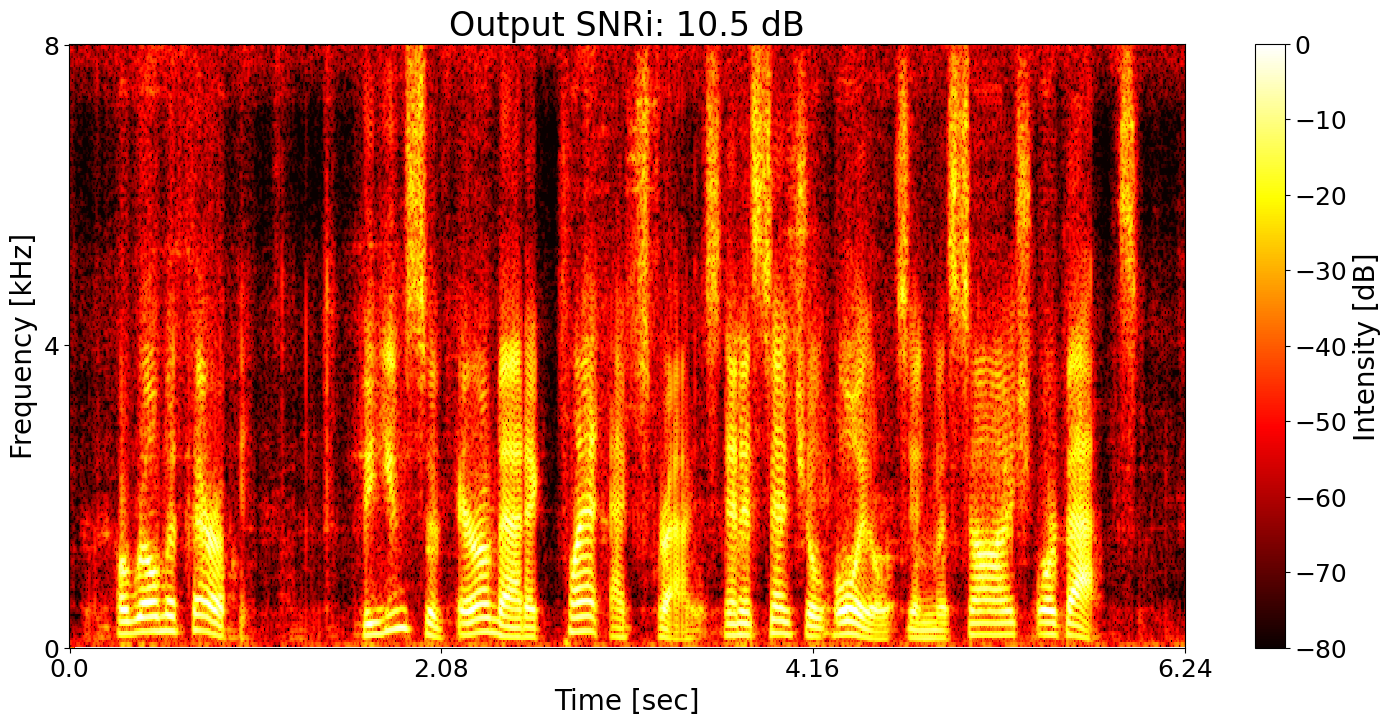
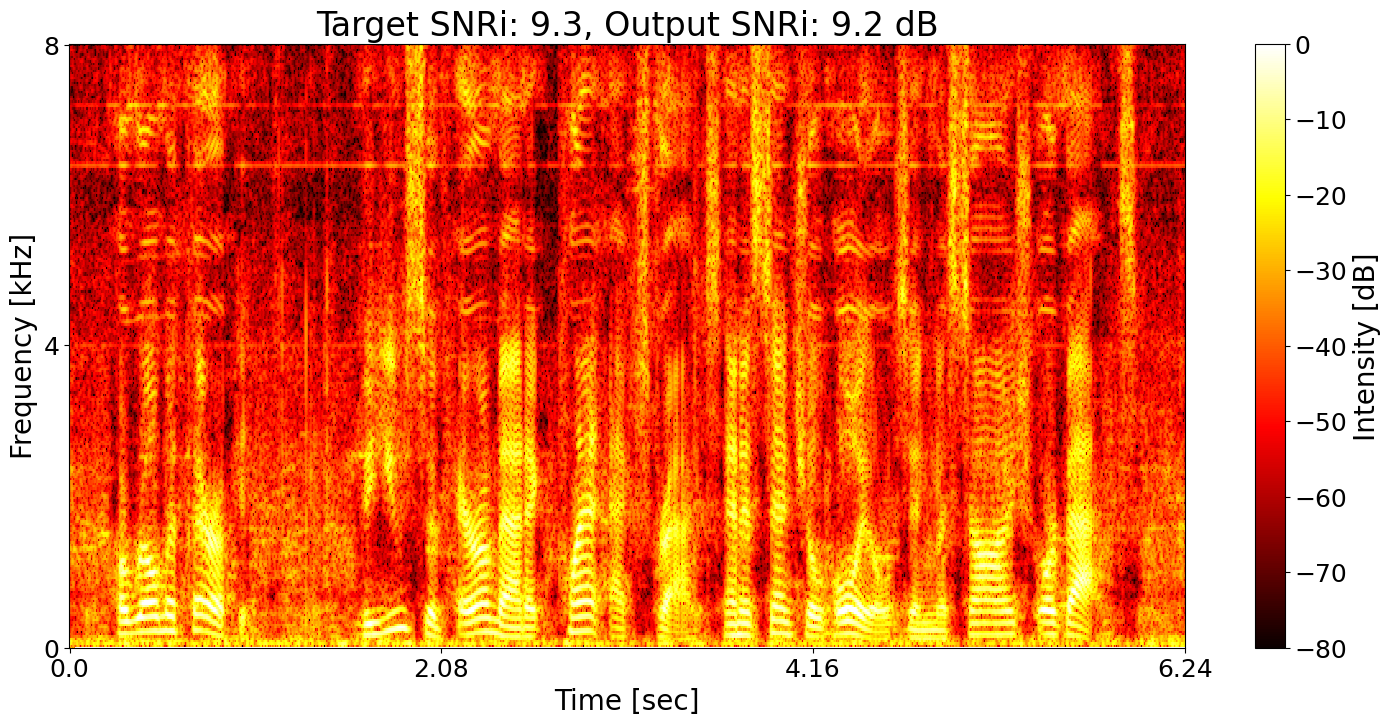
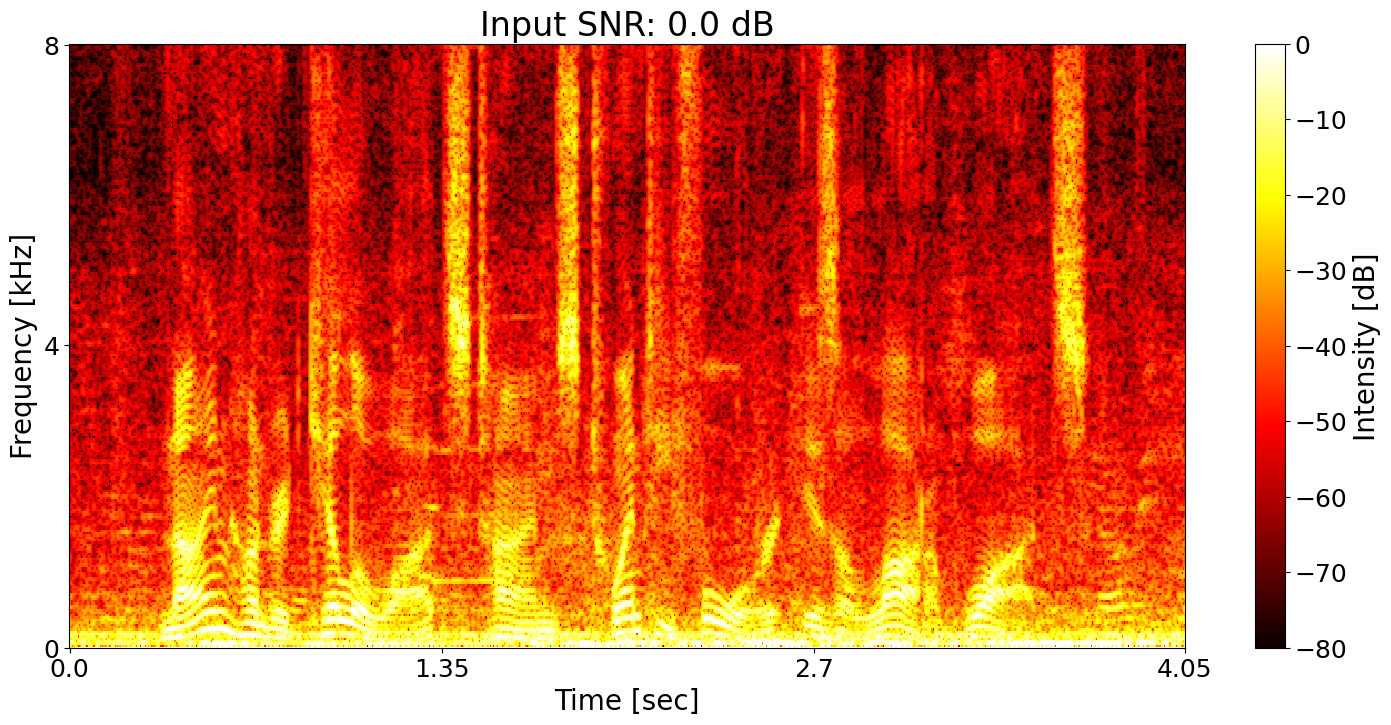
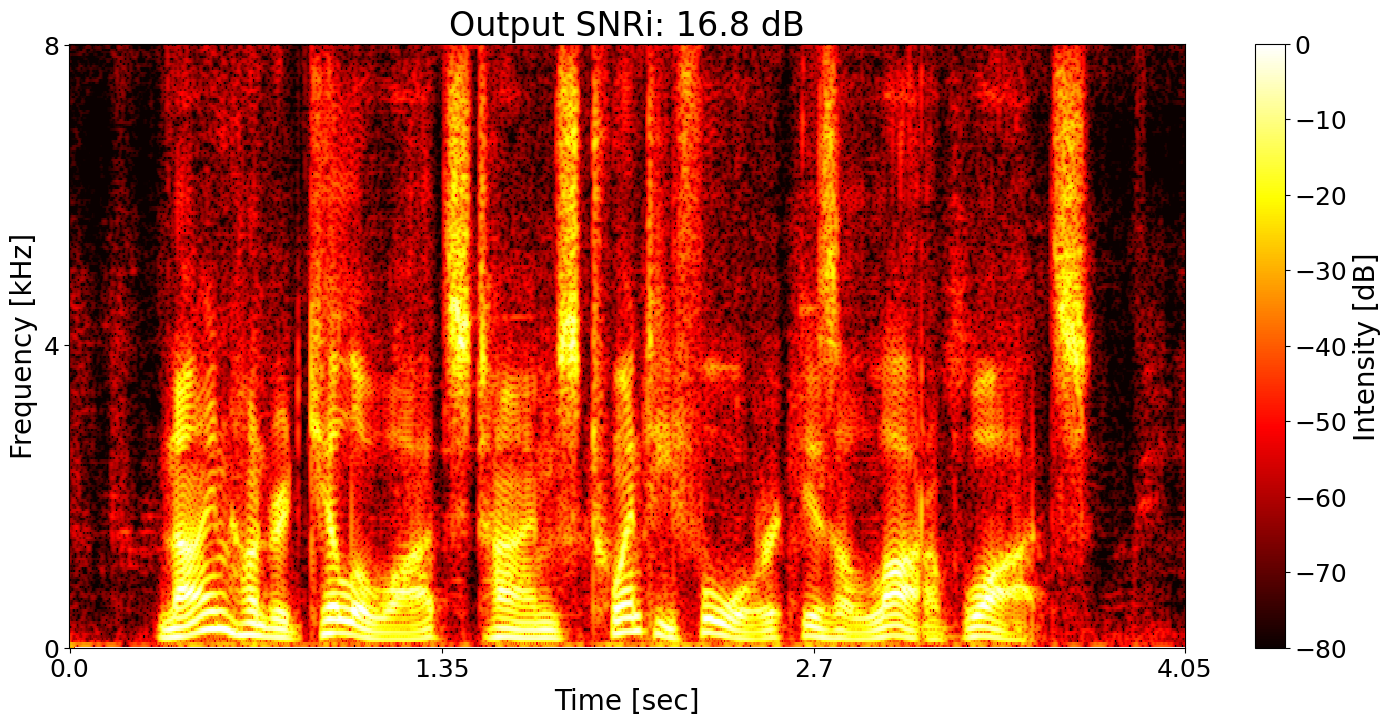
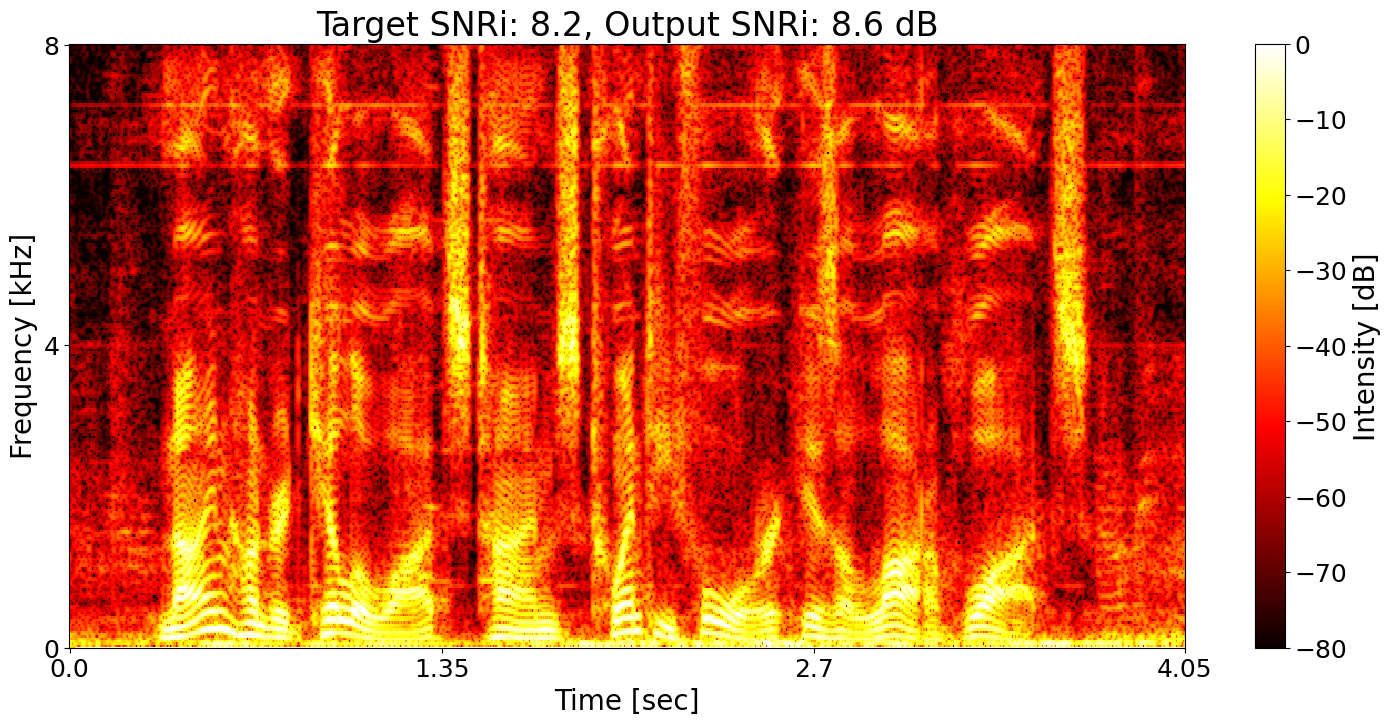
Example 5
|
Noisy input Ground-truth transcript: Nine hundred kilowatts times twenty four is a lot of watts.
|
|
Conventional SE + ASR joint training Predicted transcript: Nine hundred kilogs times twenty four is a lot of wots.
|
|
SNRi target training + ASR joint training Predicted transcript: Nine hundred kilogs times twenty four is a lot of watts.
|
References:
[1] N. Chen, Y. Zhang, H. Zen, R. J. Weiss, M. Norouzi, and W. Chan,“WaveGrad: Estimating gradients for waveform generation,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2021. [paper]
[2] S. Wang, A. Mesaros, T. Heittola, and T. Virtanen, “A curated dataset of urban scenes for audio-visual scene analysis,” in Proc. Int. Conf. on Acoust., Speech, and Signal Process. (ICASSP), 2021 [paper]