SURF: Separation via Unsupervised Remixing Flow
Abstract
The goal of single-channel source separation is to reconstruct K sources given their mixture. In supervised settings where vast amounts of clean source data are available, this challenging, ill-posed problem has been addressed successfully by generative diffusion and flow-based prior models. However, access to such clean source samples is often limited, and even when available, supervised models are vulnerable to domain shifts. To bridge this gap, we present Separation via Unsupervised Remixing Flow (SURF), an unsupervised flow matching approach for source separation that learns directly from observed mixtures. This method relies on a novel combination of state-of-the-art supervised flow matching and regression-based self-supervised techniques. At a high level, starting from a teacher model, we utilize a “remixing” step to bootstrap the learning of a student flow model from the teacher’s estimates. We provide insights into the objectives optimized by this approach and draw a novel connection to the Wake-Sleep algorithm. Empirical evaluations on image and audio benchmarks demonstrate that SURF establishes a new state-of-the-art, significantly outperforming existing unsupervised methods.
Method Overview
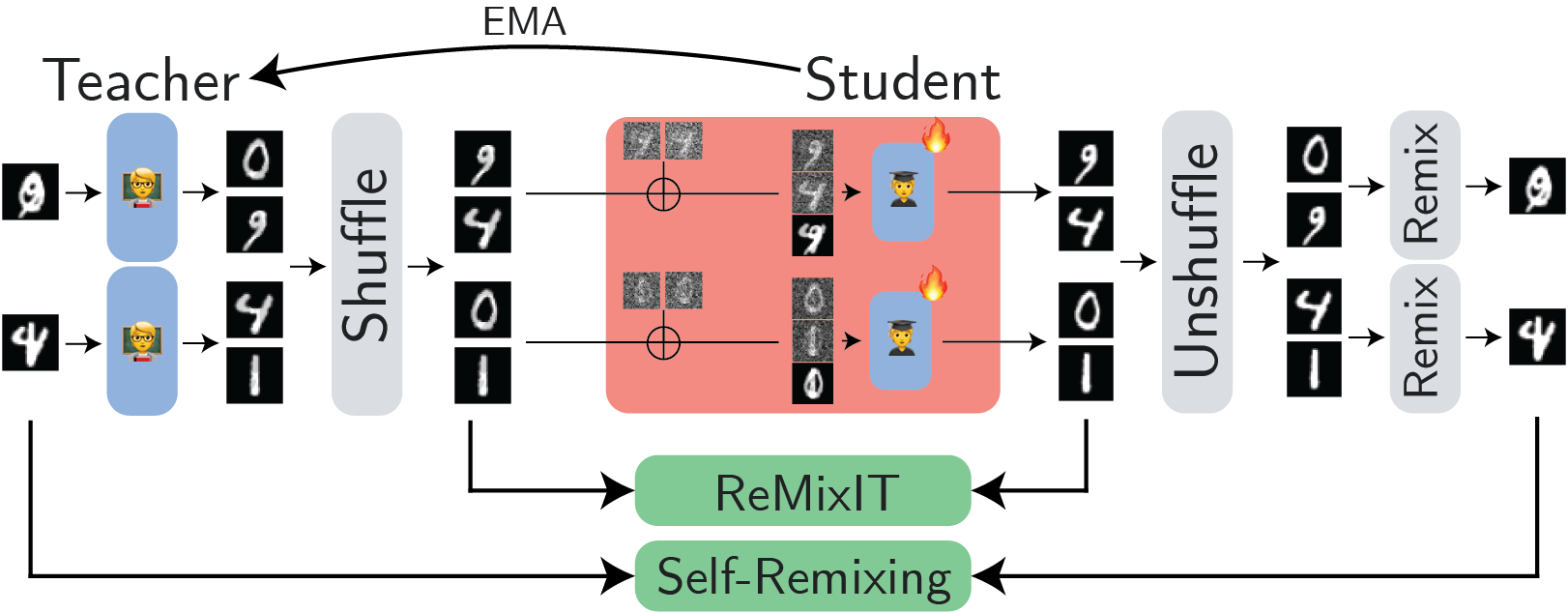
Unsupervised Image Separation
We evaluate image separation performance using the MNIST and CIFAR-10 datasets. Training and evaluation mixtures are constructed by averaging pairs of randomly selected images. Below we compare the qualitative separation results against various baselines.

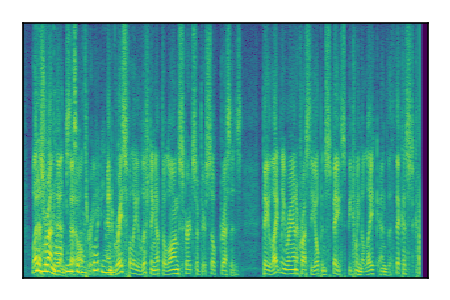
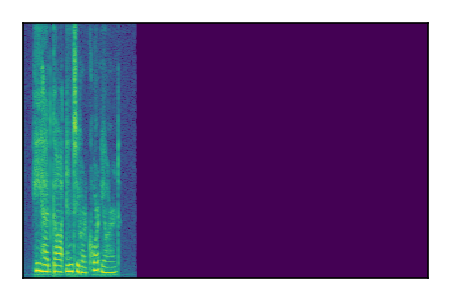
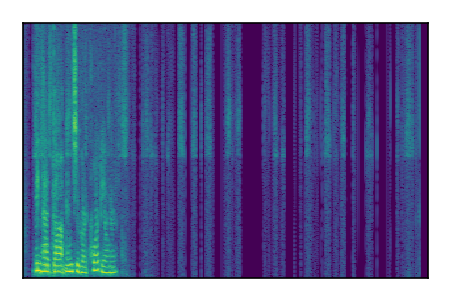
Libri2Mix: Speech Source Separation
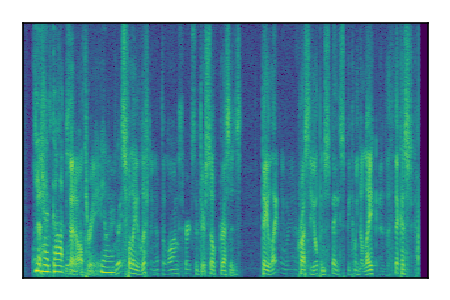
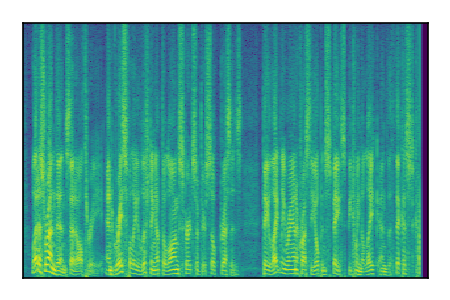
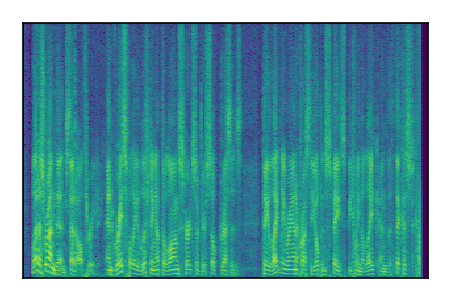
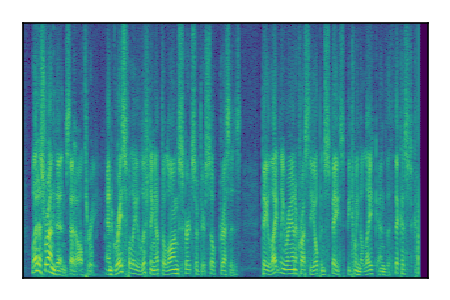
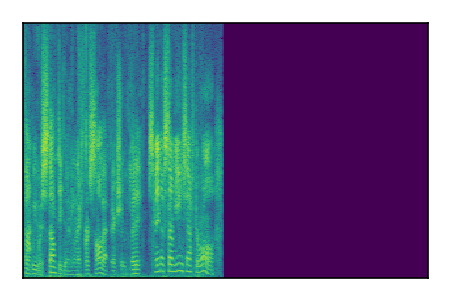
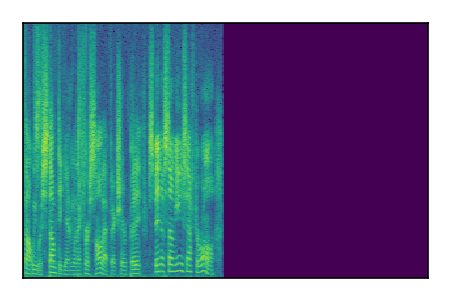
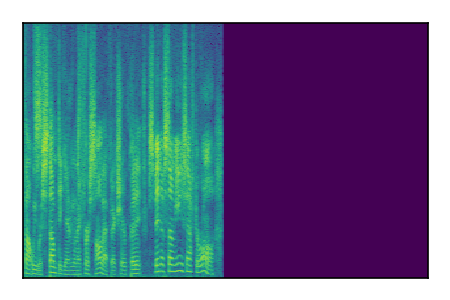
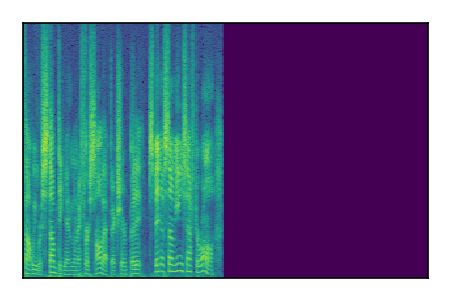
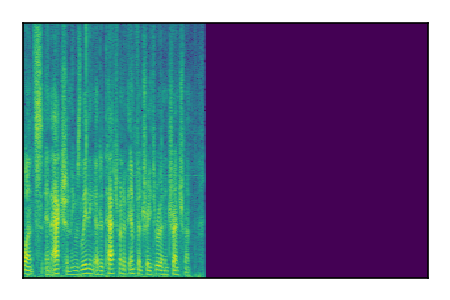
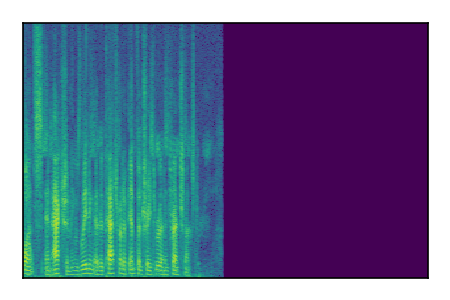
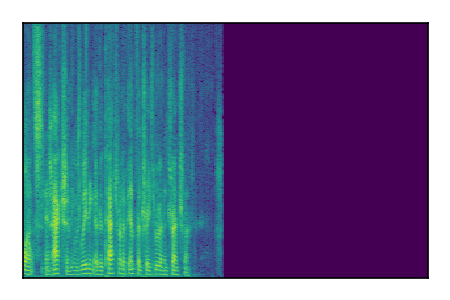
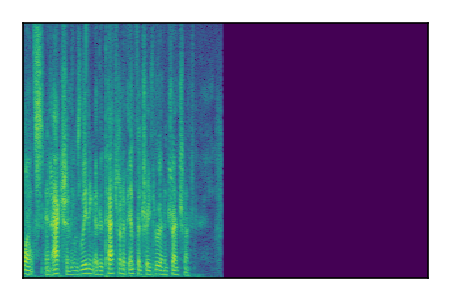
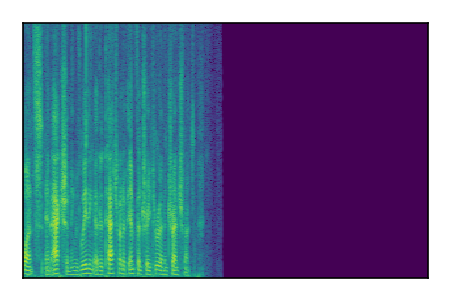
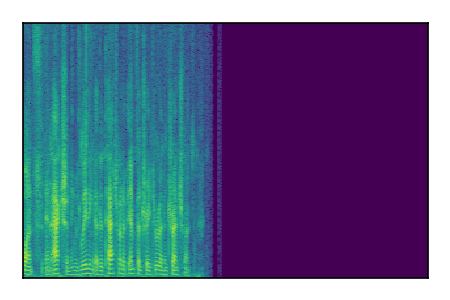
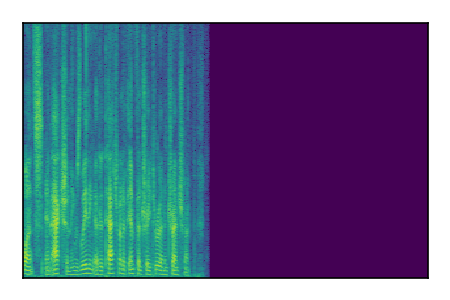
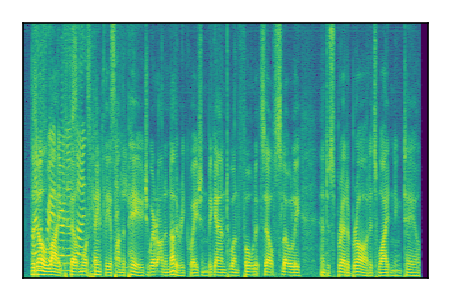
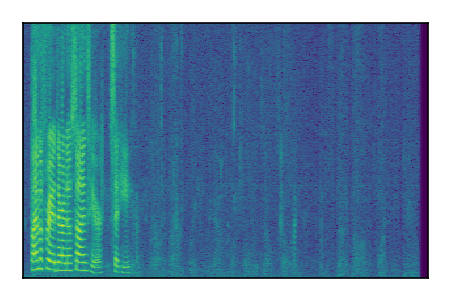
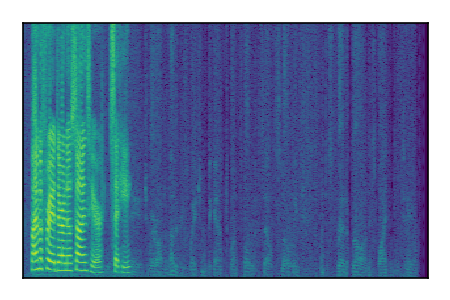
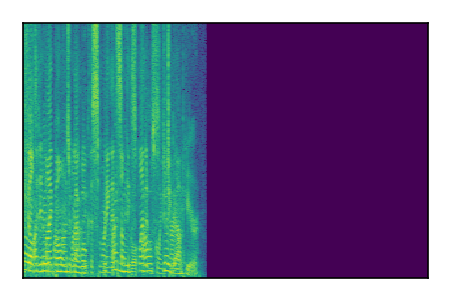
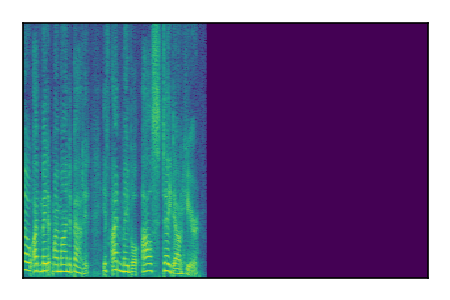
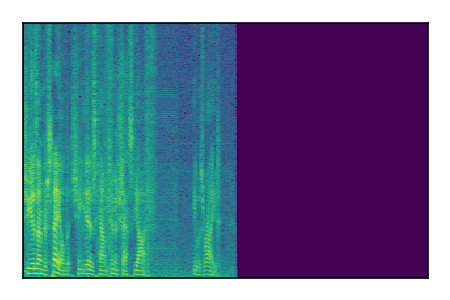
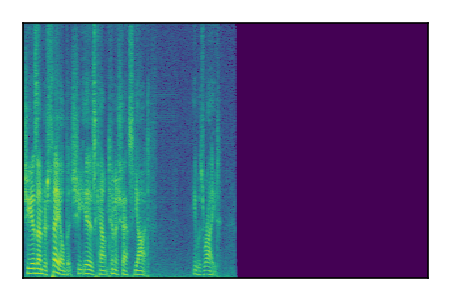
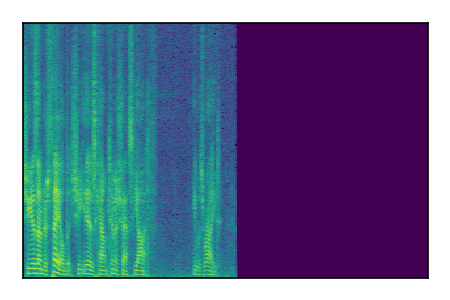
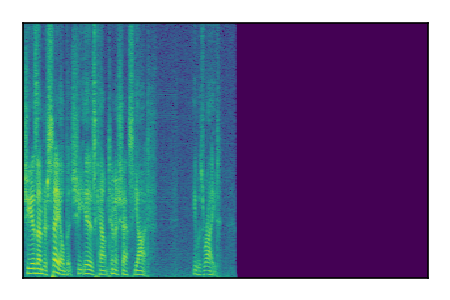
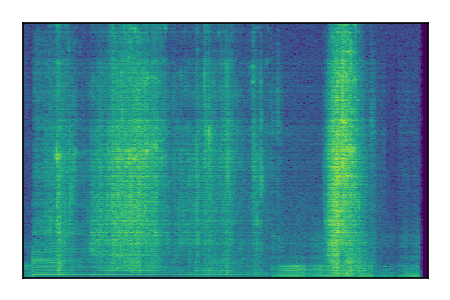
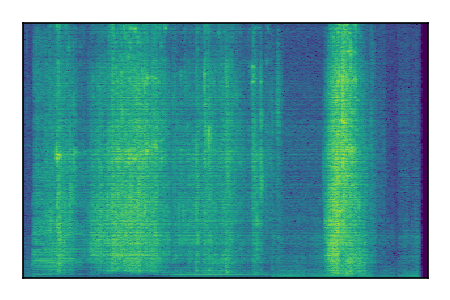
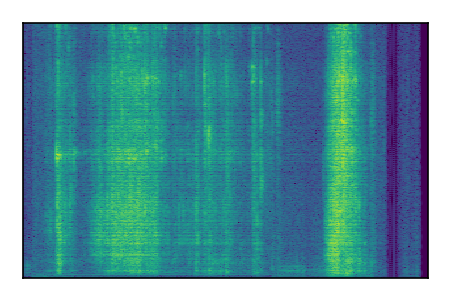
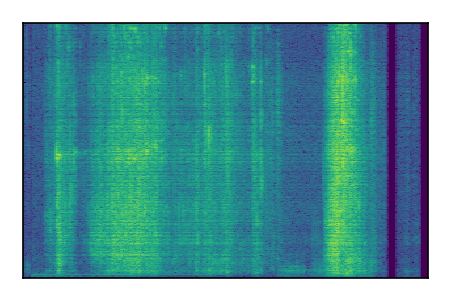
Separation of mixtures of clean speech sources. The model is trained on the Libri2Mix train-360-clean mixtures only.
| Sample | Mixture | Targets | Conv-TasNet MixIT | ReMixIT Regression | Self-Remixing Regression | ReMixIT Flow | Self-Remixing Flow | Supervised Flow |
|---|---|---|---|---|---|---|---|---|
| 1 |
|
|
|
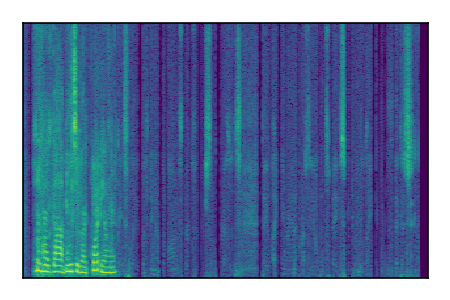
|
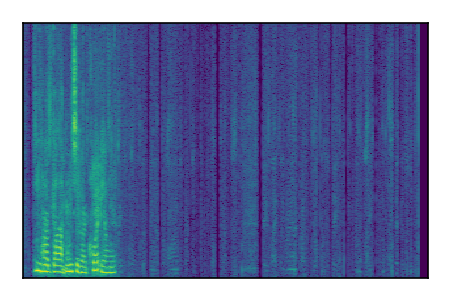
|
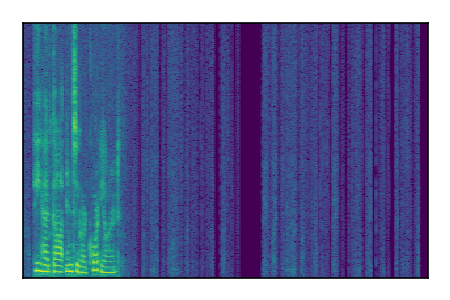
|
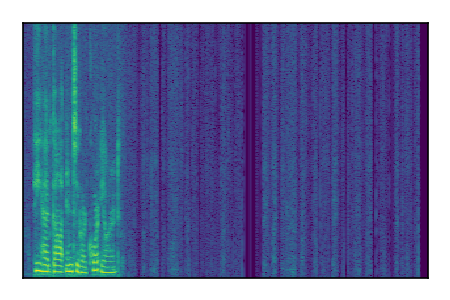
|
|
|
|
|
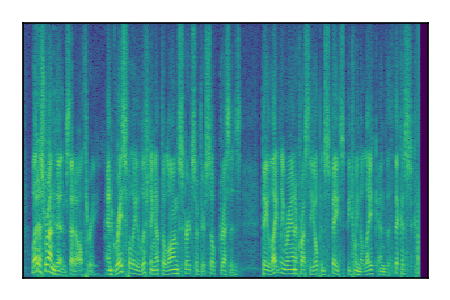
|
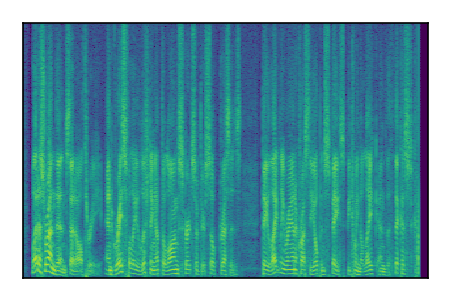
|
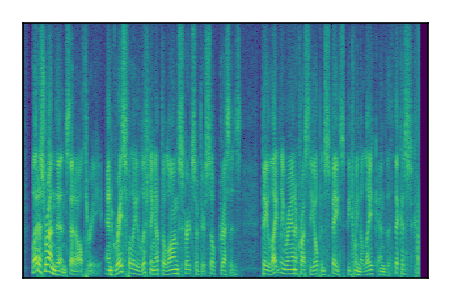
|
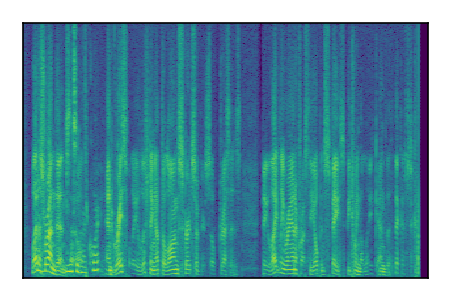
|
||
| 2 |
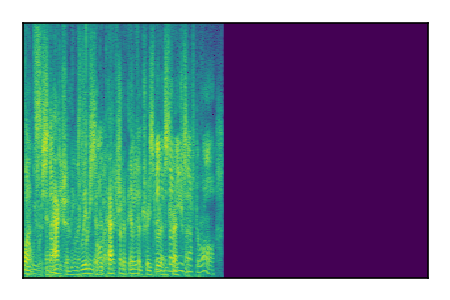
|
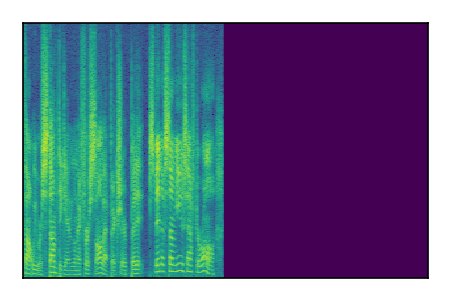
|
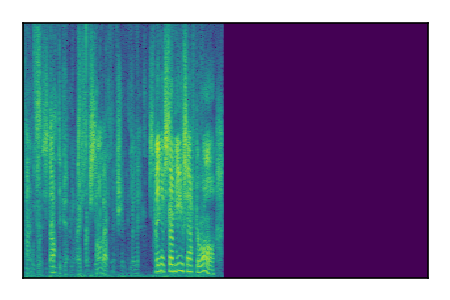
|
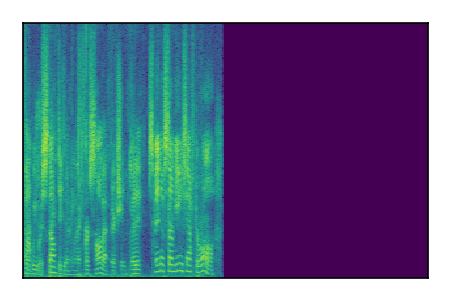
|
|
|
|
|
|
|
|
|
|
|
|
||
| 3 |
|
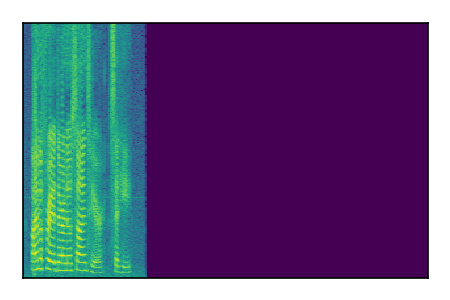
|
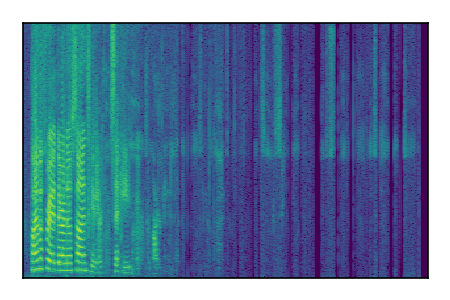
|
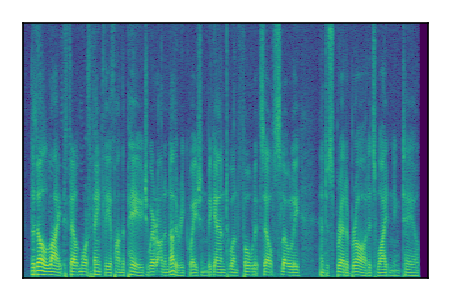
|
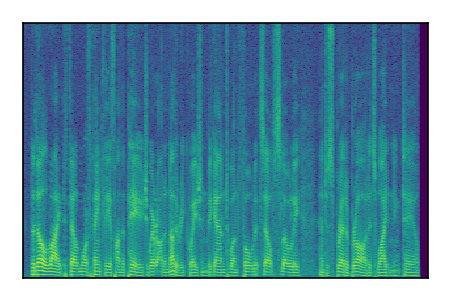
|
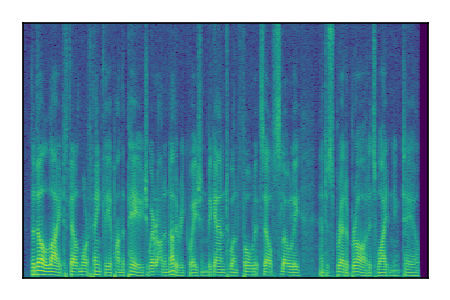
|
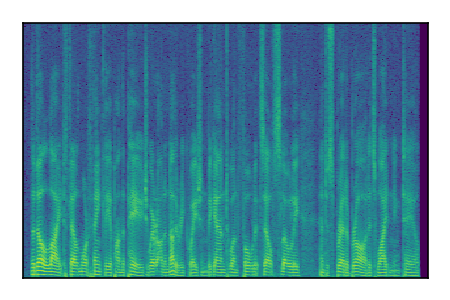
|
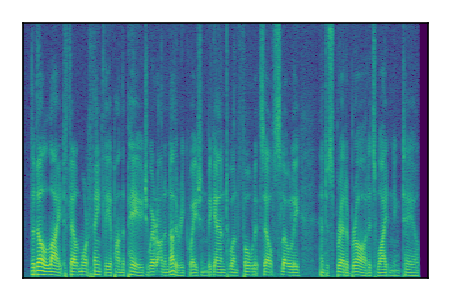
|
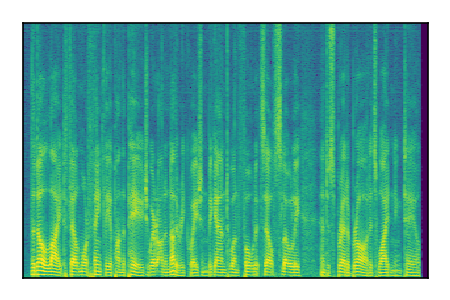
|
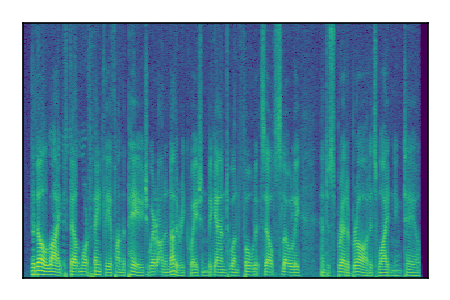
|
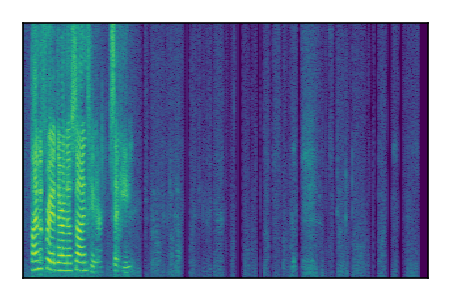
|
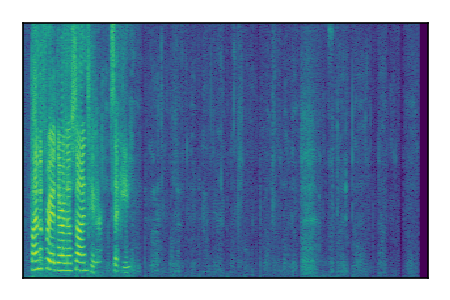
|
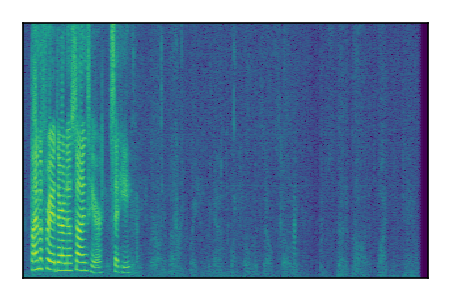
|
|
|
||
| 4 |
|
|
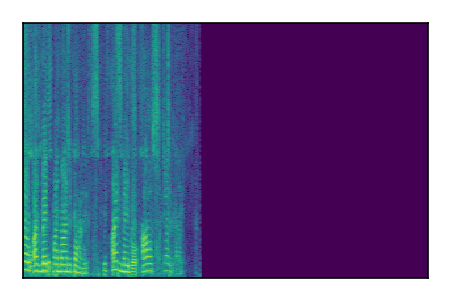
|
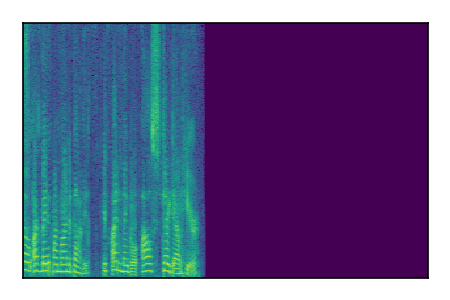
|
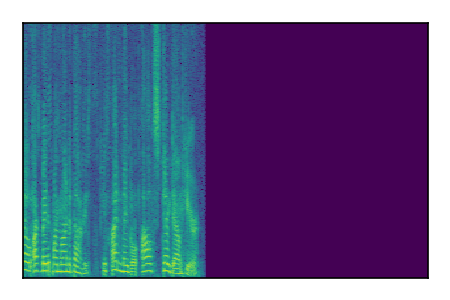
|
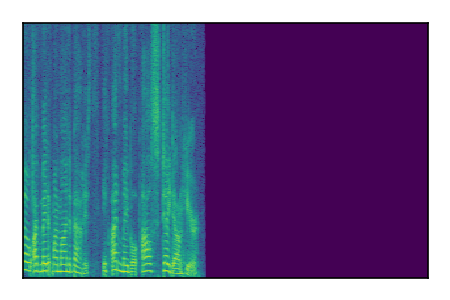
|
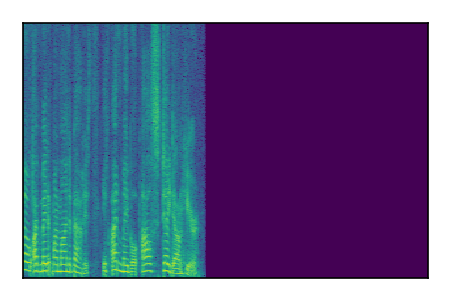
|
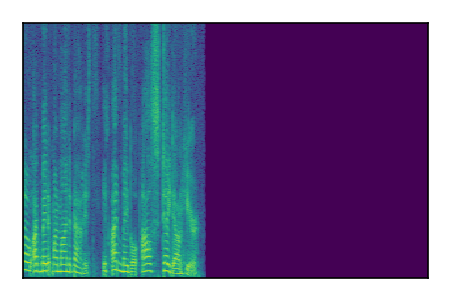
|
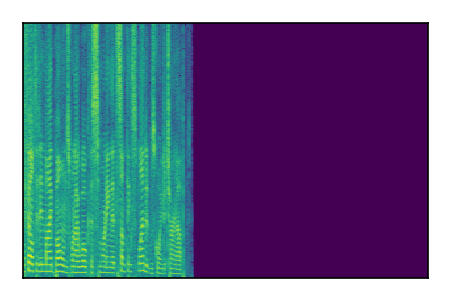
|
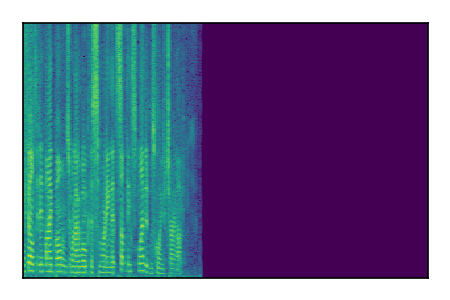
|
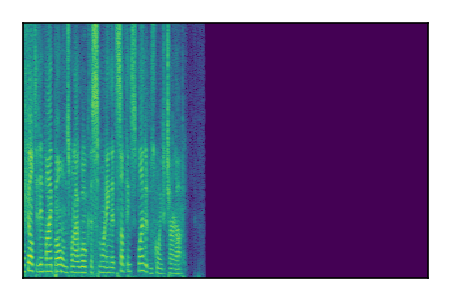
|
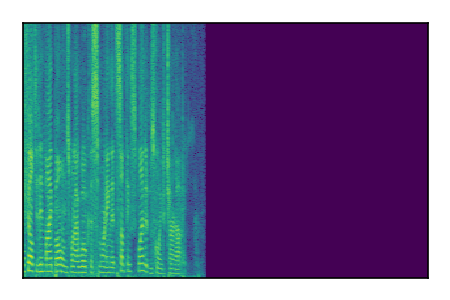
|
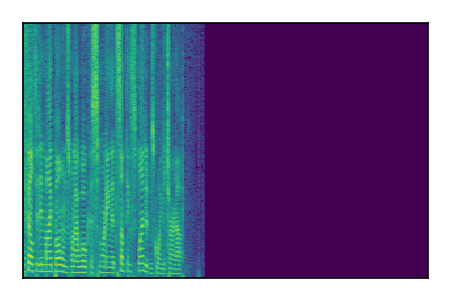
|
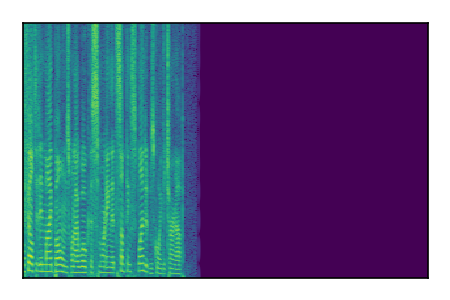
|
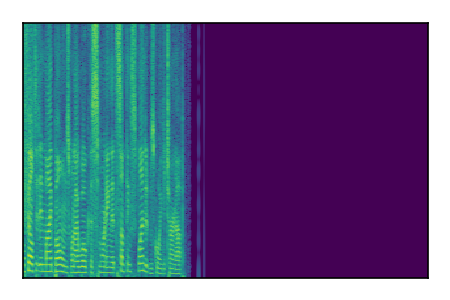
|
||
| 5 |
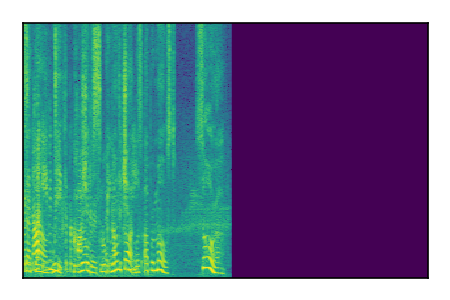
|
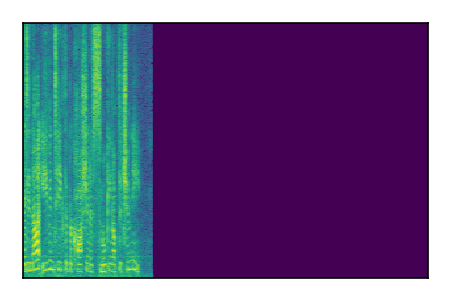
|
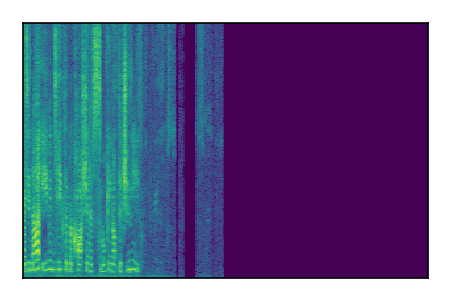
|
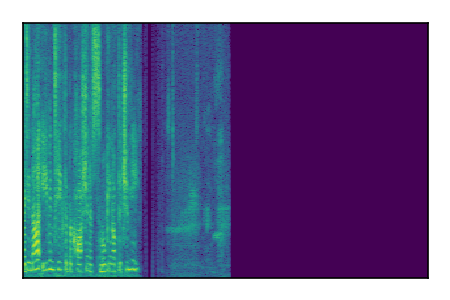
|
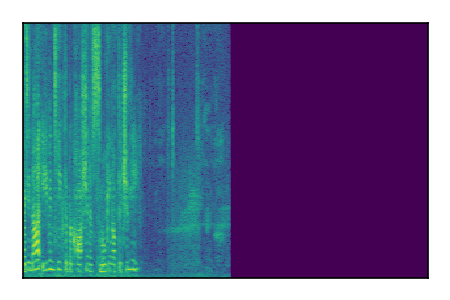
|
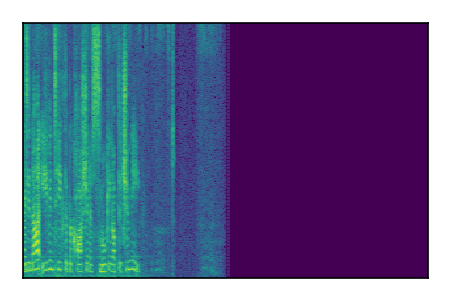
|
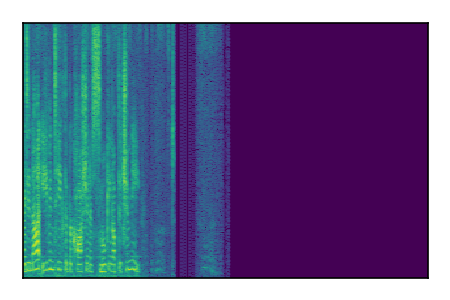
|
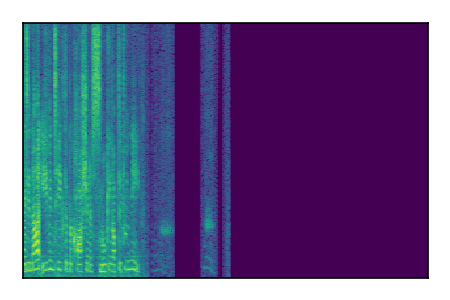
|
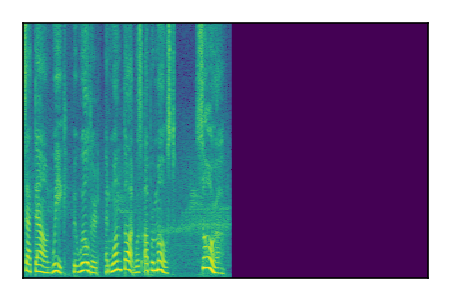
|
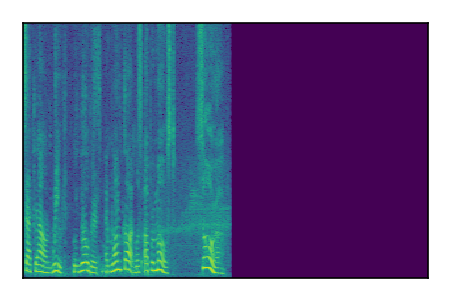
|
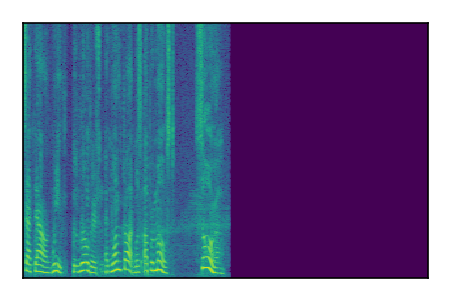
|
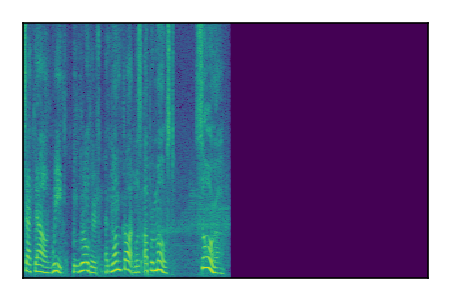
|
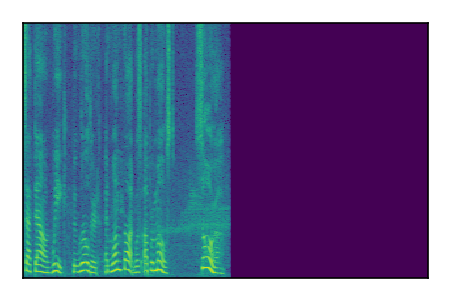
|
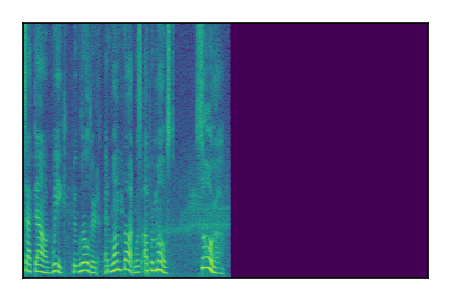
|
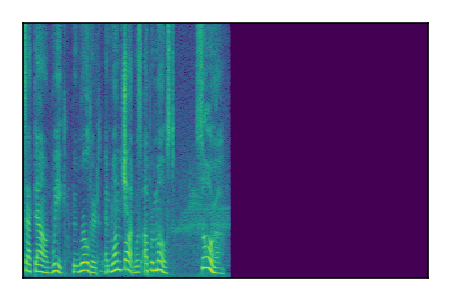
|
||
| 6 |
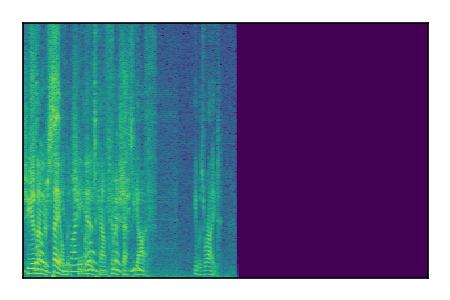
|
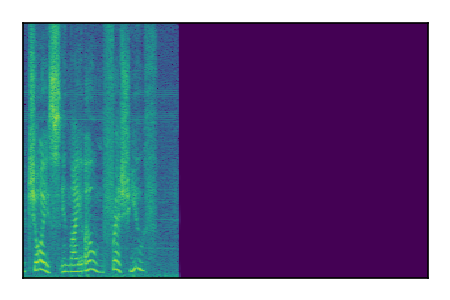
|
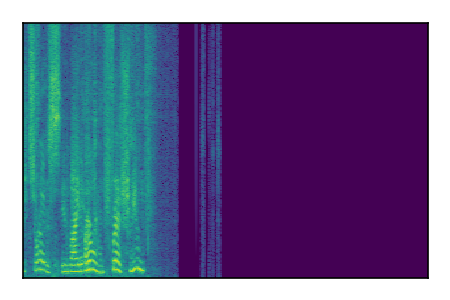
|
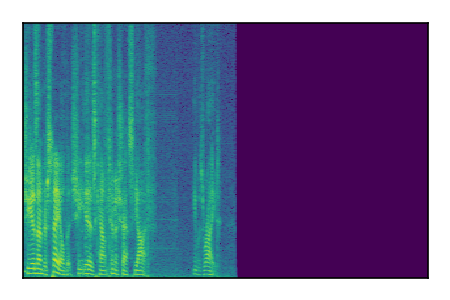
|
|
|
|
|
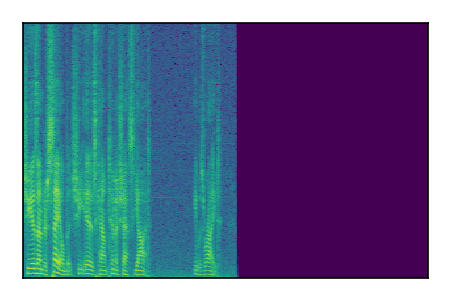
|
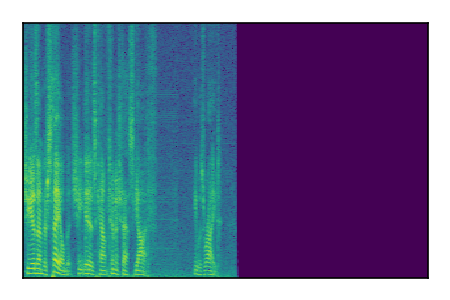
|
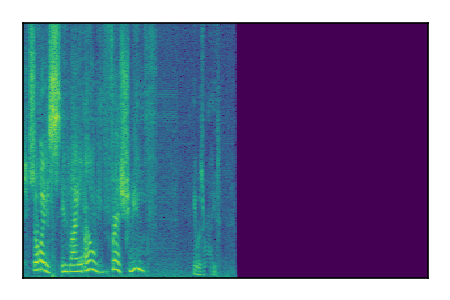
|
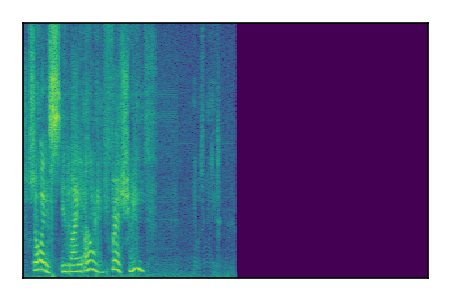
|
|
|
|
||
| 7 |
|
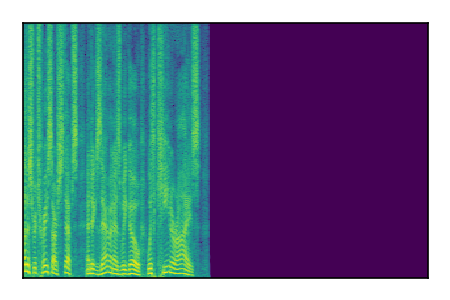
|
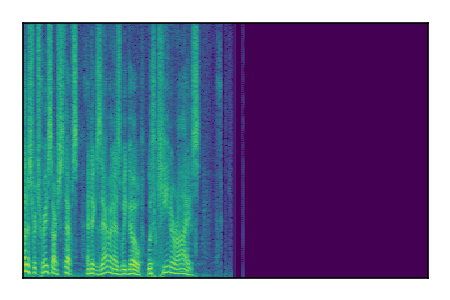
|
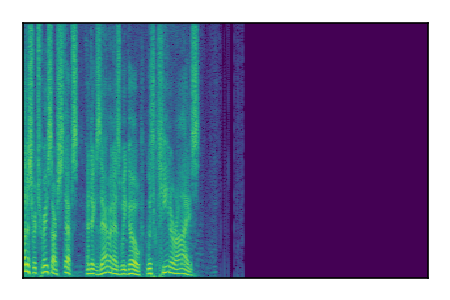
|
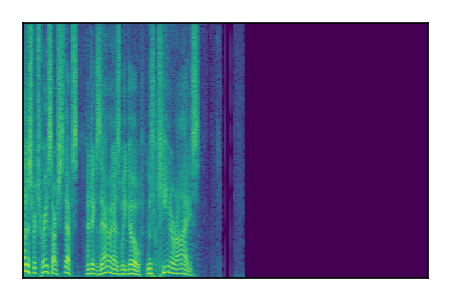
|
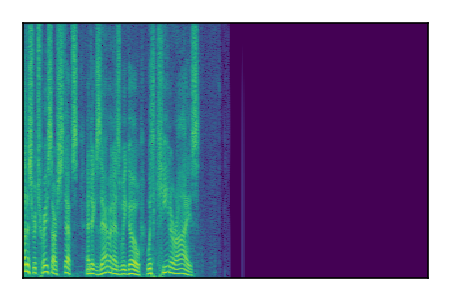
|
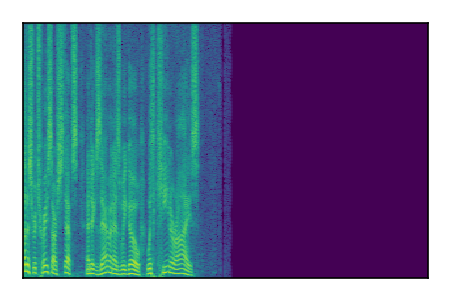
|
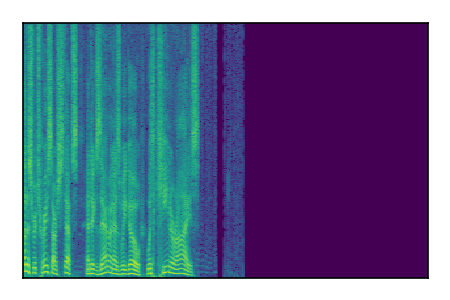
|
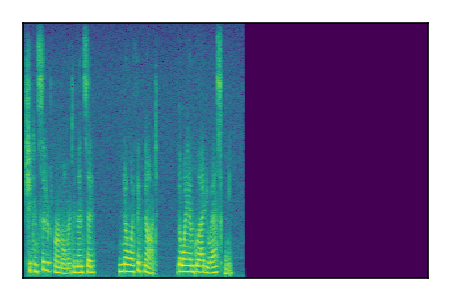
|
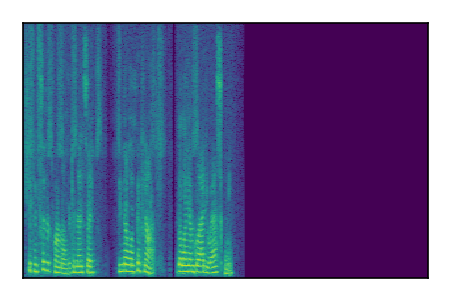
|
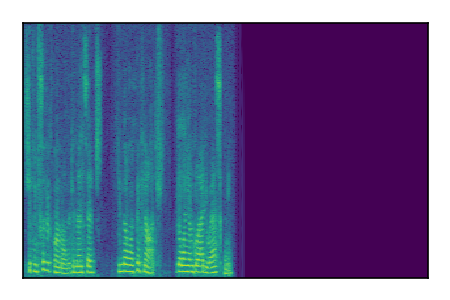
|
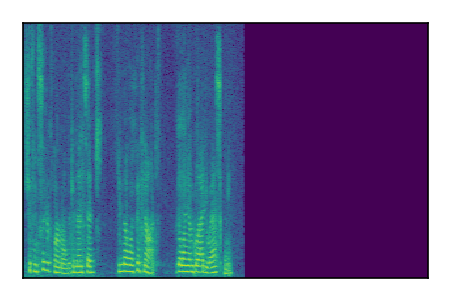
|
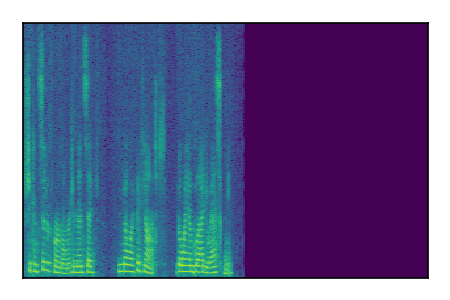
|
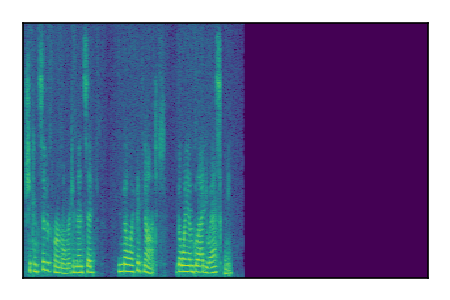
|
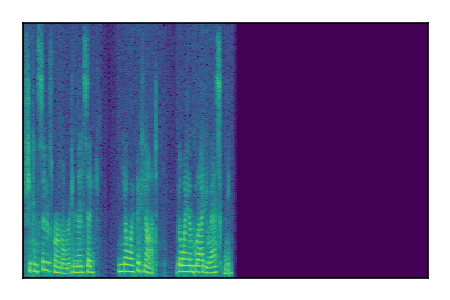
|
||
| 8 |
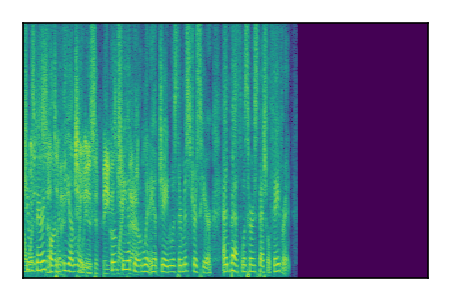
|
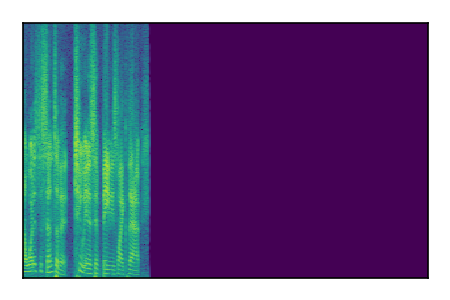
|
|
|
|
|
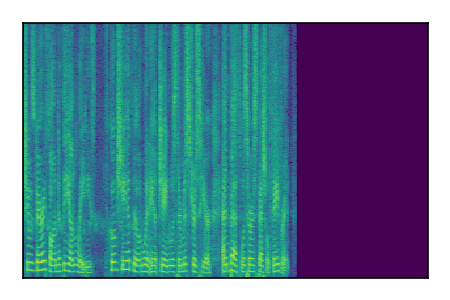
|
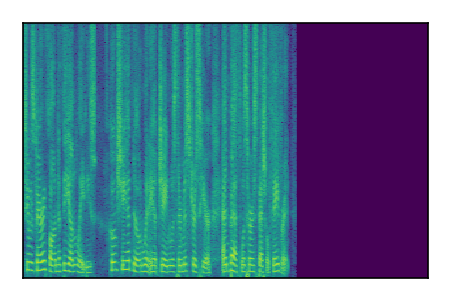
|
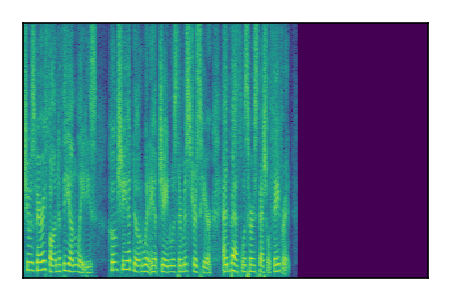
|
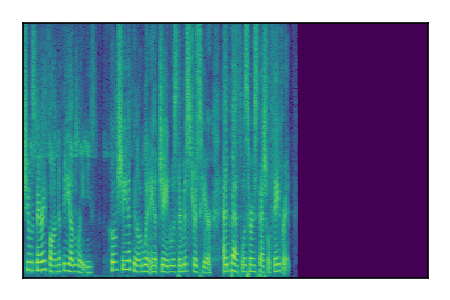
|
|
|
|
|
|
||
| 9 |
|
|
|
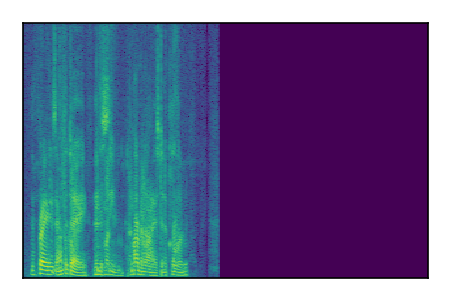
|
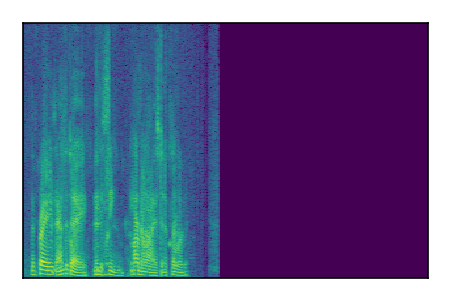
|
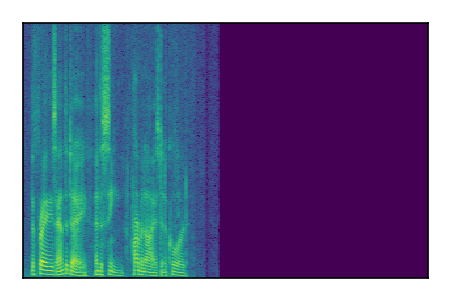
|
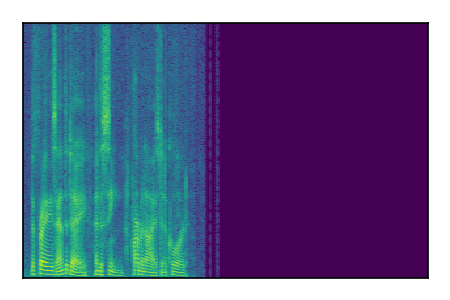
|
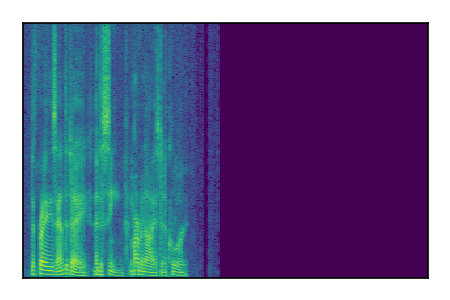
|
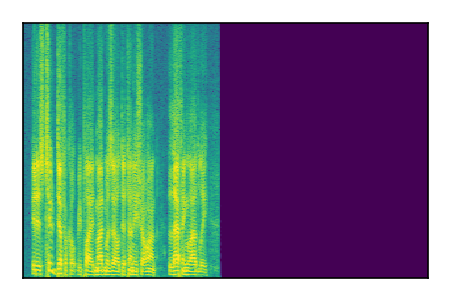
|
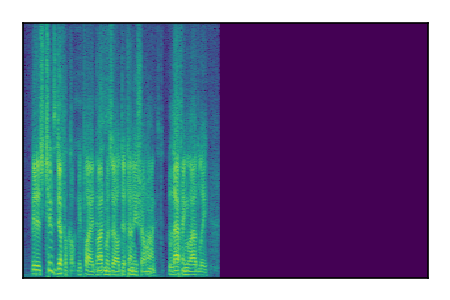
|
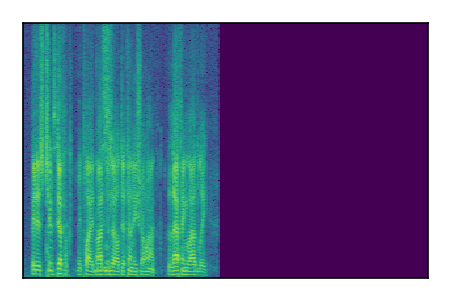
|
|
|
|
|
||
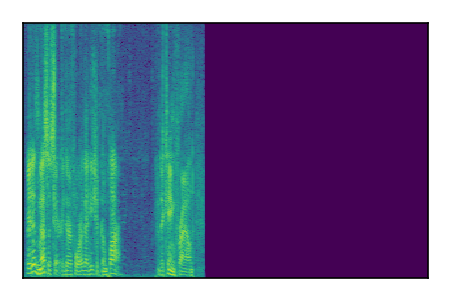
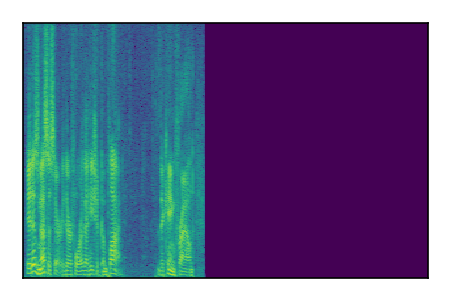
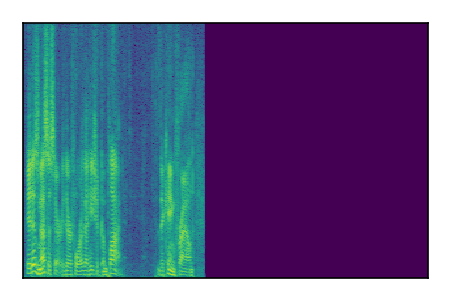
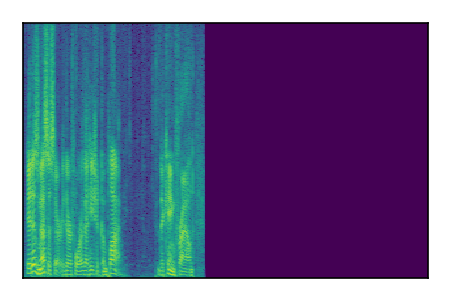
| 10 |
|
|
|
|
|
|
|
|
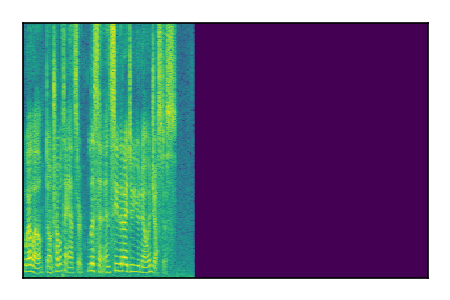
|
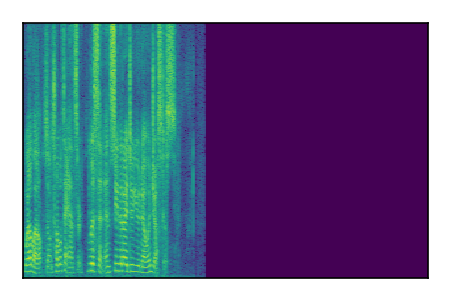
|
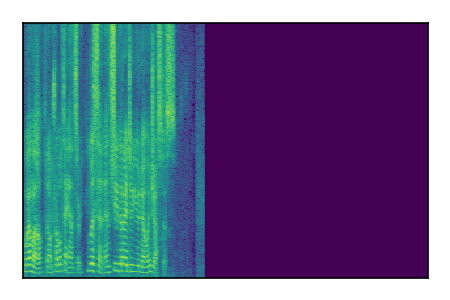
|
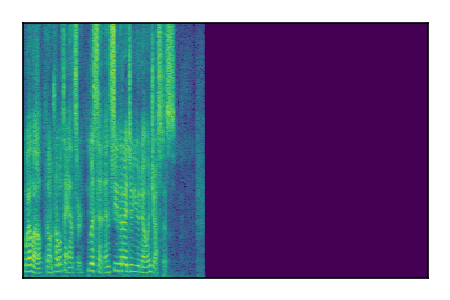
|
|
|
|
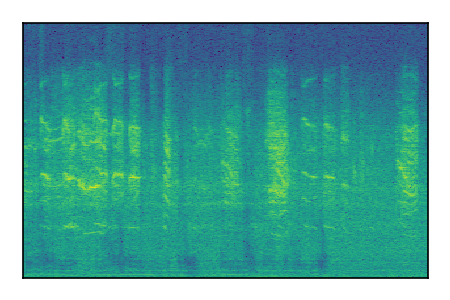
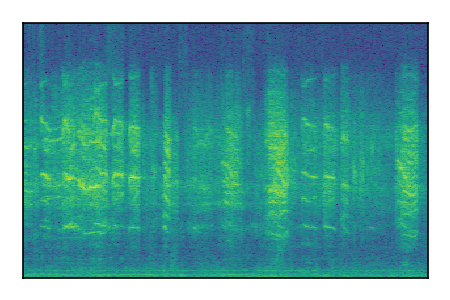
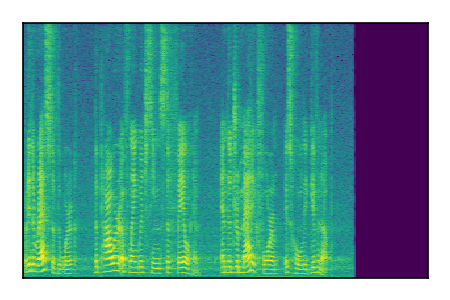
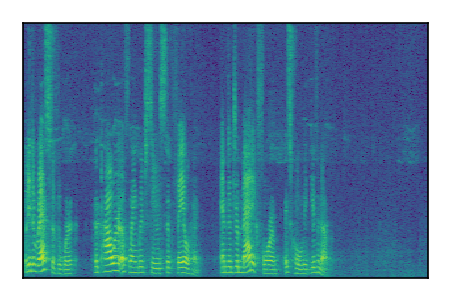
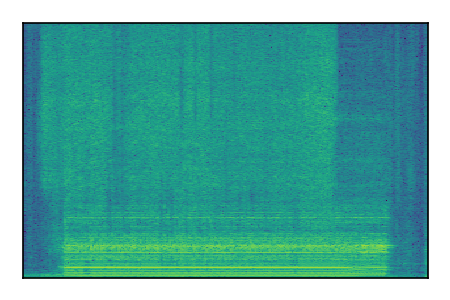
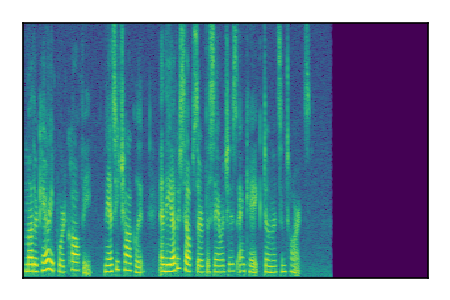
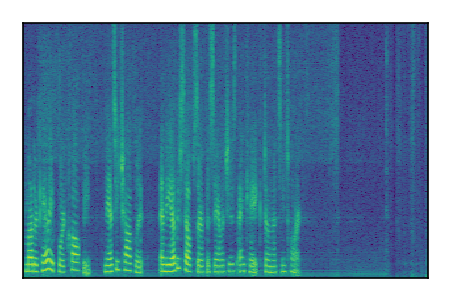
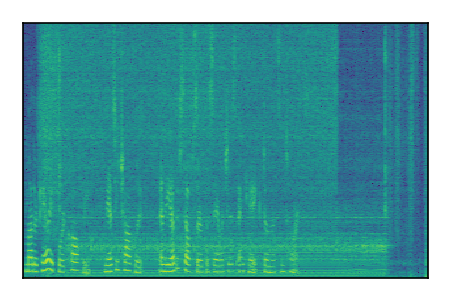
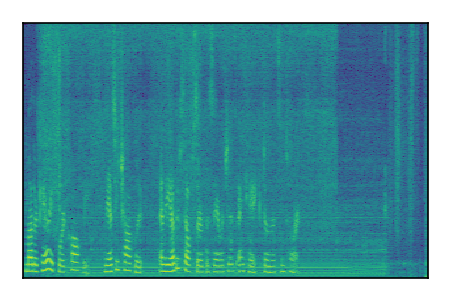
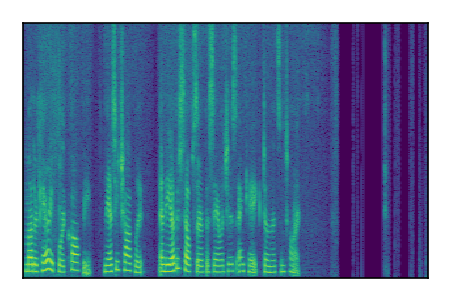
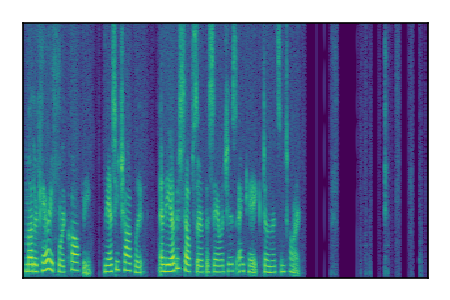
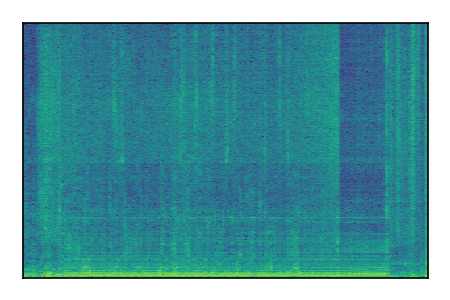
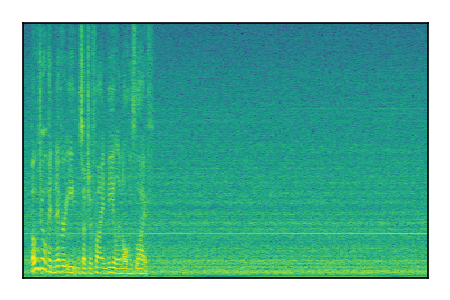
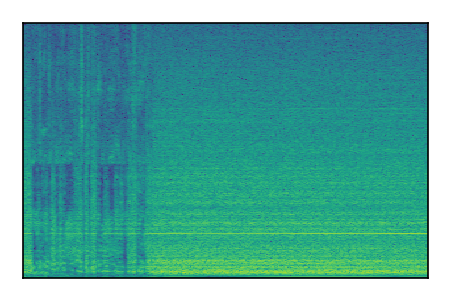
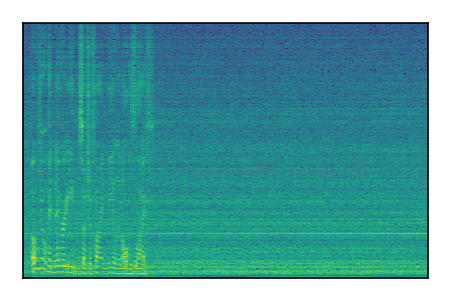
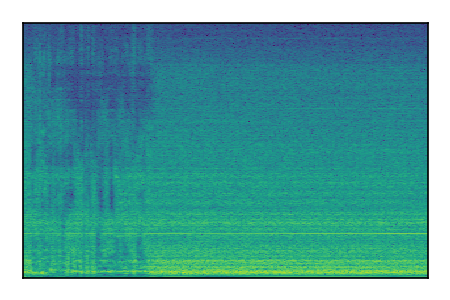
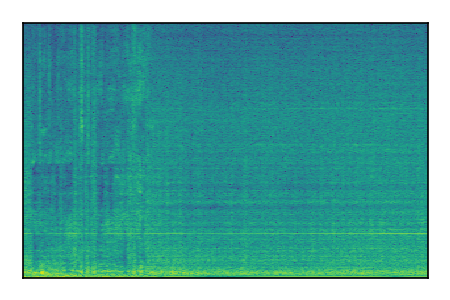
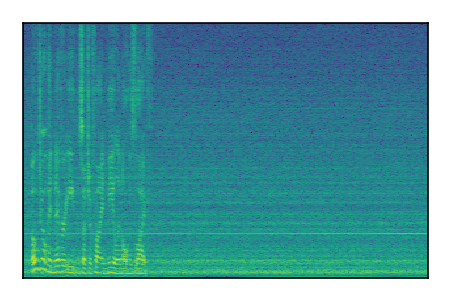
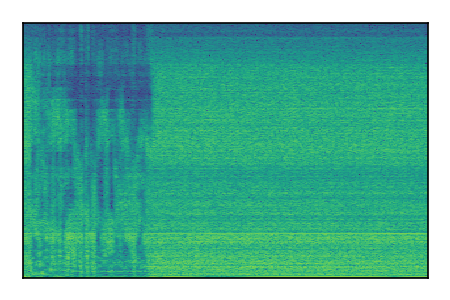
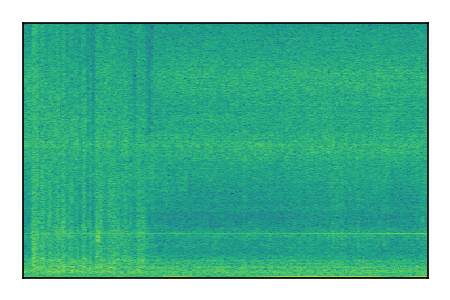
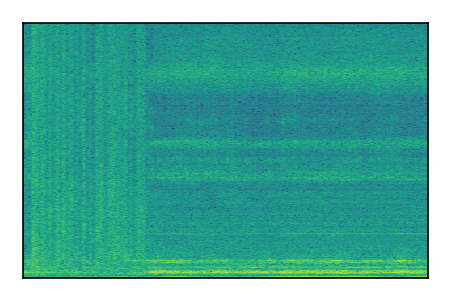
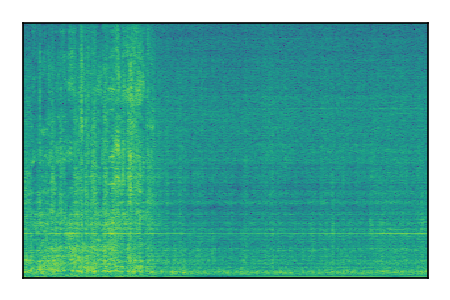
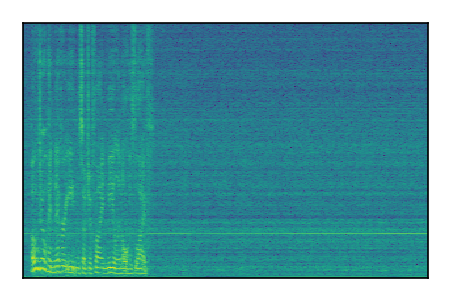
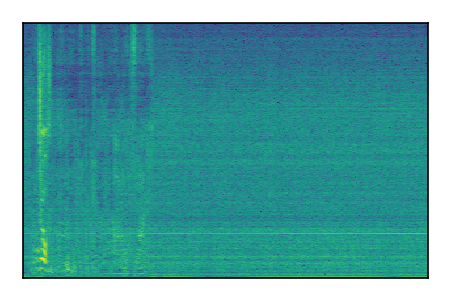
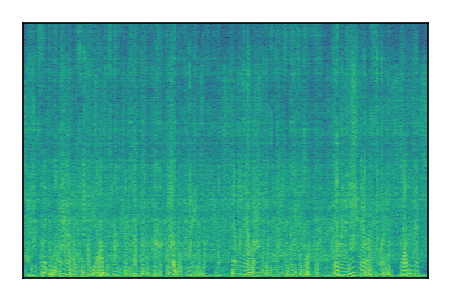
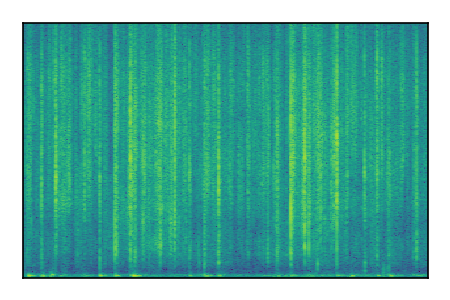
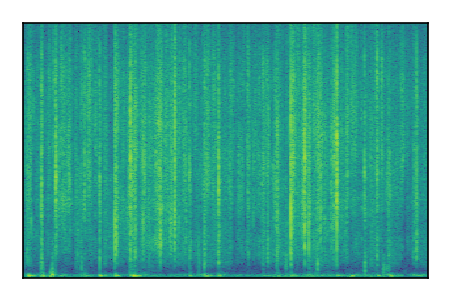
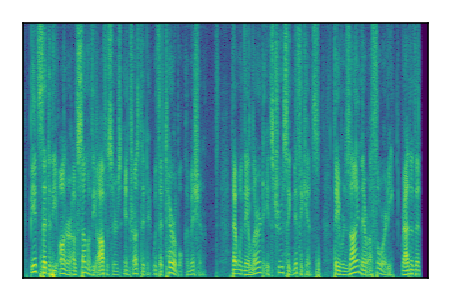
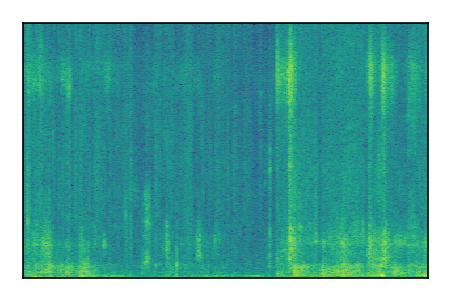
LibriSpeech+FUSS
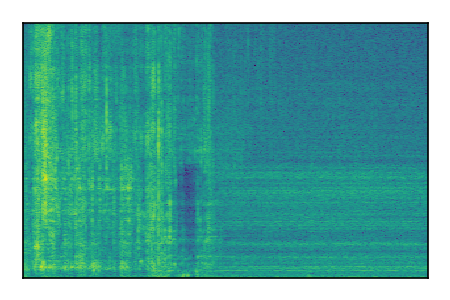
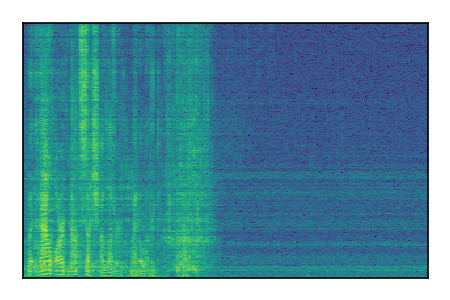
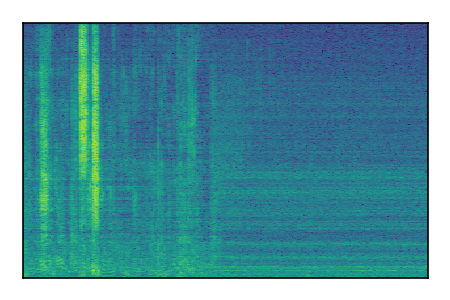
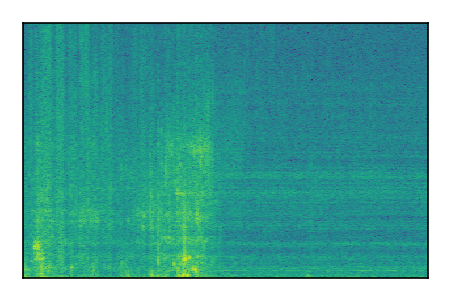
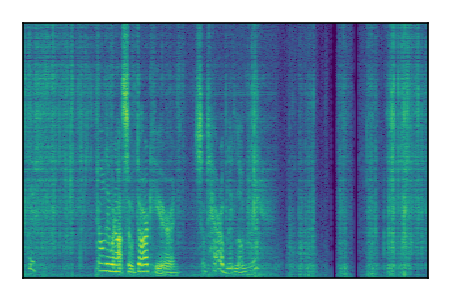
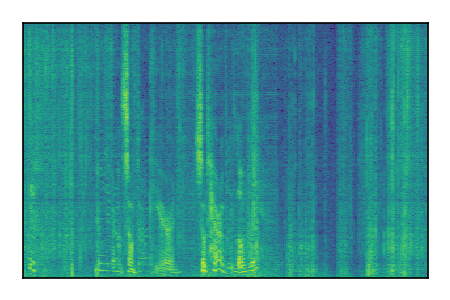
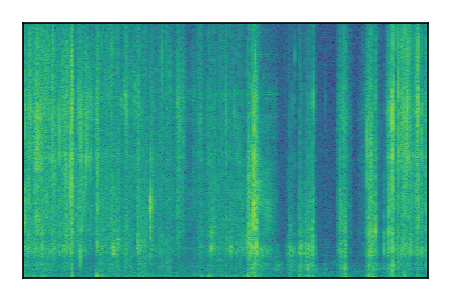
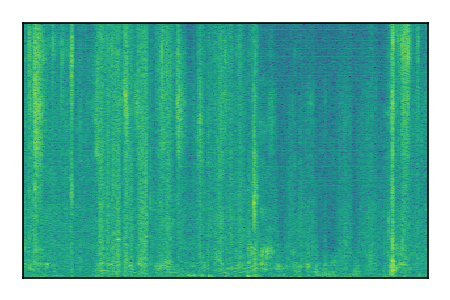
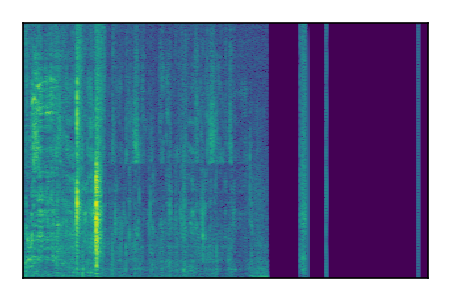
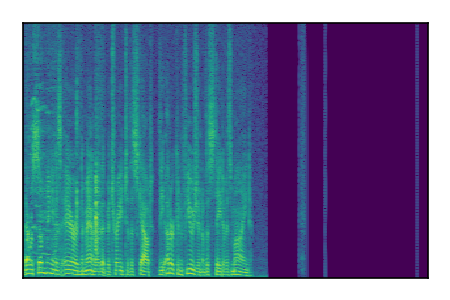
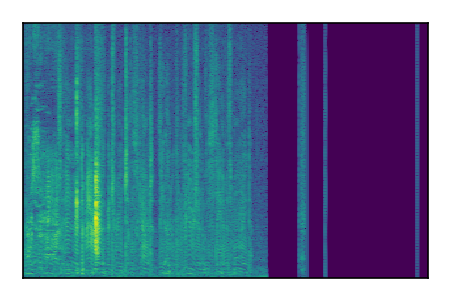
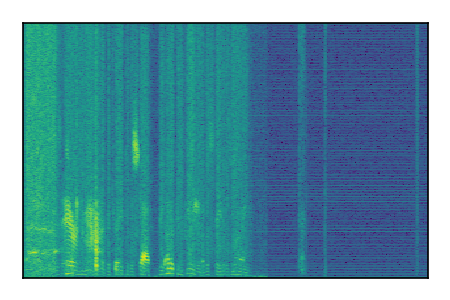
Separation of mixtures of clean speech from LibriSpeech and noise from FUSS. The model is trained on AudioSet.
| Sample | Mixture | Targets | MixIT ConvTasNet | ReMixIT Regression | Self-Remixing Regression | ReMixIT Flow | Self-Remixing Flow |
|---|---|---|---|---|---|---|---|
| 1 |
|
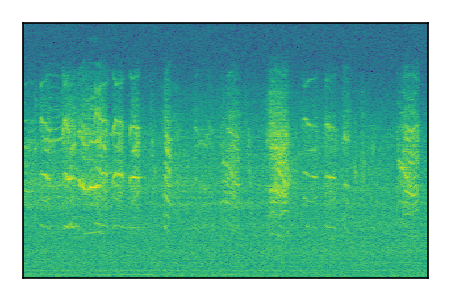
|
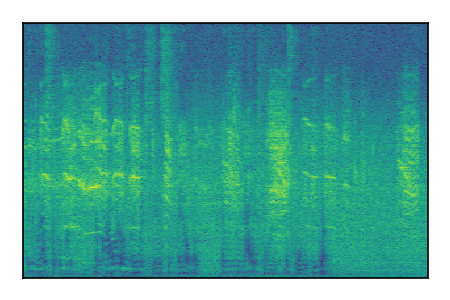
|
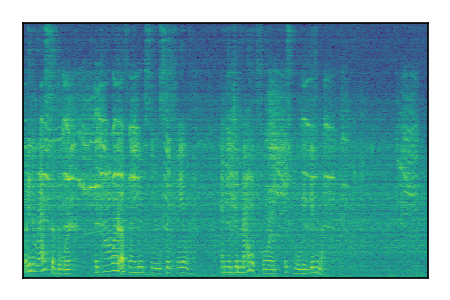
|
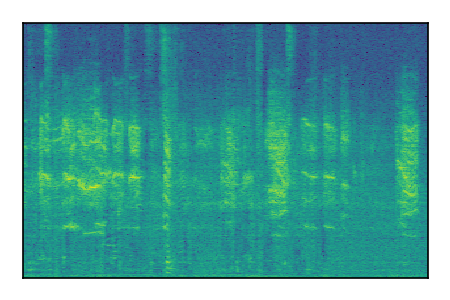
|
|
|
|
|
|
|
|
|
||

|
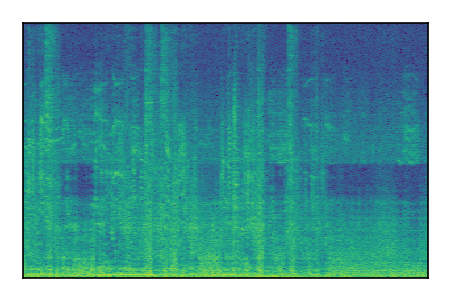
|
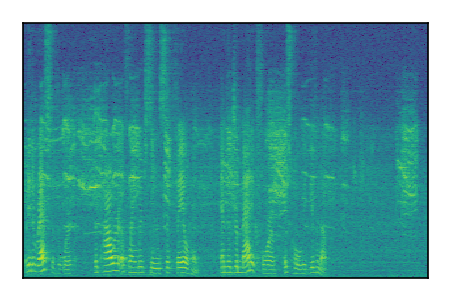
|
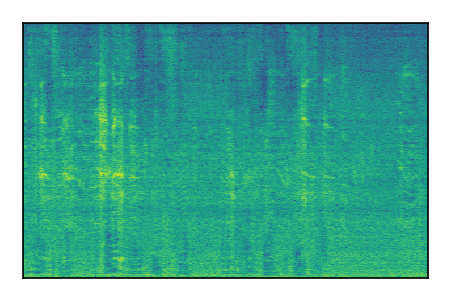
|
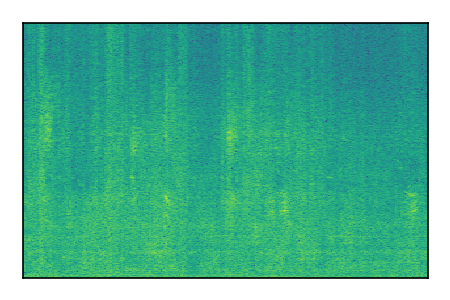
|
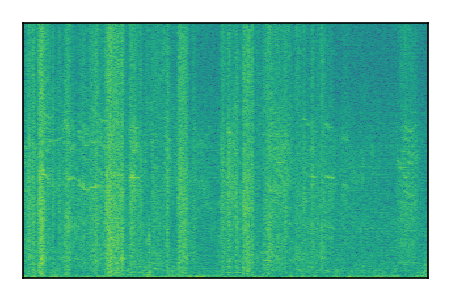
|
||

|
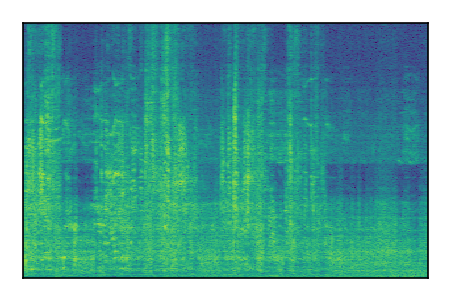
|
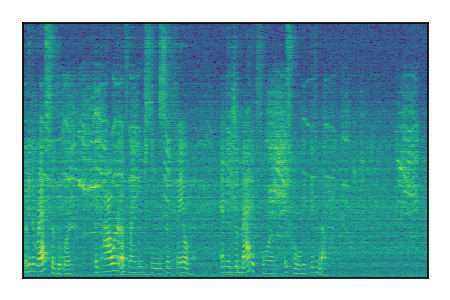
|
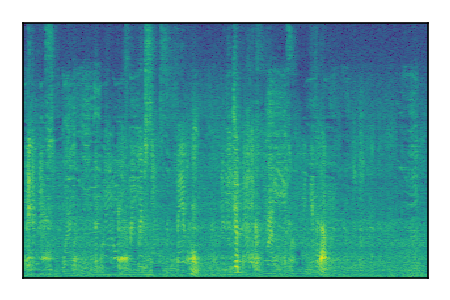
|
|
|
||
| 2 |
|
|
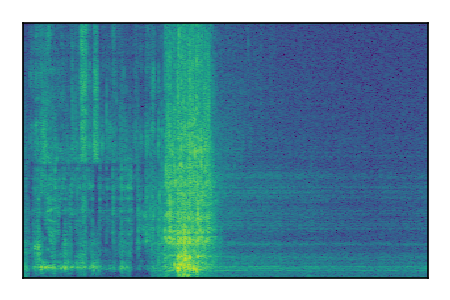
|
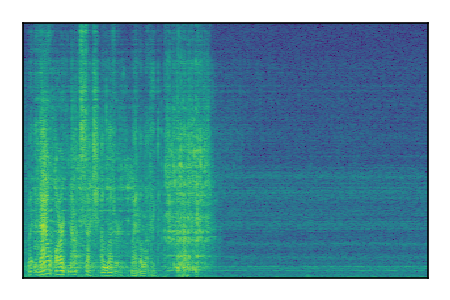
|
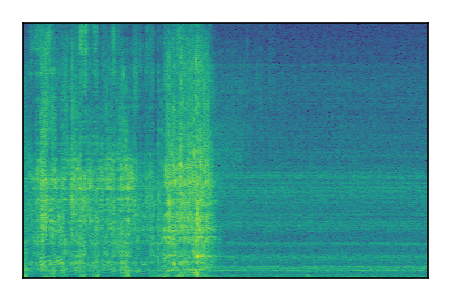
|
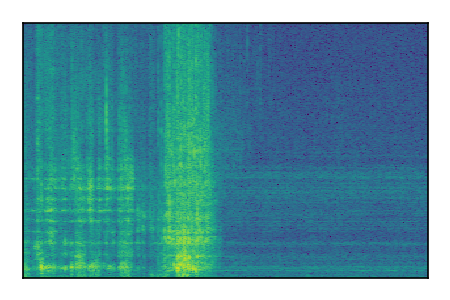
|
|
|
|
|
|
|
|
||

|
|
|
|
|
|
||

|
|
|
|
|
|
||
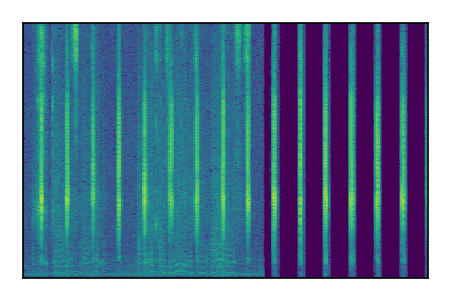
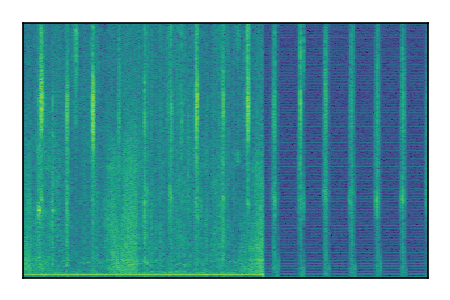
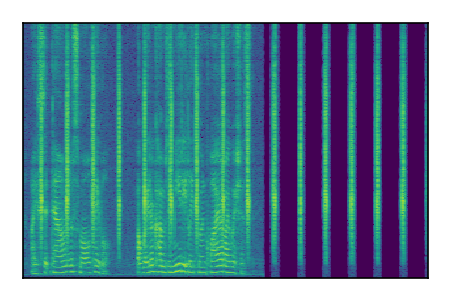
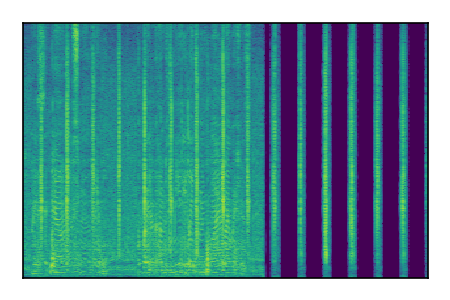
| 3 |
|
|
|
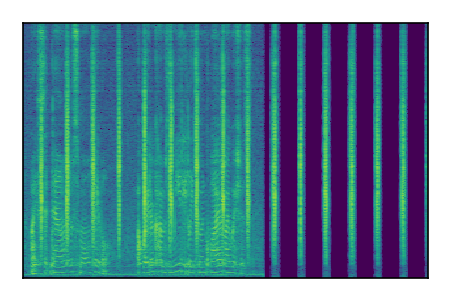
|
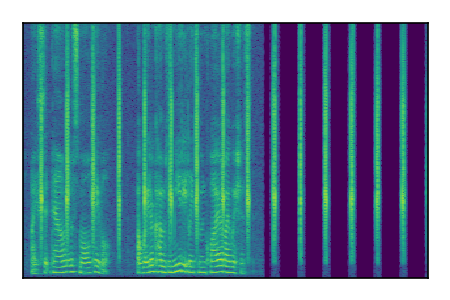
|
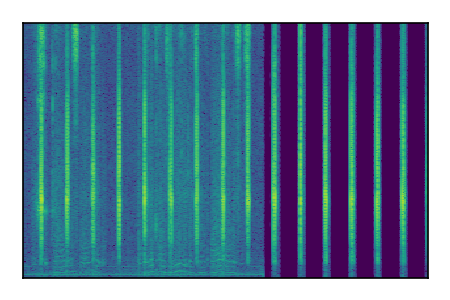
|
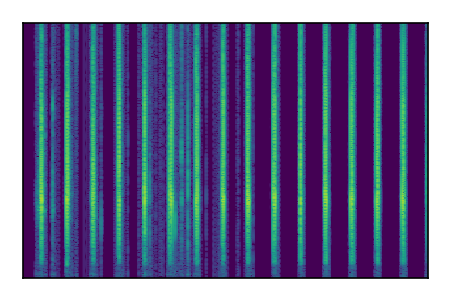
|
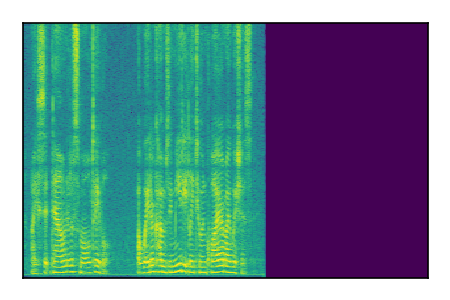
|
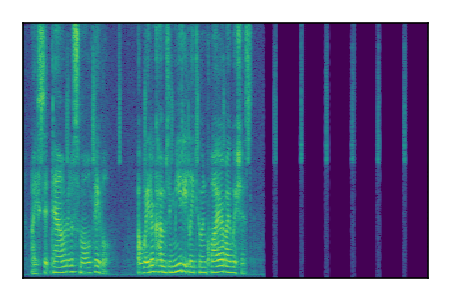
|
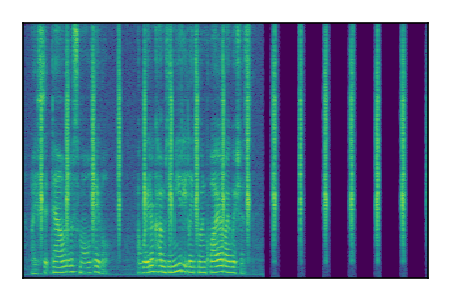
|
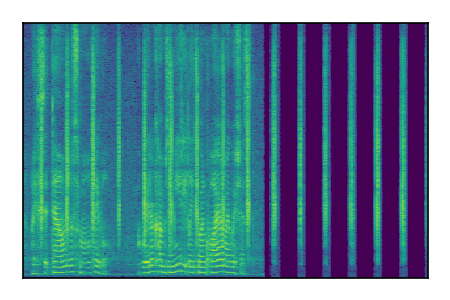
|
|
|
||

|

|
|
|
|
|
||

|

|
|
|
|
|
||
| 4 |
|
|
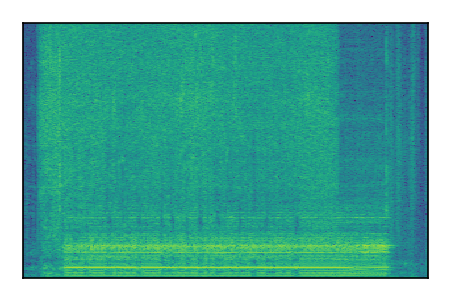
|
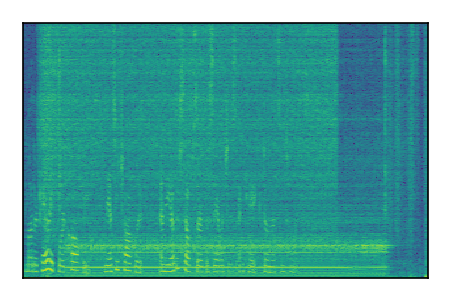
|
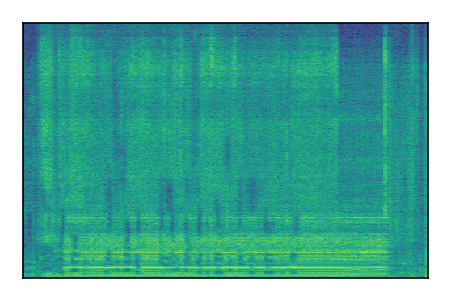
|
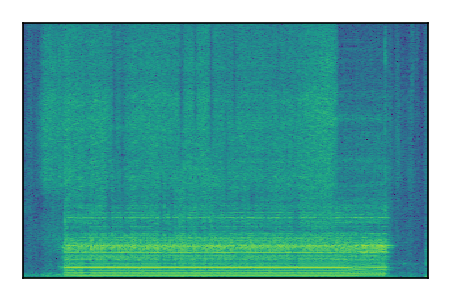
|
|
|
|
|
|
|
|
||

|
|
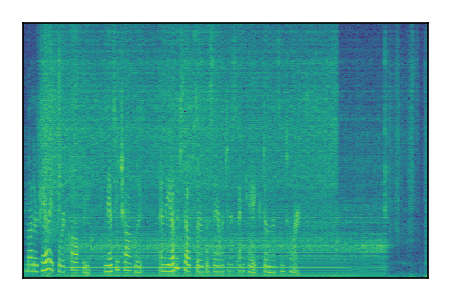
|
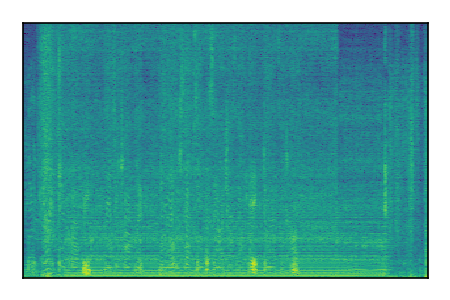
|
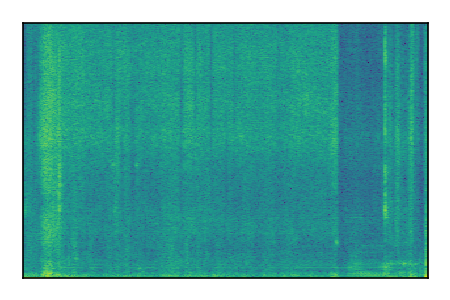
|
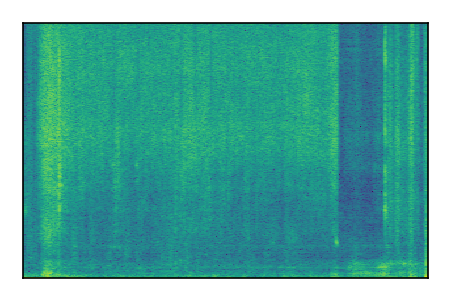
|
||

|
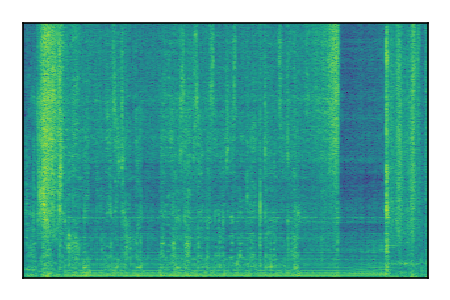
|
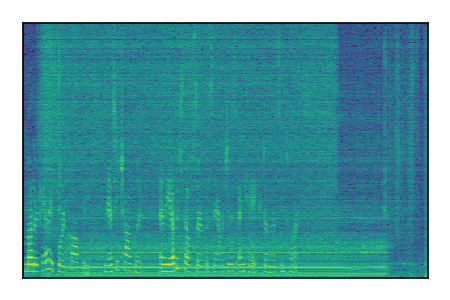
|
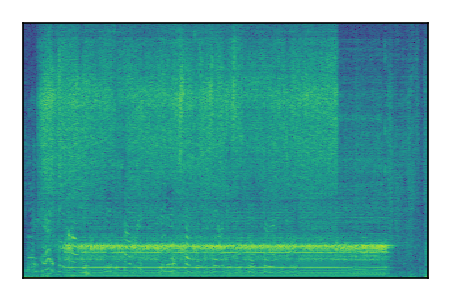
|
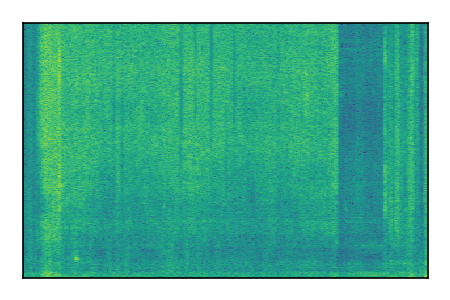
|
|
||
| 5 |
|
|
|
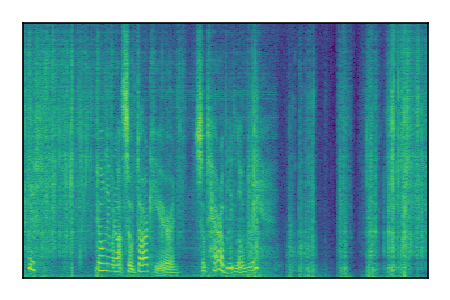
|
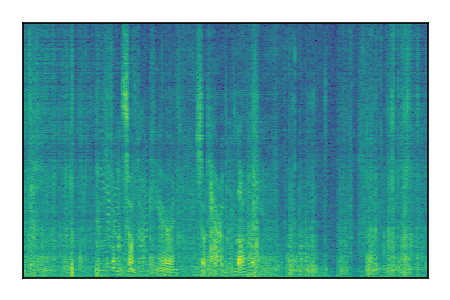
|
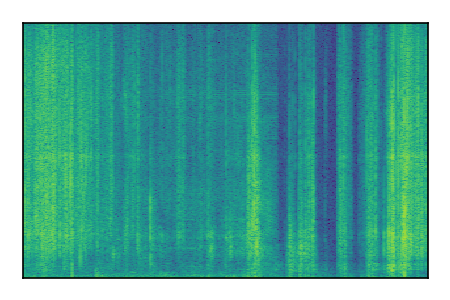
|
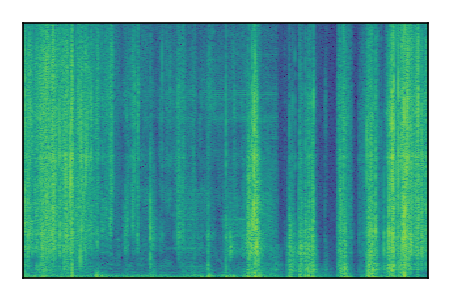
|
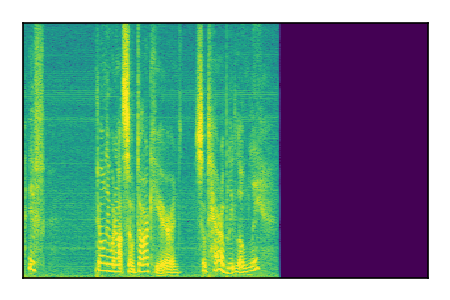
|
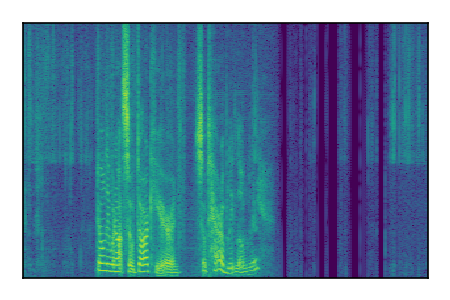
|
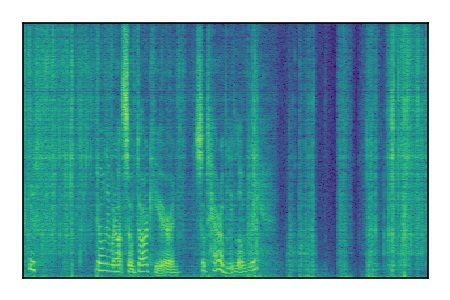
|
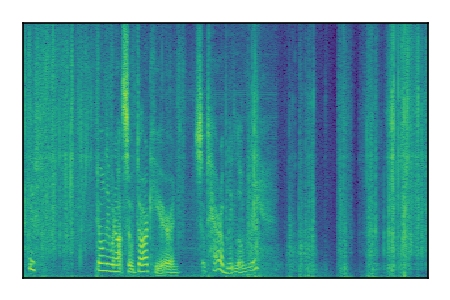
|
|
|
||

|
|
|
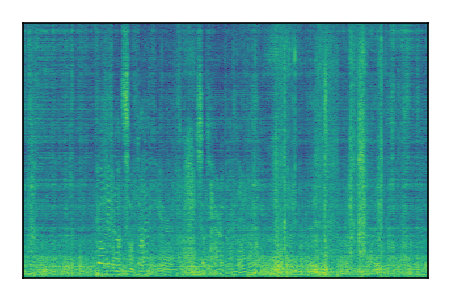
|
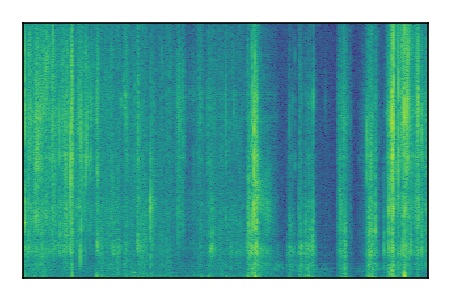
|
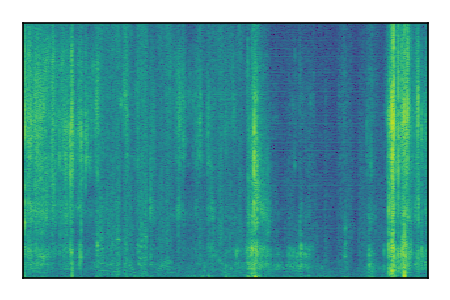
|
||

|
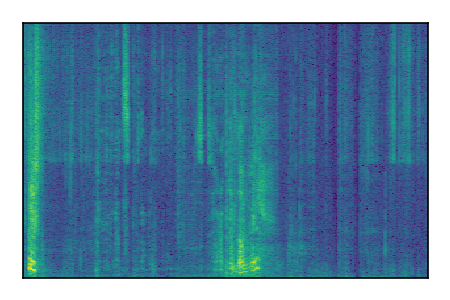
|
|
|
|
|
||
| 6 |
|

|
|
|
|
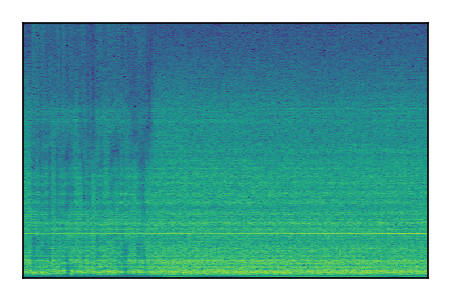
|
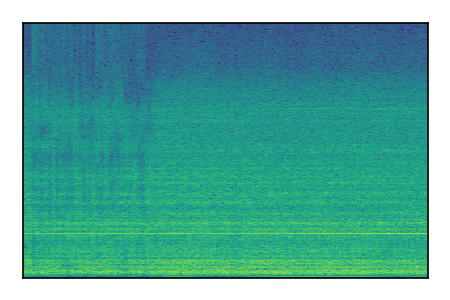
|
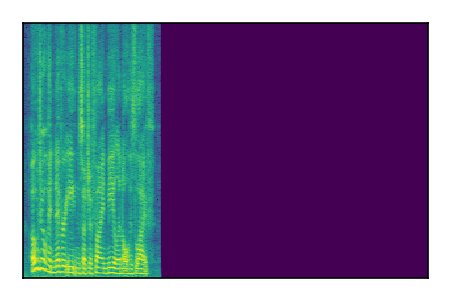
|
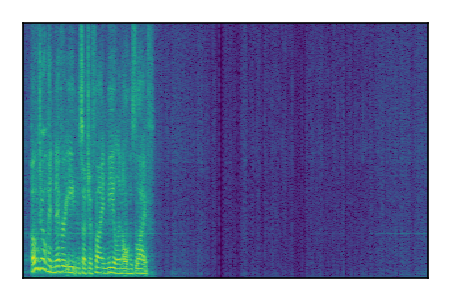
|
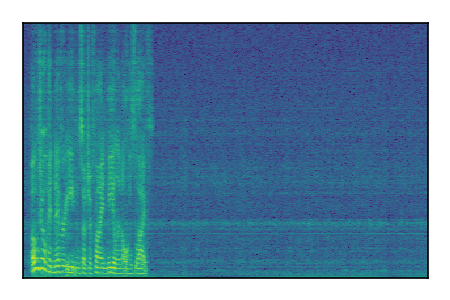
|
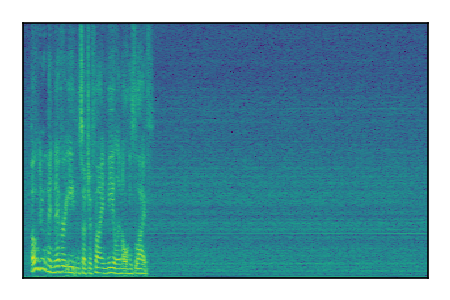
|
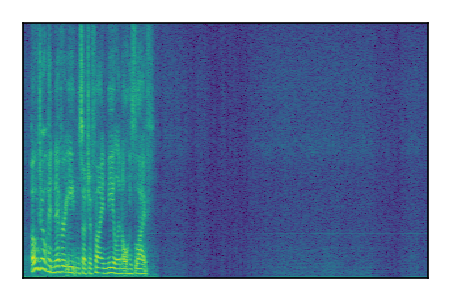
|
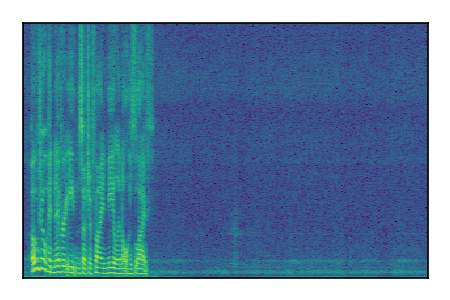
|
||

|
|
|
|
|
|
||

|
|
|
|
|
|
||
| 7 |
|
|
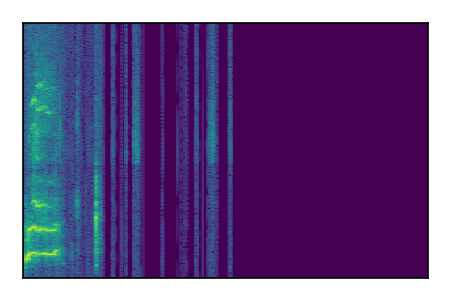
|
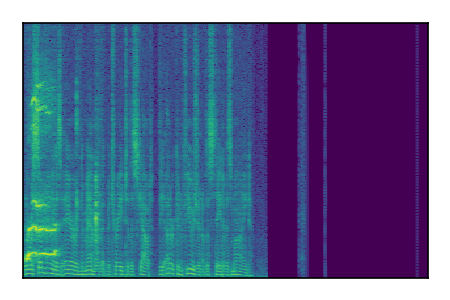
|
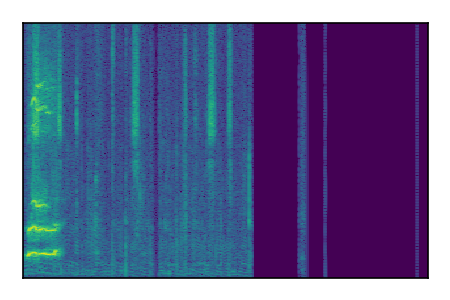
|
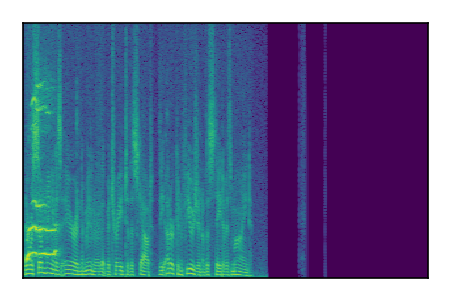
|
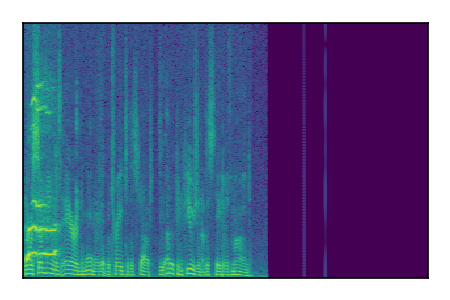
|
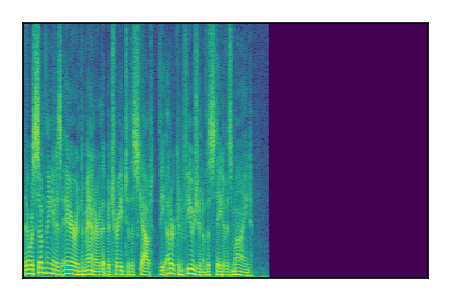
|
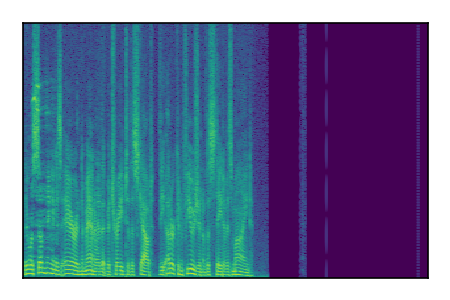
|
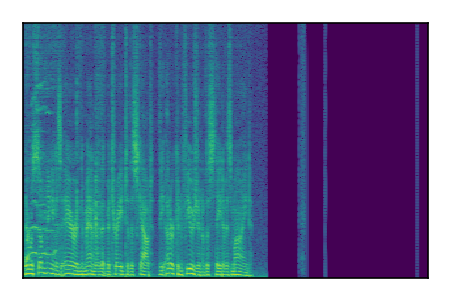
|
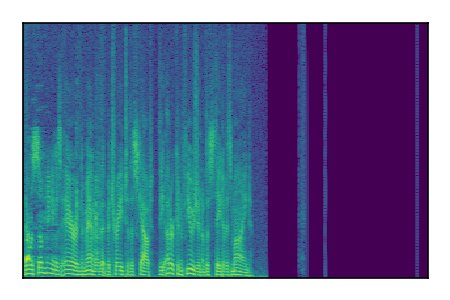
|
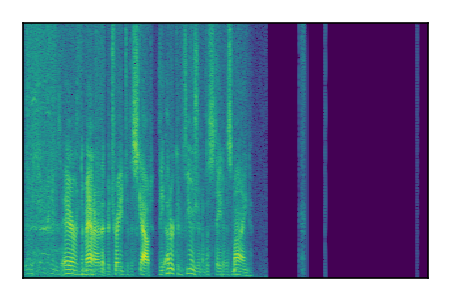
|
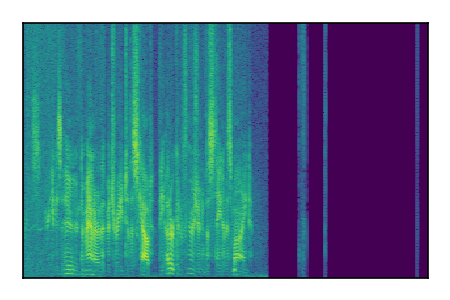
|
||

|
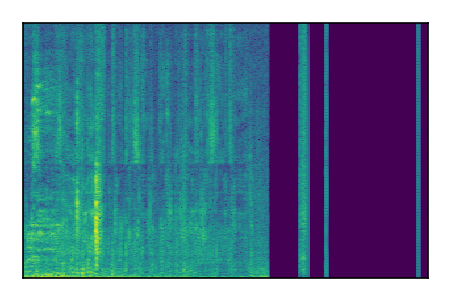
|
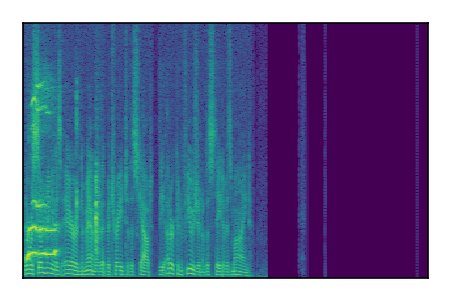
|
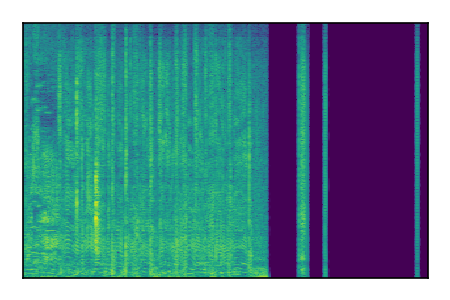
|
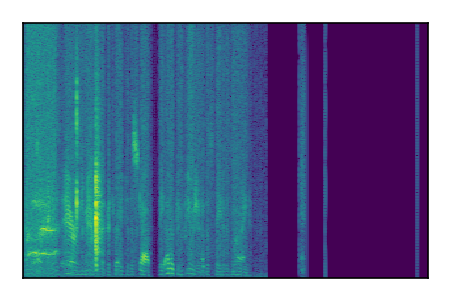
|
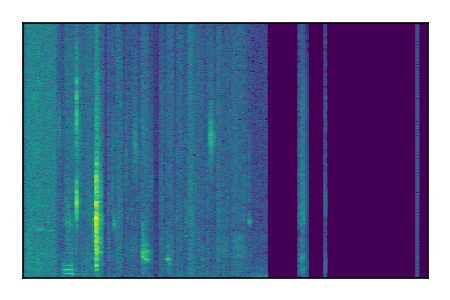
|
||

|
|
|
|
|
|
||
| 8 |
|
|
|
|
|
|
|
|
|
|
|
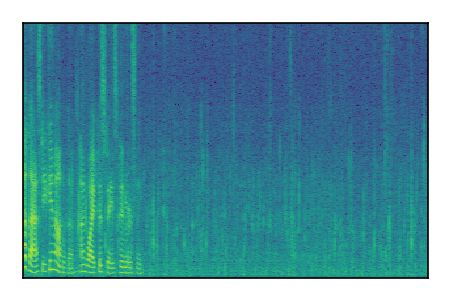
|
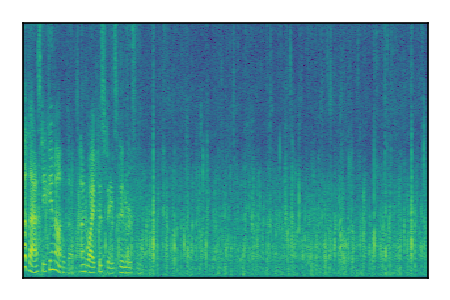
|
||

|
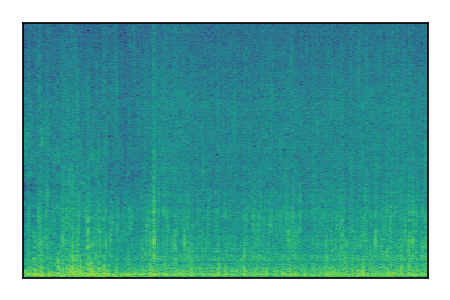
|
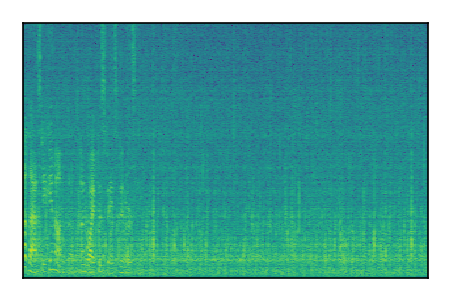
|
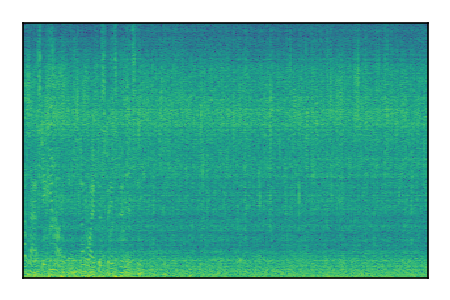
|
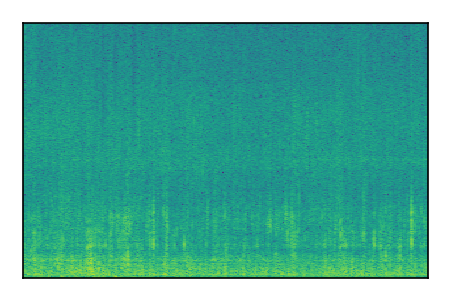
|
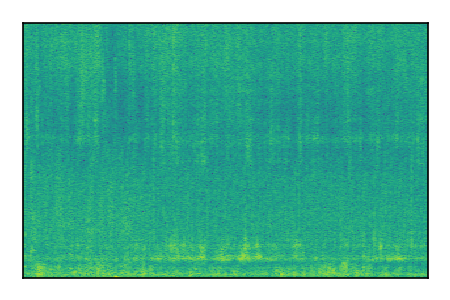
|
||

|
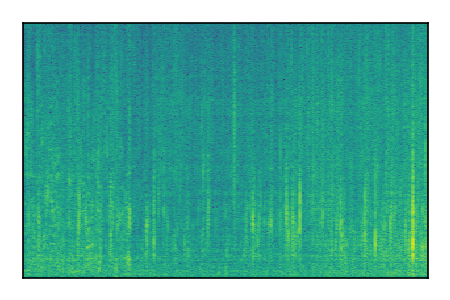
|
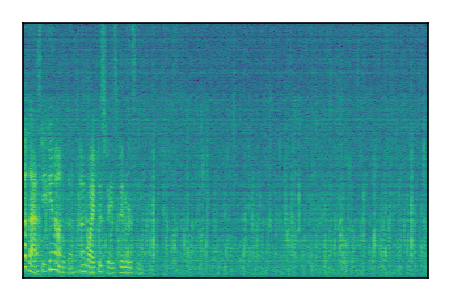
|
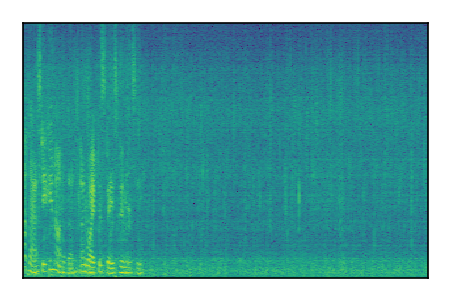
|
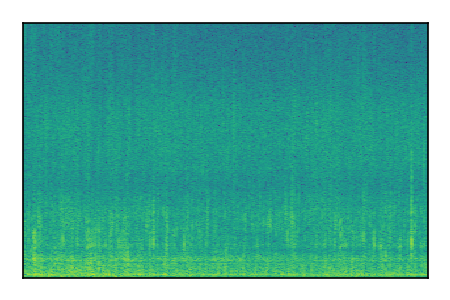
|
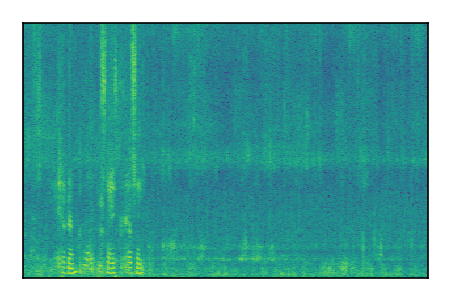
|
||
| 9 |
|
|
|
|
|
|
|
|
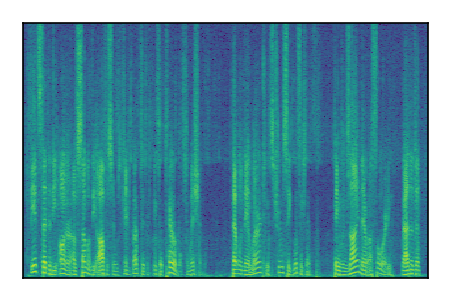
|
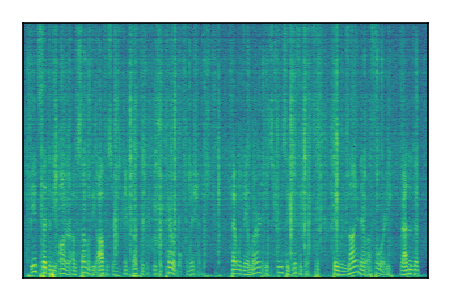
|
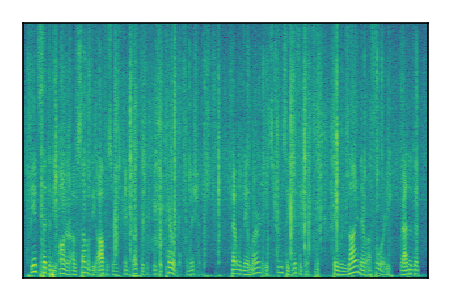
|
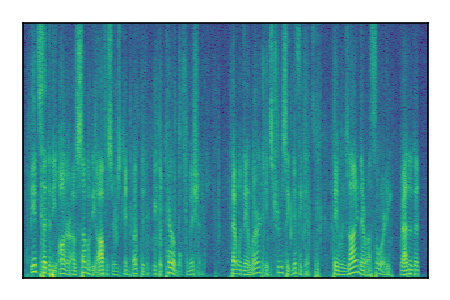
|
|
||

|
|
|
|
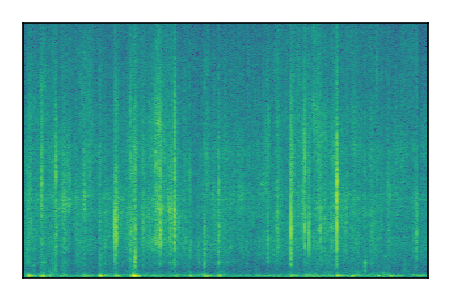
|
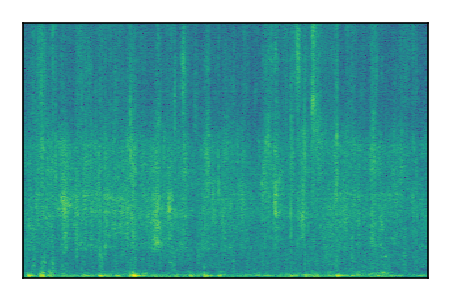
|
||

|
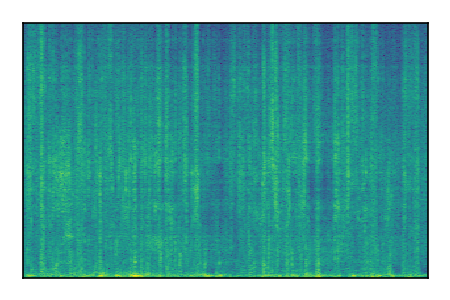
|
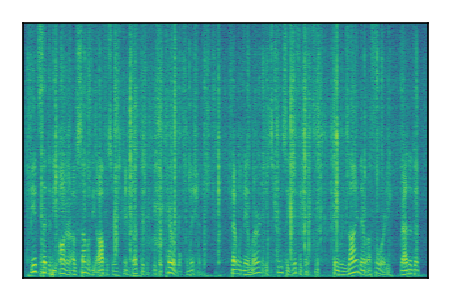
|
|
|
|
||
| 10 |
|
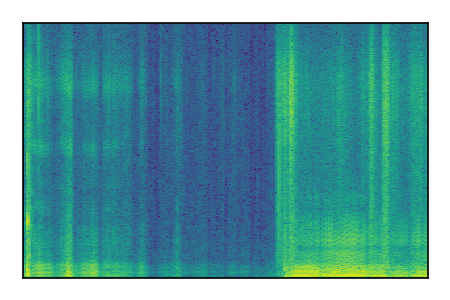
|
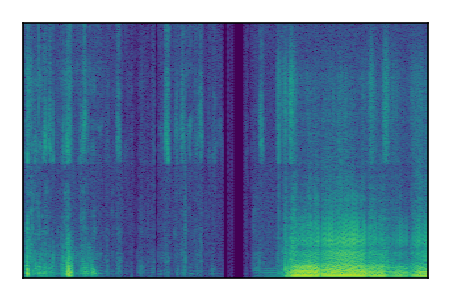
|
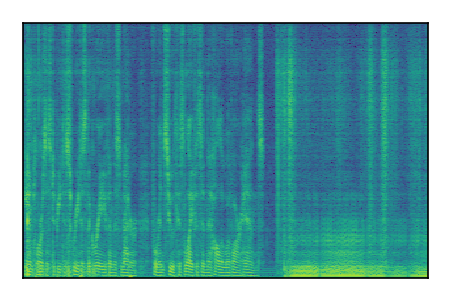
|
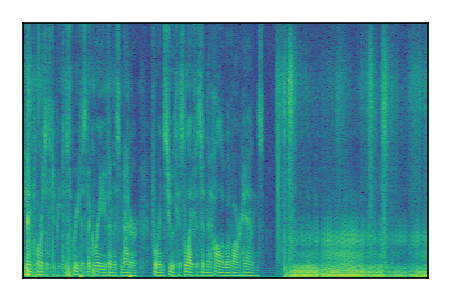
|

|
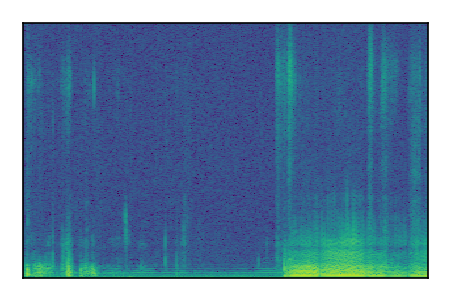
|
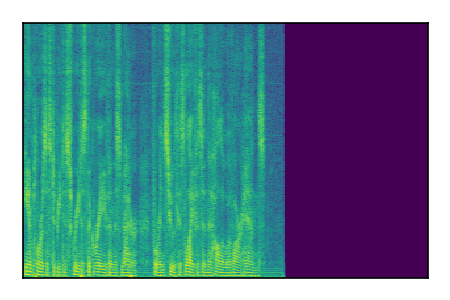
|
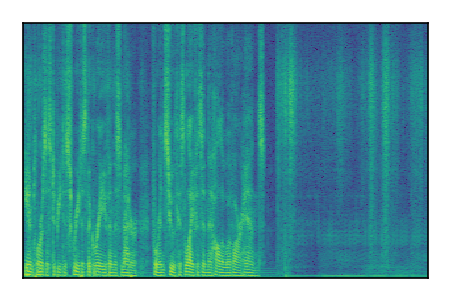
|
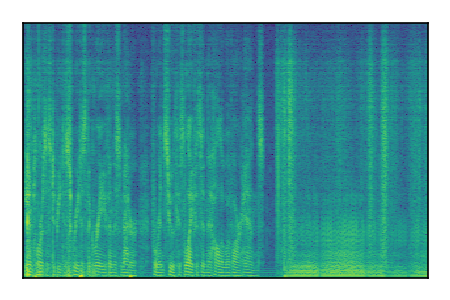
|
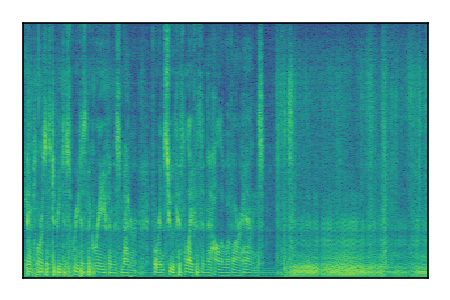
|
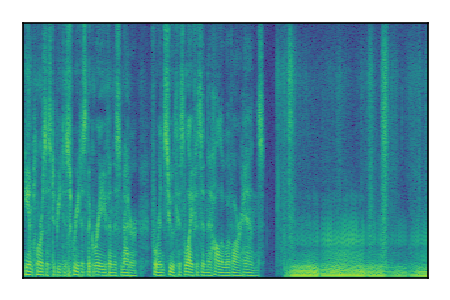
|
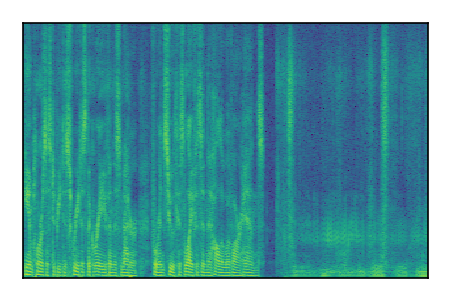
|
||

|
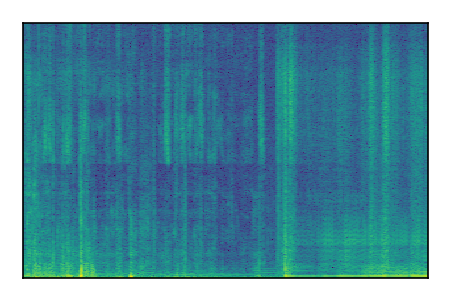
|
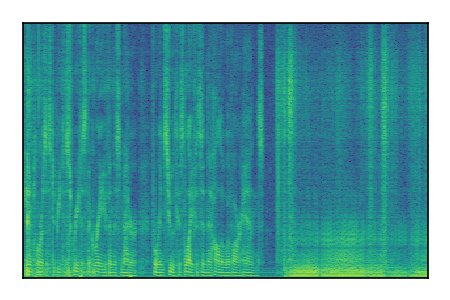
|
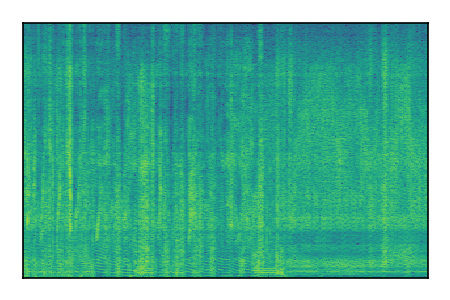
|
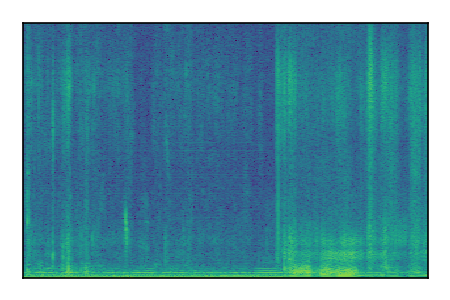
|
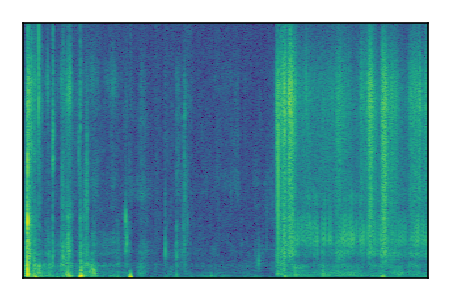
|
||

|
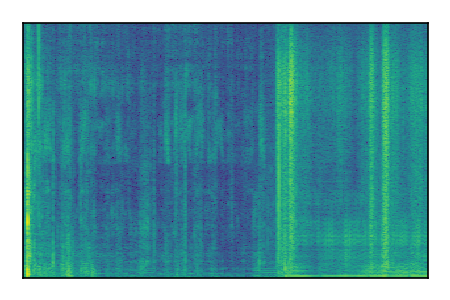
|
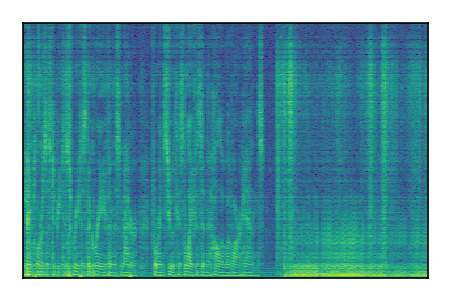
|
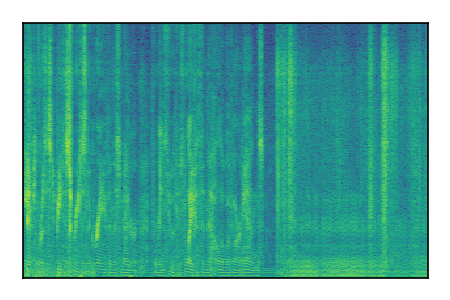
|
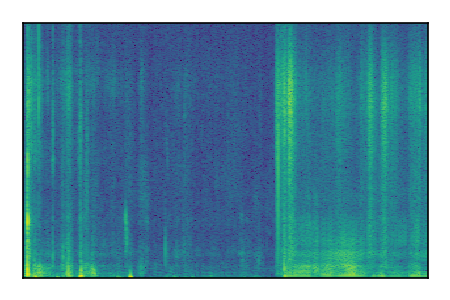
|
|
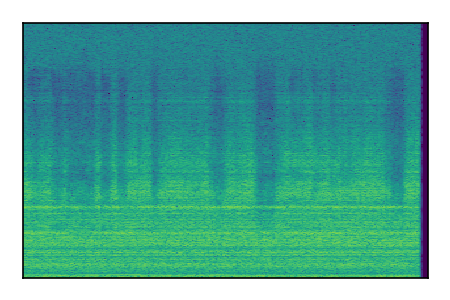
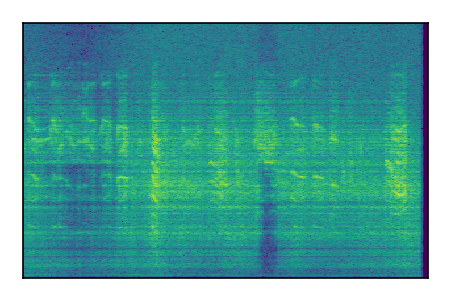
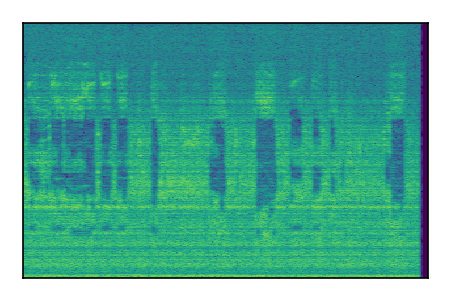
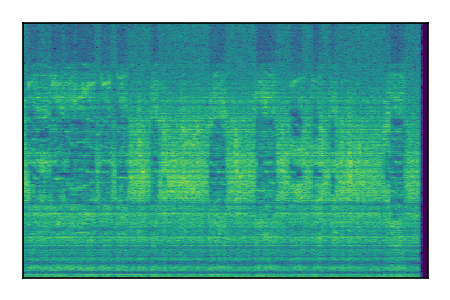
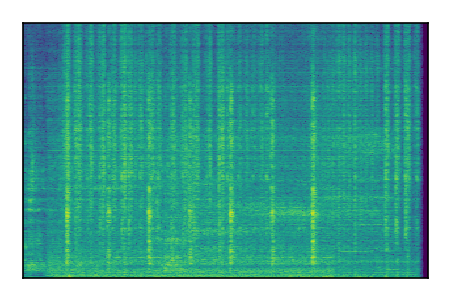
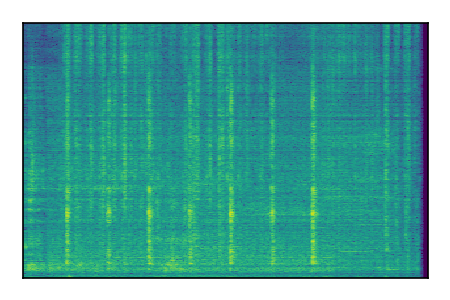
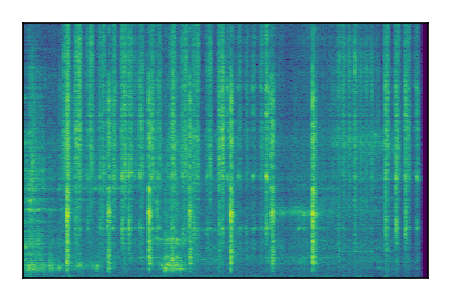
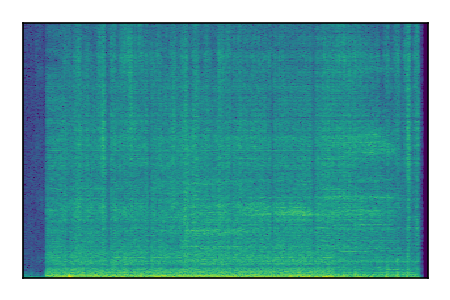
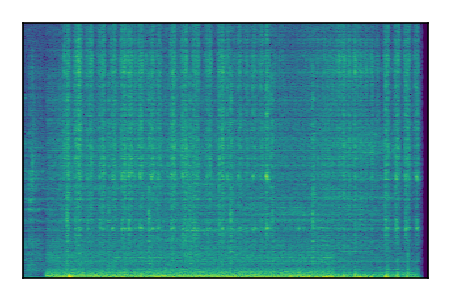
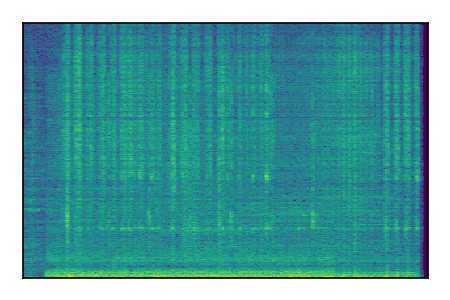
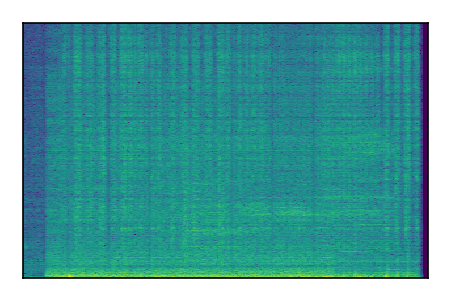
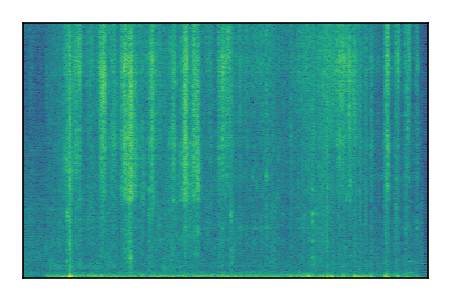
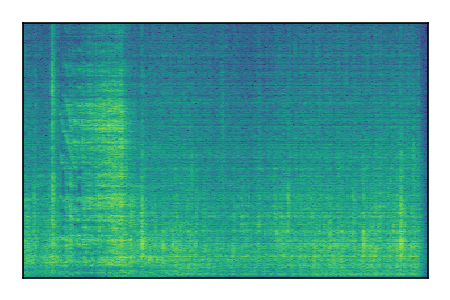
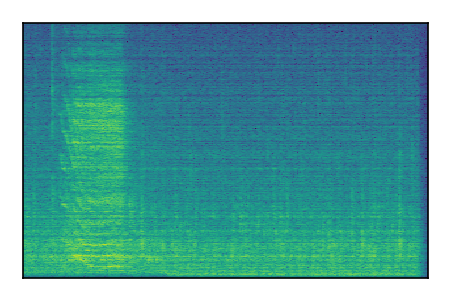
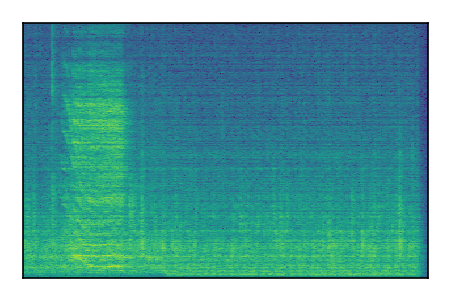
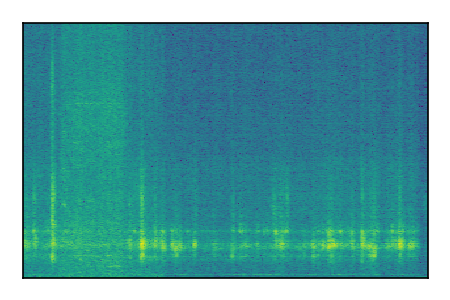
FUSS: Universal Source Separation
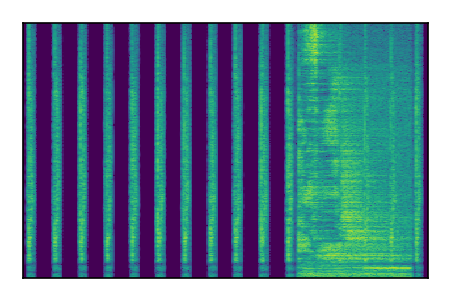
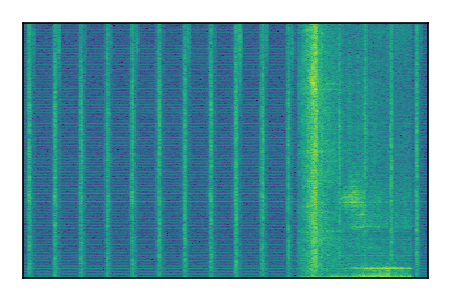
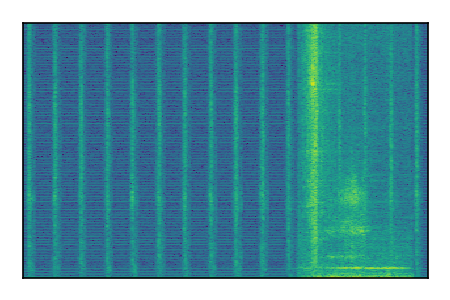
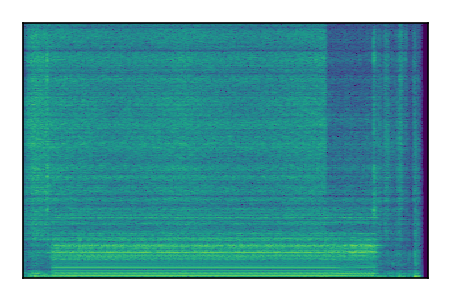
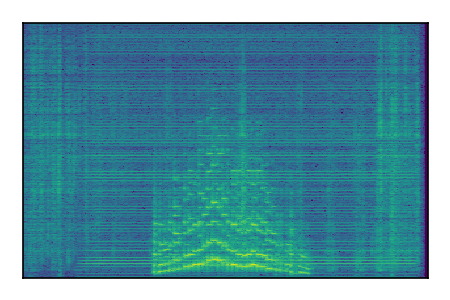
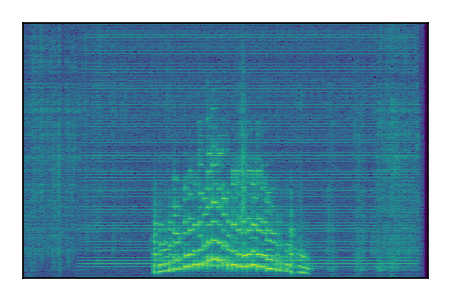
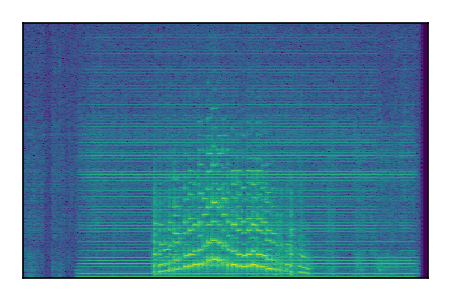
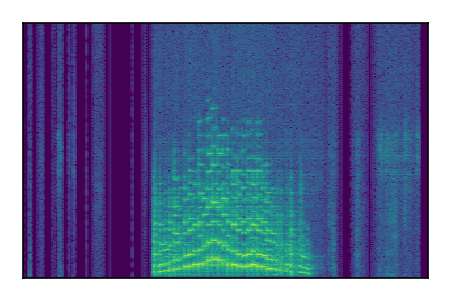
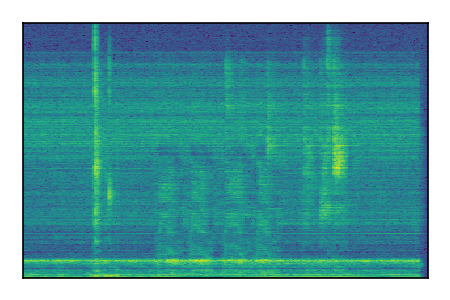
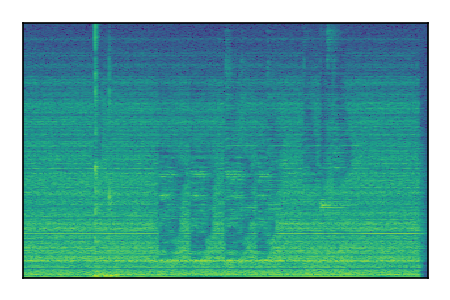
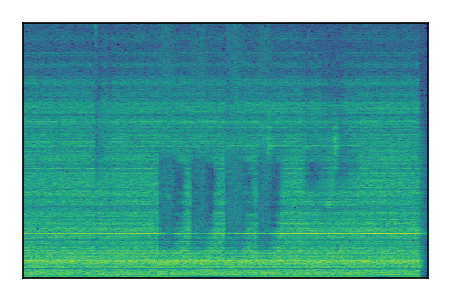
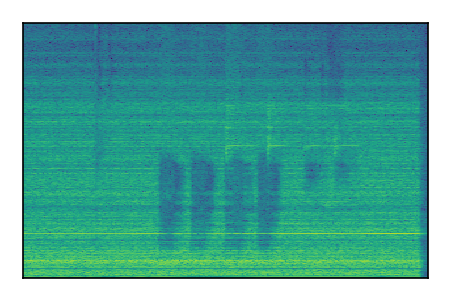
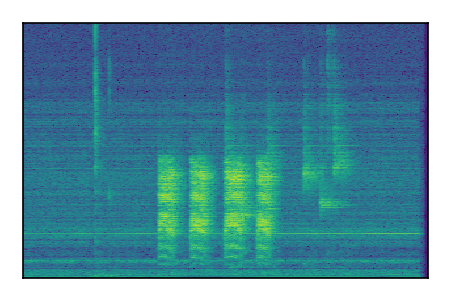
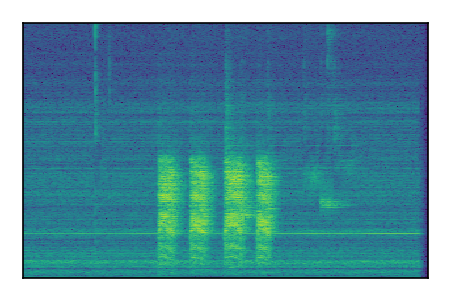
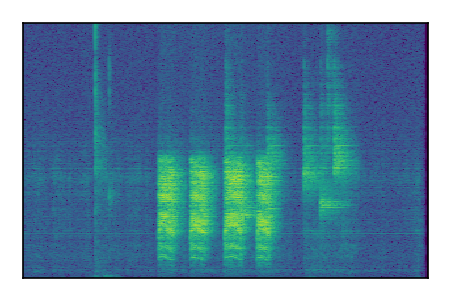
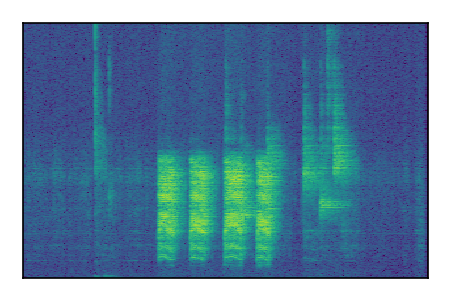
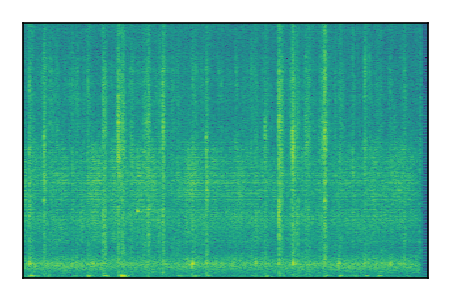
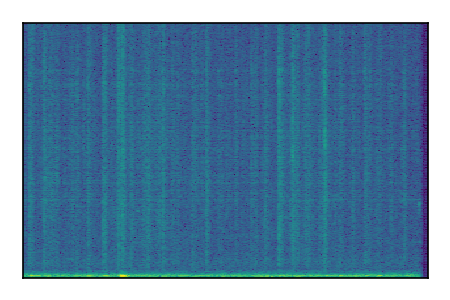
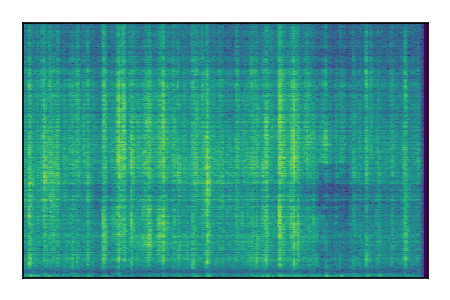
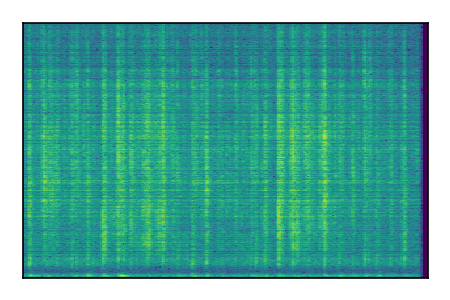
Separation of mixtures of general sounds from FUSS. The model is trained on AudioSet.
| Sample | Mixture | Targets | MixIT ConvTasNet | ReMixIT Regression | Self-Remixing Regression | ReMixIT Flow | Self-Remixing Flow |
|---|---|---|---|---|---|---|---|
| 1 |
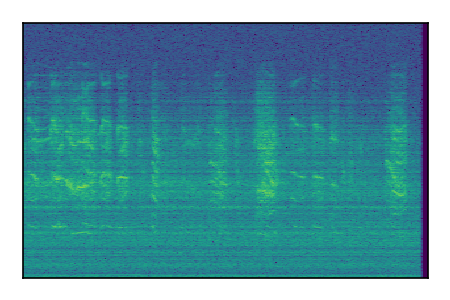
|
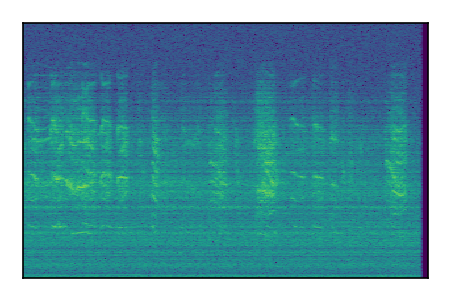
|
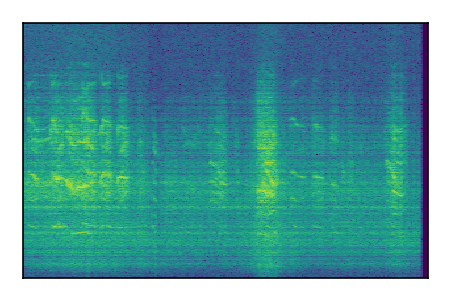
|
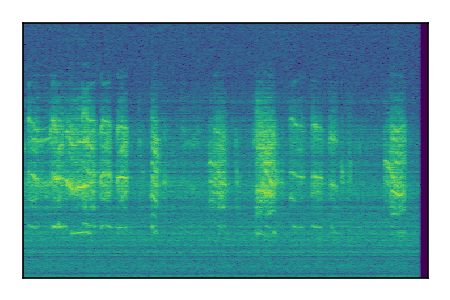
|
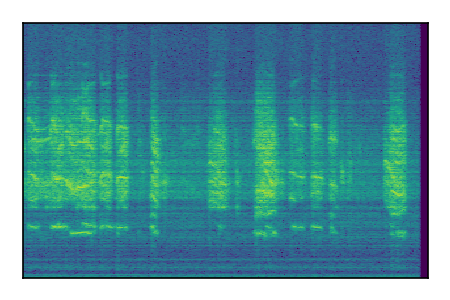
|
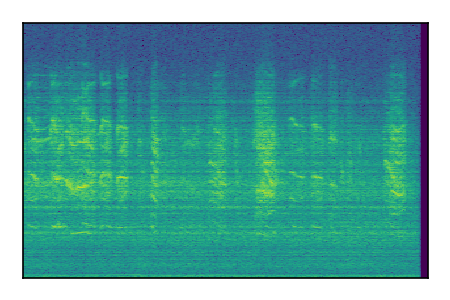
|
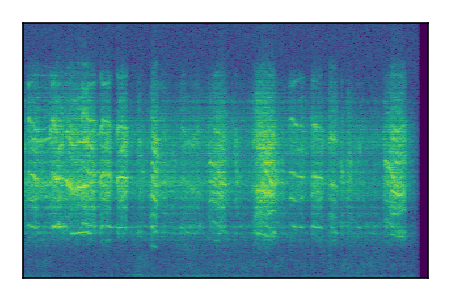
|

|
|
|
|
|
|
||

|
|
|
|
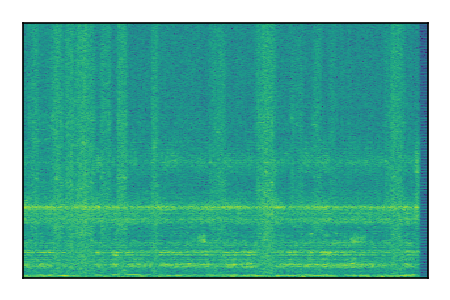
|
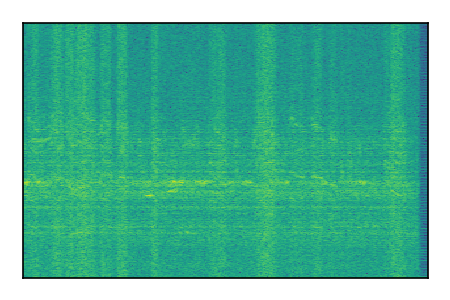
|
||

|
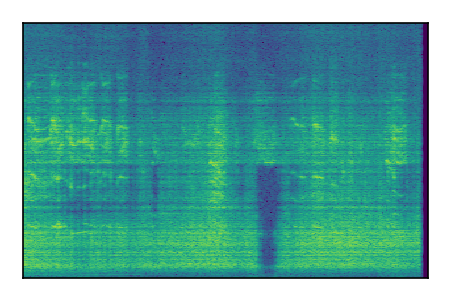
|
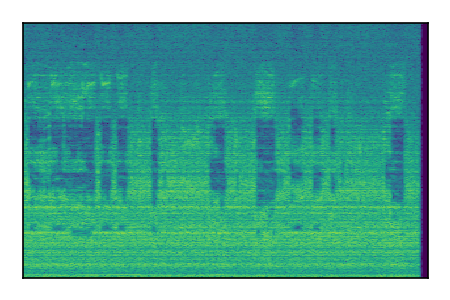
|
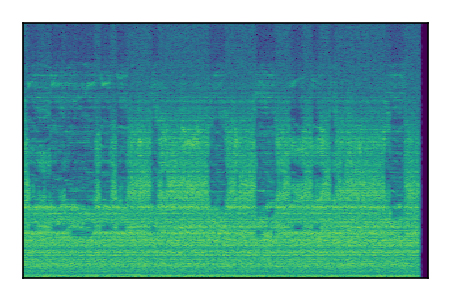
|
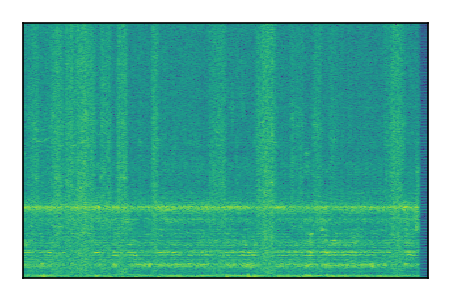
|
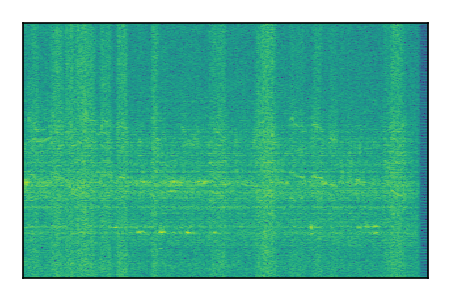
|
||
| 2 |
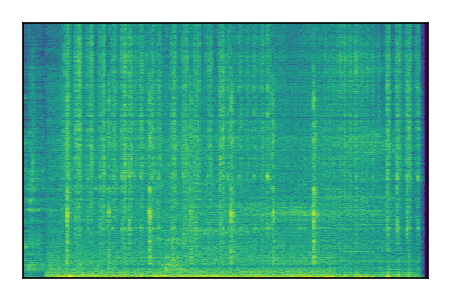
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
||
|
|
|
|
|
|
||
| 3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
||

|
|
|
|
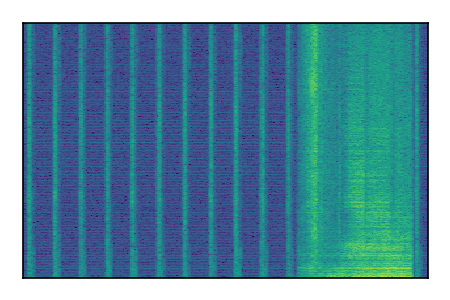
|
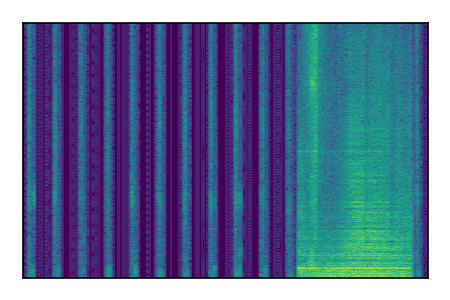
|
||

|
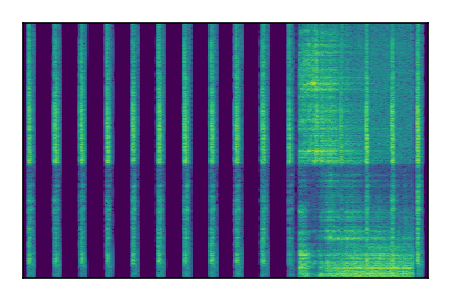
|
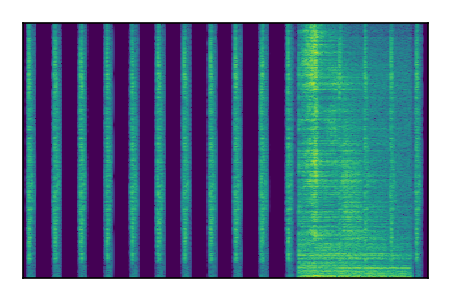
|
|
|
|
||
| 4 |
|
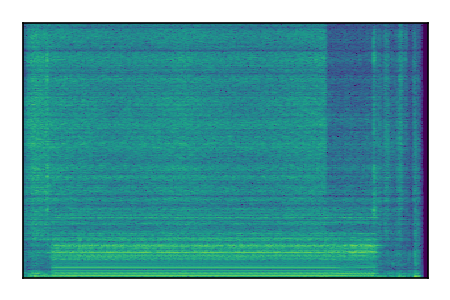
|
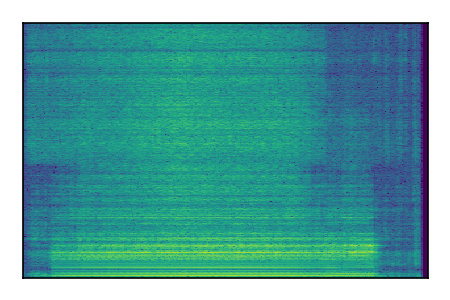
|
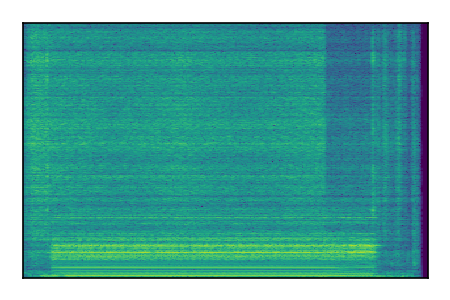
|
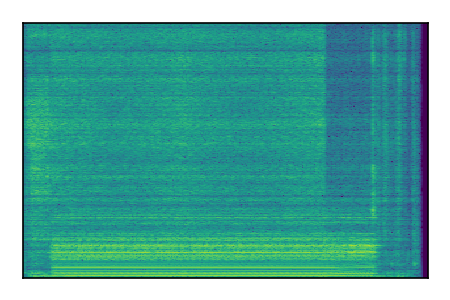
|
|
|

|
|
|
|
|
|
||

|
|
|
|
|
|
||

|
|
|
|
|
|
||
| 5 |
|
|
|
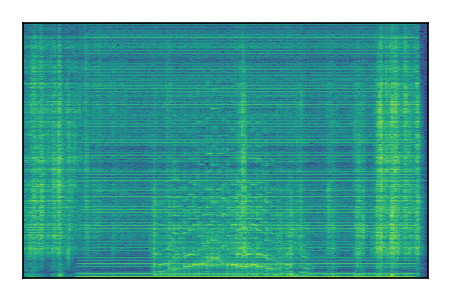
|
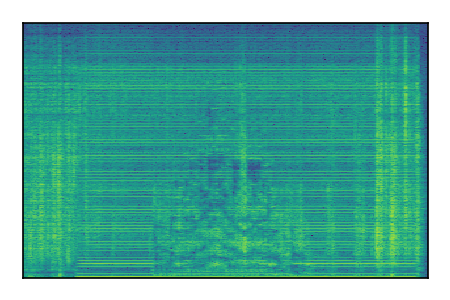
|
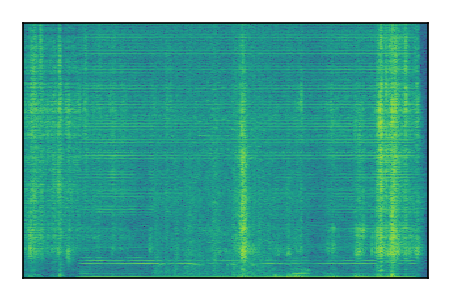
|
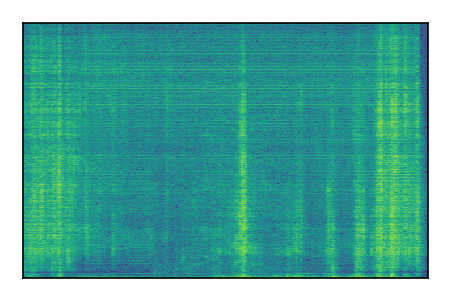
|
|
|
|
|
|
|
||
|
|
|
|
|
|
||

|
|
|
|
|
|
||
| 6 |
|
|
|
|
|
|
|
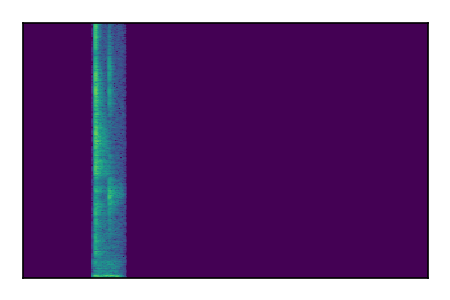
|
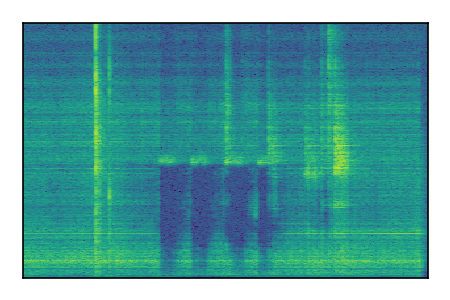
|
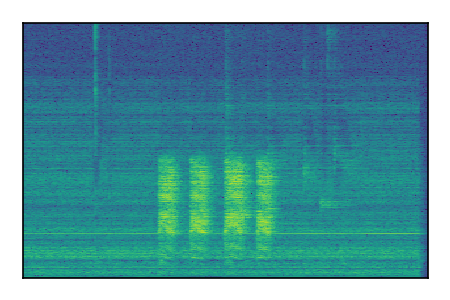
|
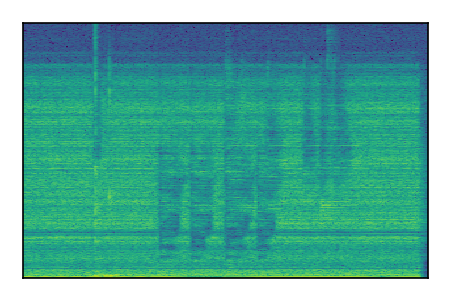
|
|
|
||
|
|
|
|
|
|
||
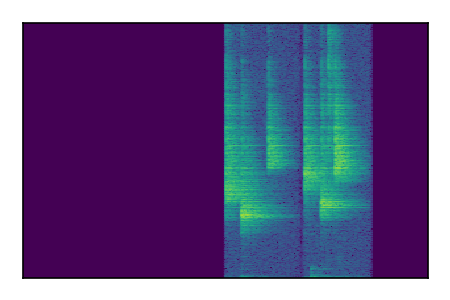
|
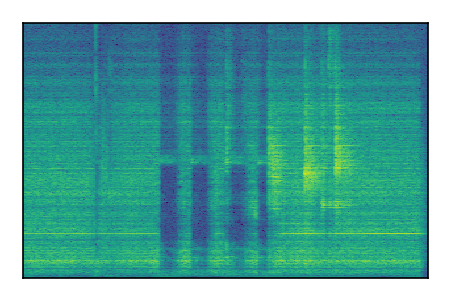
|
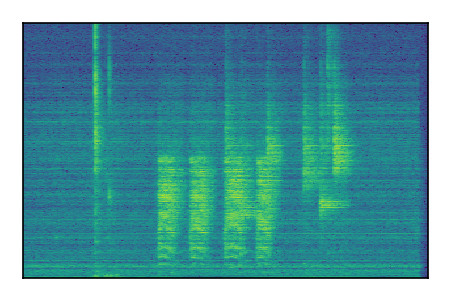
|
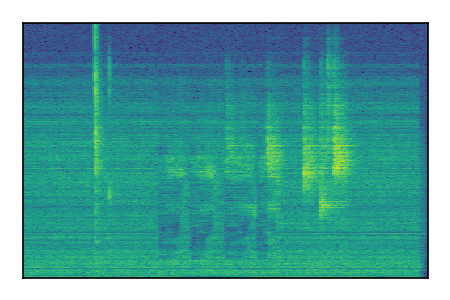
|
|
|
||
| 7 |

|

|
|
|
|
|
|

|

|

|

|

|

|
||

|

|
|
|
|
|
||

|
|

|

|
|
|
||
| 8 |
|
|
|
|
|
|
|
|
|
|
|
|
|
||

|
|
|
|
|
|
||

|
|
|
|
|
|
||
| 9 |
|
|
|
|
|
|
|

|
|
|
|
|
|
||

|
|
|
|
|
|
||

|
|
|
|
|
|
||
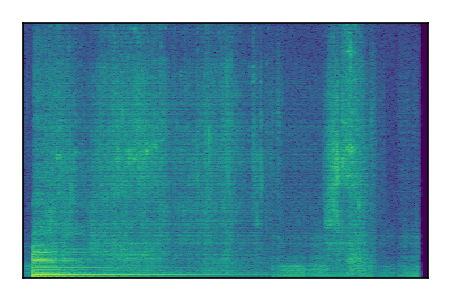
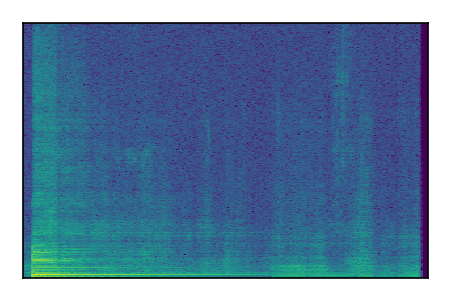
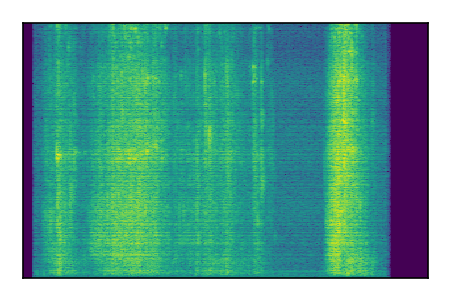
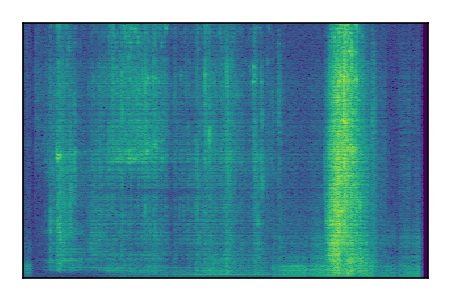
| 10 |
|
|
|
|
|
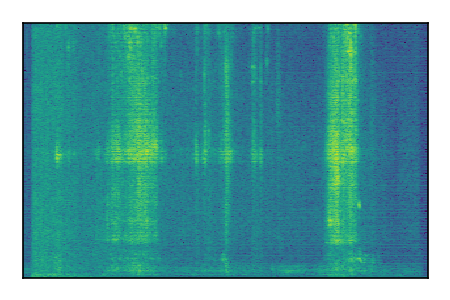
|
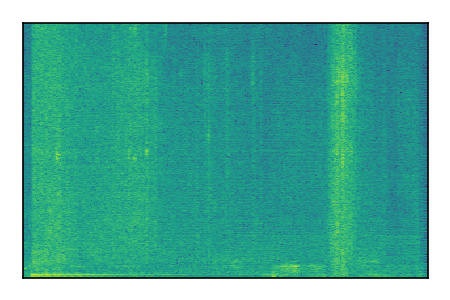
|
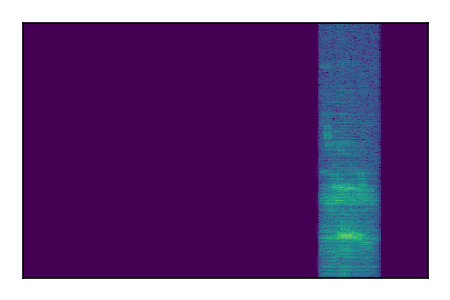
|
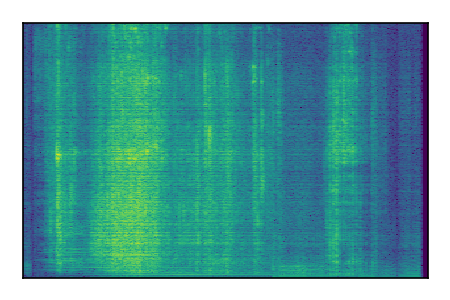
|
|
|
|
|
||
|
|
|
|
|
|
||
|
|
|
|
|
|