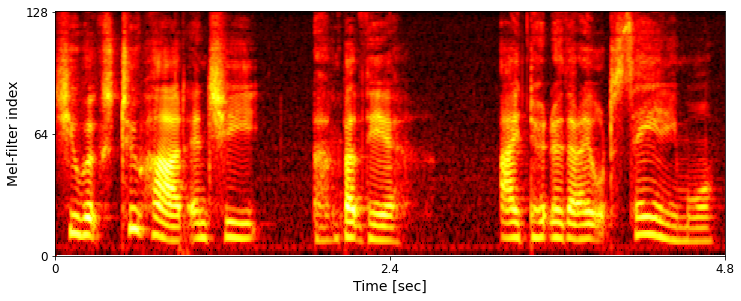
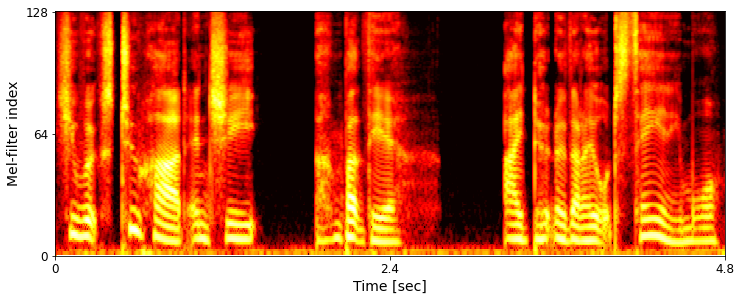
Abstract: This paper introduces a new speech dataset called "LibriTTS-R" designed for text-to-speech (TTS) use.
It is derived by applying speech restoration to the LibriTTS corpus, which consists of 585 hours of speech data at 24 kHz sampling rate from 2,456 speakers and the corresponding texts.
The constituent samples of LibriTTS-R are identical to those of LibriTTS, with only the sound quality improved.
Experimental results show that the LibriTTS-R ground-truth samples showed significantly improved sound quality compared to those in LibriTTS. In addition, neural end-to-end TTS trained with LibriTTS-R achieved speech naturalness on par with that of the ground-truth samples.
For more information, refer to the dataset paper: Y. Koizumi, et al., "LibriTTS-R: Restoration of a Large-Scale Multi-Speaker TTS Corpus", Interspeech 2023. If you use the LibriTTS-R corpus in your work, please cite the dataset paper where it was introduced.
Postscript (Sept. 4th, 2023):
We have published the list of file paths where speech restoration may have failed. Speech restoration is not always perfect, so some phonemes may be lost or changed during the restoration process. We ran automatic speech recognition (ASR) on all LibriTTS-R samples and created these lists of samples with a word error rate (WER) above a certain threshold. The experiments in the LibriTTS-R paper were conducted using these files that may have failed to be restored. However, the files included in these lists are likely to have uncorresponding transcripts and waveforms. Therefore, we recommend excluding them during model training. The list can be also download from
the OpenSLR dataset page.
UPDATED Aug 17 2023: We added TTS examples using OSS toolkits, see this new page.
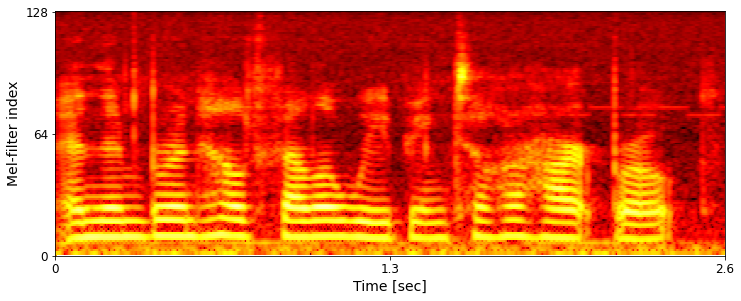
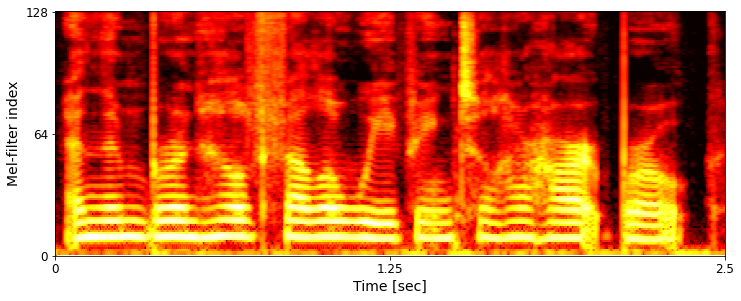
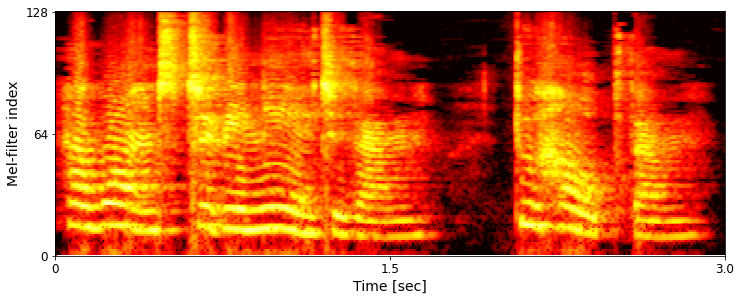
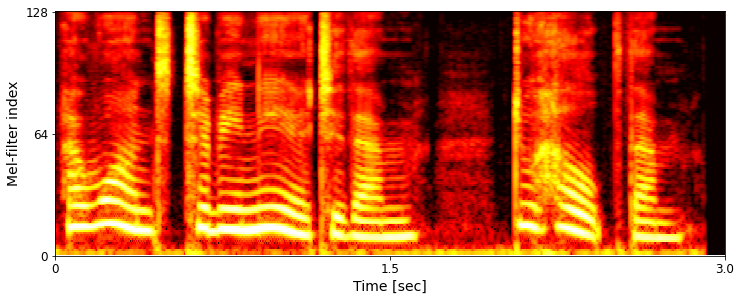
Ground-truth example comparison:
Example 1: And then Brynhild fell a-weeping till her heart broke.
LibriTTS
LibriTTS-R
Example 2: I want to be near to them--to help them.
LibriTTS
LibriTTS-R
Example 3: Guess I'll have to stick to selling meals, mostly--for a while, at least.
LibriTTS
LibriTTS-R
Example 4: I should so like one to hang in my morning-room at Jocelyn's Rock.
LibriTTS
LibriTTS-R
Example 5: She works too hard, and she---- But there, I don't know that I ought to say any more.
LibriTTS
LibriTTS-R
TTS generated speech comparison:
This section shows output examples of multi-speaker TTS models trained on either LibriTTS or LibriTTS-R. The TTS model consists of a duration unsupervised non-attentive Tacotron (NAT) [1] acoustic model and a WaveRNN neural vocoder [2]. All models were trained with the same model size, hyper-parameters, and training steps. The TTS model was trained on two types of training splits: Train-460 and Train-960. Train-460 consists of the "train-clean-100" and "train-clean-360'" subsets, and Train-960 indicates using "train-other-500" in addition to Train-460. For more details, please refer our paper.
Example1: The Edison construction department took entire charge of the installation of the plant, and the formal opening was attended on October 1, 1883, by Mr. Edison, who then remained a week in ceaseless study and consultation over the conditions developed by this initial three-wire underground plant.
Speaker ID
LibriTTS Train460
LibriTTS Train960
LibriTTS-R Train460
LibriTTS-R Train960
103
1841
1121
5717
Example2: Her sea going qualities were excellent, and would have amply sufficed for a circumnavigation of the globe.
Speaker ID
LibriTTS Train460
LibriTTS Train960
LibriTTS-R Train460
LibriTTS-R Train960
103
1841
1121
5717
Example3: Therefore her Majesty paid no attention to anyone and no one paid any attention to her.
Speaker ID
LibriTTS Train460
LibriTTS Train960
LibriTTS-R Train460
LibriTTS-R Train960
103
1841
1121
5717
Example4: The Free State Hotel served as barracks.
Speaker ID
LibriTTS Train460
LibriTTS Train960
LibriTTS-R Train460
LibriTTS-R Train960
103
1841
1121
5717
Example5: The military force, partly rabble, partly organized, had meanwhile moved into the town.
Speaker ID
LibriTTS Train460
LibriTTS Train960
LibriTTS-R Train460
LibriTTS-R Train960
103
1841
1121
5717
Acknowledgement:
We appreciate valuable feedback and support from
Daniel S. Park,
Hakan Erdogan,
Haruko Ishikawa,
Hynek Hermansky
Johan Schalkwyk,
John R. Hershey,
Keisuke Kinoshita,
Llion Jones,
Neil Zeghidour,
Quan Wang,
Richard William Sproat,
Ron Weiss,
Shiori Yamashita,
Yotaro Kubo, and
Victor Ungureanu.
References:
[1] J. Shen, Y. Jia, M. Chrzanowski, Y. Zhang, I. Elias, H. Zen and Y. Wu, "Non-Attentive Tacotron: Robust and Controllable Neural TTS Synthesis Including Unsupervised Duration Modeling," arXiv:2010.04301, 2020.
[paper]
[2] N. Kalchbrenner, W. Elsen, K. Simonyan, S. Noury, N. Casagrande, W. Lockhart, F. Stimberg, A. van den Oord, S. Dieleman and K. Kavukcuoglu
"Efficient Neural Audio Synthesis," in Proc. ICML, 2018
[paper]