DSPL 2.0
Contact: Omar Benjelloun, Natarajan Krishnaswami
Last updated: 2019-07-09
Introduction
The DSPL2 open format represents the structure and content of statistical datasets in a simple, standards-compatible way that enables Search engines and other data exploration tools to provide useful functionality to users.
DSPL2 focuses on “statistical” datasets, i.e., datasets that contain aggregated numerical measures over dimensions such as location or demographic attributes. The data is generally provided as time series. This format may also be useful for other types of datasets.
Some of the key ideas of DSPL2:
- The format should be compatible with schema.org and build on schema.org/Dataset
- Data for time series and code lists is primarily represented as CSV files
- Any statistics dataset can be described, regardless of pre-existing shared schema
- DSPL2 datasets have a clear graph representation (even if data is provided in CSV)
- Entities and properties from existing vocabularies can be reused
Non-goals of this document:
- Mapping to existing formats and standards: SDMX, W3C RDF data cube, DSPL, etc. Interoperability with other formats is important, and will be covered in future revisions.
- Shared concepts across datasets (à la SDMX Content guidelines) will be defined in future revisions.
- Shared annotations will be defined in future revisions.
- Nested dimensions will be defined in future revisions.
Background
DSPL2 builds on a number of existing formats and vocabularies:
- DSPL: The existing Google format for public statistics, used by Public Data Explorer and Search. DSPL2 is based on a similar data model, and will eventually replace DSPL
- Schema.org/Dataset (for reference metadata)
DSPL2 is closely related to the following formats and standards that address dataset authoring:
- Statistical Data and Metadata eXchange: SDMX is an “an ISO standard designed to describe statistical data and metadata, normalise their exchange, and improve their efficient sharing across statistical and similar organisations”. It is typically expressed in XML, though other formats have been specified.
- Content-Oriented Guidelines: A key component of the SDMX standards package are the COGs, a set of cross-domain concepts, code lists, and categories that support interoperability and comparability between datasets by providing a shared terminology between SDMX implementers. DSPL 2.0 does not describe an analogous shared concrete vocabulary.
- RDF Data Cube: DSPL 2.0 takes the terminology of slices, dimensions and measures from RDF Data Cube. A longer term goal may be to support generating RDF Data Cube triples from DSPL 2.0 datasets.
- Data Package: Data Package is simple container format used to describe and package a collection of data. Data Packages can be used to package any kind of data.
- Tabular Data Package: At the same time, for specific common data types such as tabular data it has support for providing important additional descriptive metadata – for example, describing the columns, keys, and data types in a CSV. DSPL 2.0 is more tightly specialized for statistical data, requiring the dataset contents have specific semantics (measures, dimensions, slices, etc) than tabular data packages.
- DataCommons/S: DataCommons also models statistical facts using schema.org vocabulary, but uses strong typing, so what DSPL 2.0 models as generic dimensions or measures are expressed using specific schema types and properties.
- JSON-stat: JSON-stat is very similar, with a key difference being the use of a custom JSON schema rather than JSON-LD
- OGC Observations & Measurements: O&M is defined using UML, with mappings specified to XML and JSON implementations. OGC O&M has a richer data model, including support for categorical timeseries data, non-timeseries data, and sampled data; and data interpolation, quality annotation, and censoring
- TimeSeriesML: TSML is an XML implementation of the O&M Timeseries profile
- CSVW: CSVW allows specification of metadata for CSV tables such as key columns and mappings to triples. DSPL 2.0 relies on schema.org properties and conventions for CSV header names. Support for CSVW mappings could be added as a future enhancement
Overview
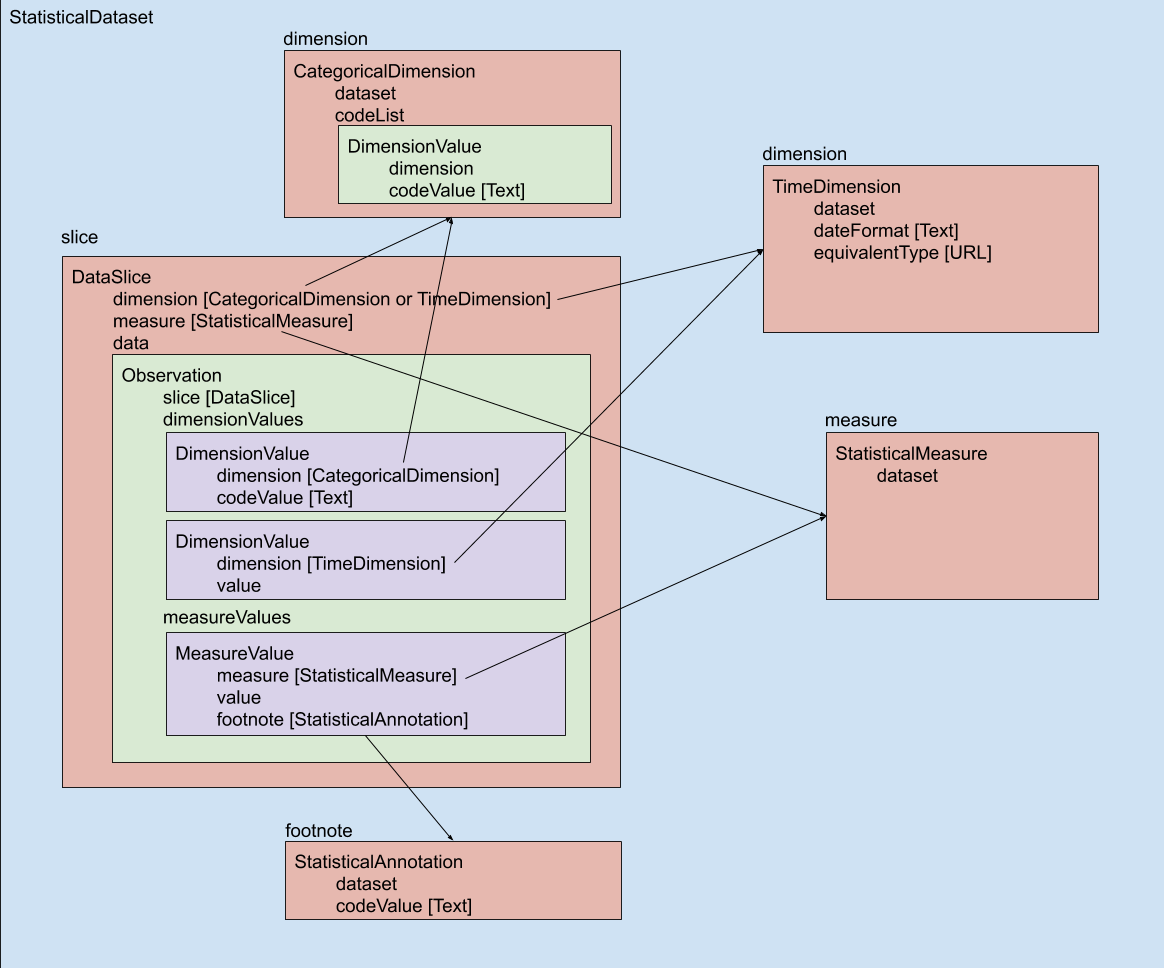
We introduce the following constructs:
- StatisticalDataset: A dataset that contains statistical data and the associated metadata
- StatisticalMeasure: A quantifiable phenomenon or indicator being observed or calculated (e.g., average rainfall, population, percentage of forested land, …)
- TableMapping: A descriptor for mapping dimensions, measures, and dimension properties to specific CSV columns.
- CategoricalDimension: A category of “things” that a measure can apply to. For example, countries, genders, or age groups. A categorical dimension is associated with a codelist that enumerates its possible values.
- TimeDimension: A time dimension that a measure can apply to. For example, the date of a measurement, or the beginning or end of a duration.
- DimensionProperty: A descriptor for an additional property to populate on the DimensionValues for a dimension.
- DataSlice: A container for statistical data. A slice contains related observations of the same set of measures for the same dimensions. For example, population by year, country, and age group.
- Observation: A “data point” with one or more measure values for specified dimension values.
- DimensionValue: A possible or observed value for a given dimension.
- MeasureValue: The observed value of a measure.
- StatisticalAnnotation: An explanatory or methodological annotation for a measurement.
While most of the constructs above describe “metadata” about the dataset, we also need to represent actual data. The preferred way of providing this data is to use CSV tables. An equivalent triple representation is also supported.
Notes
Provenance
Many statistical datasets include data from multiple providers. The CreativeWork superclass for StatisticalDataset offers support for multiple authors and publishers at the dataset level, but does not address provenance for individual measures or timeseries observations. This is important for data aggregators, so it may be desirable to add support for provenance at a finer granularity in the future.
Identifiers
JSON-LD objects can be assigned URIs (or rather, IRIs) using the @id property. Within a file, these can refer to the file’s location using an empty identifier, or document-unique IDs using fragments like #age_year_slice. This can be used to give permanent identifiers to datasets, their dimensions, measures, and annotations, and to the timeseries within them.
Schema
A draft of the schema additions is at dspl2.jsonld. (The schema should follow this document; any discrepancies are errors.)
Vocabulary
StatisticalDataset
Thing > CreativeWork > Dataset > StatisticalDataset
A dataset that contains statistical data. It has the following properties, in addition to those available to a Dataset:
| Property | Expected type | Description |
| measure | StatisticalMeasure | A measure defined in this dataset. |
| dimension | CategoricalDimension or TimeDimension | A dimension defined in the dataset. |
| annotation | StatisticalAnnotation or URL | an annotation defined in this dataset, or the URL of a CSV table containing the annotation definitions. See section “[Annotations](#annotations)” for more details. |
| slice | DataSlice | A slice defined in this dataset. |
| footnote | PropertyValue | A footnote applying to this dataset. |
Examples
{
"@type": "StatisticalDataset",
"@id": "#europe_unemployment",
"name": "Unemployment in Europe (monthly)",
"description": "Harmonized unemployment data for European countries.",
"url": "http://epp.eurostat.ec.europa.eu/portal/page/portal/lang-en/employment_unemployment_lfs/introduction",
"license": "https://ec.europa.eu/eurostat/about/policies/copyright",
"creator":{
"@type":"Organization",
"url": "https://ec.europa.eu/eurostat",
"name":"Eurostat",
},
"temporalCoverage":"1993-01/2010-12",
"spatialCoverage":{
"@type":"Place",
"geo":{
"@type":"GeoShape",
"name": "European Union",
"box":"34.633285 -10.468556 70.096054 34.597916"
}
},
"measure": …,
"dimension": …,
"annotation": …,
"slice": …
}
StatisticalMeasure
Thing > Intangible > StatisticalMeasure
A quantifiable phenomenon or indicator being observed or calculated (e.g., average rainfall, population, percentage of forested land, …) .
| Property | Expected type | Description |
| dataset | Dataset | A dataset where this measure is defined. |
| unitCode | Text or Url | The unit of measurement given using the UN/CEFACT Common Code (3 characters) or a URL. Other codes than the UN/CEFACT Common Code may be used with a prefix followed by a colon. |
| unitText | Text | A string or text indicating the unit of measurement. Useful if you cannot provide a standard unit code for unitCode. |
| footnote | PropertyValue | A footnote applying to this measure. |
Examples
{
"@type": "StatisticalMeasure",
"@id": "#unemployment_rate",
"dataset": "#europe_unemployment",
"sameAs": "https://www.wikidata.org/wiki/Q1787954",
"name": [
{ "@value": "Unemployment rate (monthly)", "@language": "en" },
{ "@value": "Arbeitslosenquote (monatlich)", @language": "de" },
],
"description": "The unemployment rate represents unemployed persons as a percentage of the labour force. The labour force is the total number of people employed and unemployed.",
"url": "http://ec.europa.eu/eurostat/product?code=une_rt_m&language=en",
"unitCode": "P1"
}
DimensionProperty
Type: Thing > Intangible > DimensionProperty
Categorical dimensions can have additional properties than the ones defined above. Each of these should have a DimensionProperty describing its name and type.
| Property | Expected type | Description |
| propertyID | Text | The name of the property in a `DimensionValue`. |
| propertyType | rdfs:Class or CategoricalDimension | The type to use for the property's value, if using CSV files for slice data. |
If the propertyType is the ID of a CategoricalDimension, the corresponding slice CSV values must be code values from that dimension’s codeList.
If it is one of the schema:DataType types, the corresponding slice CSV values must be of that type.
Otherwise, the type’s properties may be specified using a column named [*propertyID*].[*property of propertyType*], with [*propertyID*] alone being equivalent to [*propertyID*].name.
For example, for the following DimensionProperty:
{
"@type": "DimensionProperty",
"propertyID": "geo",
"propertyType": "GeoCoordinates"
}
The corresponding columns in a slice data CSV file might look like:
…,geo.latitude,geo.longitude
…,32.318231,-86.902298
…,63.588753,-154.493062
…,34.048928,-111.093731
…,35.20105,-91.831833
TableMapping
Type: Thing > Intangible > TableMapping
This specifies the mapping from an entity to a particular header column name in a CSV file.
| Property | Expected type | Description |
| sourceEntity | URL | The entity (Dimension, Measure, DimensionProperty) whose column name is being specified. |
| columnIdentifier | Text | The column name in a related CSV corresponding to this property. |
| value | DataType | The value to use for the specified `sourceEntity`; this specifies a constant-valued virtual column. |
CategoricalDimension
Type: Thing > Intangible > CategoricalDimension
Categorical dimensions define the categories that measures can apply to. For instance, countries, genders, age groups, etc. A categorical dimension has a list of possible categories or values, called a codeList (see below).
A categorical dimension may correspond to an existing (schema.org) type, in which case that type should be set as the dimension’s equivalentType. The values in the codeList may specify that they have that type and set any of its properties.
| Property | Expected type | Description |
| dataset | Dataset | A dataset where this dimension is defined. |
| equivalentType | URL | The type of the DimensionValue objects for this dimension |
| dimensionProperty | DimensionProperty | Type information for each additional property to use on this dimension's `DimensionValue`s. |
| parentProperty | DimensionProperty | The ID of a dimensionProperty for this dimension's parent dimension. |
| tableMapping | TableMapping | Column mappings for `dimensionProperty` `propertyID`s to `codeList` CSV header names. |
| codeList | DimensionValue or URL | The code values and additional properties for this dimension or the URL of a CSV file containing them. |
| footnote | PropertyValue | A footnote applying to this dimension. |
When a code list is provided as a table, the data in the CSV table must follow these conventions:
- The first row of the table is a header that contains the names the columns.
- Each value corresponds to one row in the table. All possible values of the
codeListmust appear in the table. - The first column is called “codeValue”, and contains the code for each value.
- Each subsequent column has the name of the property it represents.
- For properties specified in
dimensionProperty- If a
tableMapping is present, thetableMapping'scolumnIdentifier` is the column name. - Otherwise, the
propertyIDis the column name.
- If a
- If the values are in a specific language, the code of the language should be used as a suffix, e.g., “name@en”.
- For properties specified in
If a tableMapping has a value property, this is used instead of the corresponding column in the CSV file, if present.
If a single parentProperty is specified and refers to a DimensionProperty whose propertyType is a CategoricalDimension, that dimension is called the parent dimension for this dimension, and its values are the parent values for the DimensionValues they occur in.
Examples
Below, the dimension’s values are defined in “genders.csv”.
{
"@type": "CategoricalDimension",
"@id": "#gender",
"dataset": "#europe_unemployment",
"codeList": "genders.csv"
}
Where the CSV table might begin like this:
"codeValue","name@en","name@fr","name@de"
"f","Women","Femmes","Frauen"
"m","Men","Hommes","Männer"
"nb","Non-binary","Non-binaire","Nichtbinär"
"tm","Transmasculine","Transmasculin","Transmaskulin"
"tf","Transfeminine","Transféminine","Transfeminin"
"ag","Agender","Agenre","Agender"
These have a parent-child relationship:
{
"@type": "CategoricalDimension",
"@id": "#country_group",
"dataset": "#europe_unemployment",
"codeList": [{
"@type": "DimensionValue",
"@id": "#country_group=eu",
"dimension": "#country_group",
"codeValue": "eu",
"name": "European Union members"
}, {
"@type": "DimensionValue",
"@id": "#country_group=non-eu",
"dimension": "#country_group",
"codeValue": "non-eu",
"name": "non-European Union members"
}
},
{
"@type": "CategoricalDimension",
"@id": "#country",
"dataset": "#europe_unemployment",
"dimensionProperty": {
"@type": "DimensionProperty",
"@id": "#country_group_property",
"propertyID": "country_group",
"propertyType": "#country_group"
},
"parentProperty": "#country_group_property",
"codeList": "countries.csv"
}
This demonstrates a virtual parent column:
{
"@type": "CategoricalDimension",
"@id": "#state",
"dataset": "",
"name": "US States",
"equivalentType": "State",
"dimensionProperty": [{
"@type": "DimensionProperty",
"@id": "#countryProperty",
"propertyID": "containedInPlace",
"propertyType": "#country"
}, {
"@type": "DimensionProperty",
"description": "The centroid of the state.",
"propertyID": "geo",
"propertyType": "GeoCoordinates"
}],
"parentProperty": "#countryProperty",
"tableMapping": {
"@type": "TableMapping",
"sourceEntity": "#countryProperty",
"value:": "US"
},
"codeList": "states.csv"
}
Where CSV file countries.csv has a column country_group with values of eu or non-eu.
TimeDimension
Type: Thing > Intangible > TimeDimension
Time dimensions define times that time series measures apply to. For instance, years, years with quarters, dates, datetimes, etc.
A time dimension may correspond to an existing (schema.org) type, in which case that type should be set as the dimension’s equivalentType. The dateFormat property indicates how to parse timestamps in slice observations, for slices with observations in CSV files.
| Property | Expected type | Description |
| dataset | Dataset | A dataset where this dimension is defined. |
| equivalentType | URL | The type of the DimensionValue objects for this dimension. |
| dateFormat | Text | A CLDR date format pattern to use for parsing values from a slice CSV file into the dimension’s equivalentType. See http://www.unicode.org/reports/tr35/tr35-dates.html#Date_Format_Patterns for details on these patterns. |
| footnote | PropertyValue | A footnote applying to this dimension. |
Examples
{
"@type": "TimeDimension",
"@id": "#month",
"dataset": "#europe_unemployment",
"equivalentType": "xsd:gYearMonth",
"dateFormat": "yyyy/MM"
}
StatisticalAnnotation
Thing > Intangible > StatisticalAnnotation
Many statistical datasets use annotate values in observations with annotations to provide contextual explanations or methodological details. The inherited properties (e.g., name, description, and URL) can be used to provide details.
| Property | Expected type | Description |
| dataset | Dataset | A dataset where this annotation is defined. |
| codeValue | Text | The code to use for this annotation. |
Examples
{
"@type": "StatisticalAnnotation",
"@id": "#annotation=p",
"dataset": "#europe_unemployment",
"description": "This value is a projection.",
"codeValue": "p"
}
For examples of defining annotations, see section, “Annotations - Examples - Defining Annotations”
DimensionValue
Type: Thing > Intangible > StructuredValue > DimensionValue
A dimension’s permitted or observed value.
Values in a codeList must provide a code using the codeValue property, which is used to identify it elsewhere in the dataset (e.g., in observations). These can have additional properties:
- If the dimension has an
equivalentType, it should be added to the @type list and its properties can be used directly. - Standard schema.org properties from super types can be used as well (e.g., name)
- Properties not covered by schema.org can be added, through the PropertyValue mechanism.
In an observation, the values for dimensions without codes, such as the timestamp in time series data, should be set using the value property.
| Property | Expected type | Description |
| dimension | CategoricalDimension or TimeDimension | The dimension this value belongs to. |
| codeValue | Text | The code from the dimension’s code list. |
| value | Text or Number or DateTime | The non-code value for a time dimension. |
| parent | DimensionValue | If `parentDimension` is specified, the value in the `parentDimension` for this value. |
| additionalProperty | PropertyValue | A property/value pair associated with the dimension value. |
Examples
A DimensionValue with an inherited property (name):
{
"@type": "DimensionValue",
"@id": "#country_group=eu",
"dimension": "#country_group",
"codeValue": "eu",
"name": [
{"@language": "en", "@value": "European Union"},
{"@language": "fr", "@value": "Union européenne"},
{"@language": "de", "@value": "Europäische Union"}
]
}
A DimensionValue in #country’s codeList, with properties from an equivalentType and a parentProperty of country_group:
{
"@type": ["DimensionValue", "Country"],
"@id": "#country=at",
"dimension": "#country",
"codeValue": "at"
"alternateName": "AT",
"name": [
{"@language": "en", "@value": "Austria"},
{"@language": "fr", "@value": "Autriche"},
{"@language": "de", "@value": "Österreich"}
],
"geo": {
"@type": "GeoCoordinates",
"latitude": 47.6965545,
"longitude": 13.34598005
},
"country_group": "#country_group=eu"
}
Note: In the above example, parent is given by ID rather than as a DimensionValue object with codeValue of ‘eu’. Processing software should behave the same with either form.
Similarly, a DimensionValue in an Observation can refer to a DimensionValue defined in its CategoricalDimension’s codeList by code:
{
"@type": "DimensionValue",
"dimension": "#country",
"codeValue": "at"
}
Or by ID:
{
"@id": "#country=at"
}
Time dimensions need non-code values:
{
"@type": "DimensionValue",
"dimension": "#month",
"value": {
"@type": "xsd:gYearMonth",
"@value": "2010-10"
}
}
For an example of a dimension value references in an observation, see “Observation - examples”
DataSlice
Type: Thing > Intangible > DataSlice
A slice is a grouping of statistical observations that share the same measures and dimensions. For example, A slice may contain population and GDP (measures) by country and year (dimensions).
| Property | Expected type | Description |
| dataset | Dataset | The dataset this slice belongs to. |
| dimension | CategoricalDimension or TimeDimension | A dimension that is used in this slice. |
| measure | StatisticalMeasure | A measure that is used in this slice. |
| tableMapping | TableMapping | Column mappings for `measure`s or `dimension`s to `data` CSV header names. |
| data | URL or Observation | A CSV table containing the observations of the slice or a set of observations that belong to the slice. |
| footnote | PropertyValue | A footnote applying to this slice. |
Slice data can be provided in two equivalent ways:
- As a CSV table
- As a set of inlined observations
When data for a DataSlice is provided as a CSV table, it must follow these conventions:
- The first row of the table is a header that contains the names the columns.
- A column corresponding to a slice
dimensionhas a header name of the correspondingTableMapping’scolumnIdentifier, if provided, or the fragment part of the correspondingCategoricalDimensionorTimeDimension’s@id. - A column corresponding to a slice
measurehas a header name of the correspondingTableMapping’scolumnIdentifier, if provided, or the fragment part of the correspondingStatisticalMeasure’s@id. - The columns for a measure’s
StatisticalAnnotations are named as the measure’s header name, followed by an asterisk (*). - The table contains one row per observation (i.e., combination of dimension values).
Examples
{
"@type": "DataSlice",
"dataset": "#europe_unemployment",
"dimension": [
"#country",
"#month",
"#age"
],
"measure": [
"#unemployment",
"#unemployment_rate"
],
"tableMapping": {
"@type": "tableMapping",
"sourceEntity": "#age",
"columnIdentifier": "ages_code"
},
"data": "country_total_byage.csv"
}
Observation
Type: Thing > Intangible > Observation
A statistical observation holds the individual measurements for a slice, for a given set of dimension values.
| Property | Expected type | Description |
| slice | DataSlice | The slice the observation belongs to. |
| dimensionValue | DimensionValue | One or more dimension values for dimensions specified in the containing slice. |
| measureValue | MeasureValue | One or more measure values for measures specified in the containing slice. |
Examples
{
"@id": "#country=uk/month=2010-10/sex=m",
"@type": "Observation",
"dimensionValue": [
{
"@type": "DimensionValue",
"dimension": "#country",
"codeValue": "uk"
},
{
"@type": "DimensionValue",
"dimension": "#month",
"value": {
"@type": "xsd:gYearMonth",
"@value": "2010-10"
}
},
{
"@type": "DimensionValue",
"dimension": "#gender",
"codeValue": "m"
}
],
"measureValue": …
}
MeasureValue
Type: Thing > Intangible > StructuredValue > QuantitativeValue > MeasureValue
A MeasureValue is a quantitative value that indicates the measure to which it corresponds. It may optionally be annotated with one or more of the annotations defined in the StatisticalDataset. For example, values for a population measure might use annotations to distinguish intercensal estimates from counts.
| Property | Expected type | Description |
| measure | StatisticalMeasure | The measure for which this value is observed. |
| annotation | StatisticalAnnotation | an annotation defined in this statistical dataset. |
| value | Boolean or Number or StructuredValue or Text |
The value property inherited from QuantitativeValue. |
Examples
{
"@type": "MeasureValue",
"measure": #unemployment,
"value": 1448000
}
{
"@type": "MeasureValue",
"measure": "#unemployment_rate",
"unitCode": "P1",
"value": 8.5
}
For examples with annotations, see section, “Annotations - Examples - Using Annotations”.
Annotations
Many statistical datasets use annotations on values in observations to provide contextual explanations or methodological details. The annotations appearing in a dataset can be defined using the StatisticalDataset’s annotation property, either as a URL to a CSV table or inline as JSON-LD objects. When annotations are provided as a table, the data in the CSV table must follow these conventions:
- The first row of the table is a header that contains the names of the columns
- Each annotation corresponds to one row in the table. All possible values of the annotation list must appear in the table.
- The first column is called “codeValue”, and contains the code value by which to refer to each annotation
- Each subsequent column has the name of the property it represents, e.g., “name”, “description”
- If the values are in a specific language, the code of the language should be used as a suffix, e.g., “name@en”, “description@en”
References to annotations appear as annotation values on MeasureValue instances. If these were provided in a CSV table for a slice,
- The name of a column corresponding to an annotation for a measure starts with that measure’s column name, followed by the asterisk character ‘*’. Cells should have a value of the annotation’s code. Multiple annotation codes can be separated by semicolon characters ‘;’. If there are no annotations for a measure, the annotation column may be omitted.
Examples
Defining Annotations
an annotations CSV table might look like the one from the prior example:
codeValue,description@en
p,This value is a projection.
r,This value has been revised.
If the annotations are given as JSON, they might look like this:
{
"@type": "StatisticalDataset",
…
"annotation": [
{
"@type": "StatisticalAnnotation",
"@id": "#annotation=p",
"description": {
"@language": "en",
"@value": "This value is a projection."
},
"codeValue": "p"
},
{
"@type": "StatisticalAnnotation",
"@id": "#annotation=r",
"description": {
"@language": "en",
"@value": "This value has been revised."
},
"codeValue": "r"
},
]
…
}
Using Annotations
When setting annotations (possibly more than one, as in the example) on a MeasureValue can be referred to by code:
{
"@type": "MeasureValue",
"measure": "#unemployment",
"value": 1448000,
"annotation": [
{
"@type": "StatisticalAnnotation",
"codeValue": "p",
},
{
"@type": "StatisticalAnnotation",
"codeValue": "r",
}
]
}
When using a CSV table of observations for a slice, an annotation column looks like this:
country,month,sex,unemployment,unemployment_rate,unemployment*
uk,2010-11,m,1465035,8.6,
Uk,2010-10,m,1448000,8.5,p;r
Full Examples
JSON-LD Files
An example with dimension and slice data in CSV files is at eurostat-unemployment-dspl-v1.json
The analogous dataset with all data expressed in JSON-LD is at eurostat-unemployment-dspl-v1-inline-big.json (172 MB)
A trimmed version with a single observation per slice is at eurostat-unemployment-dspl-v1-inline-small.json
With CSV Data
Below, all the dimensions, measures, annotations and slices are defined in CSV files:
{
"@context": "http://schema.org",
"@id": "#europe_unemployment",
"@type": "StatisticalDataset",
"name": "Unemployment in Europe (monthly)",
"description": "Harmonized unemployment data for European countries.",
"url": "http://epp.eurostat.ec.europa.eu/portal/page/portal/lang-en/employment_unemployment_lfs/introduction",
"license": "https://ec.europa.eu/eurostat/about/policies/copyright",
"creator":{
"@type":"Organization",
"url": "https://ec.europa.eu/eurostat",
"name":"Eurostat",
},
"temporalCoverage":"1993-01/2010-12",
"spatialCoverage":{
"@type":"Place",
"geo":{
"@type":"GeoShape",
"name": "European Union",
"box":"34.633285 -10.468556 70.096054 34.597916"
}
},
"measure": [
{
"@type": "StatisticalMeasure",
"@id": "#unemployment",
"dataset": "#europe_unemployment",
"name": "Unemployment (monthly)",
"description": "The total number of people unemployed",
"url": "http://ec.europa.eu/eurostat/product?code=une_nb_m&language=en",
"unitCode": "IE"
},
"dimension": [
{
"@type": "CategoricalDimension",
"@id": "#country",
"dataset": "#europe_unemployment",
"codeList": "countries.csv",
"equivalentType": "Country"
},
{
"@type": "TimeDimension",
"@id": "#month",
"dataset": "#europe_unemployment",
"equivalentType": "xsd:gYearMonth"
}
],
"annotation": "annotations.csv",
"slice": {
"@type": "DataSlice",
"dimension": ["#country", "#month"],
"measure": ["#unemployment", "#unemployment_rate"],
"data": "country_total.csv"
}
}
The country dimension’s code list countries.csv might begin like this:
"codeValue","alternateName","country_group","name@en","name@fr","name@de","latitude","longitude"
"at","AT","eu","Austria","Autriche","Österreich","47.6965545","13.34598005"
"be","BE","eu","Belgium","Belgique","Belgien","50.501045","4.47667405"
"bg","BG","eu","Bulgaria","Bulgarie","Bulgarien","42.72567375","25.4823218"
The annotation definitions table annotations.csv might begin like this
codeValue,description
p,This value is a projection
r,This value has been revised
The slice observations table country_total.csv might begin like this:
country,seasonality,month,unemployment,unemployment_rate
at,nsa,1993-01,171000,4.5
uk,trend,2010-10,2455000,7.8
With JSON Data
Below, data for all properties is provided inline as JSON:
{
"@context": "http://schema.org",
"@id": "#europe_unemployment",
"@type": "StatisticalDataset",
"name": "Le Ch\u00f4mage en Europe (mensuel)",
"description": "Harmonized unemployment data for European countries. This dataset was prepared by Google based on data downloaded from Eurostat.",
"url": "http://epp.eurostat.ec.europa.eu/portal/page/portal/lang-en/employment_unemployment_lfs/introduction",
"license": "https://ec.europa.eu/eurostat/about/policies/copyright",
"creator":{
"@type":"Organization",
"url": "https://ec.europa.eu/eurostat",
"name":"Eurostat",
},
"temporalCoverage":"1993-01/2010-12",
"spatialCoverage":{
"@type":"Place",
"geo":{
"@type":"GeoShape",
"name": "European Union",
"box":"34.633285 -10.468556 70.096054 34.597916"
}
},
"dimension": [
{
"@id": "#country",
"@type": "CategoricalDimension",
"dataset": "#europe_unemployment",
"equivalentType": "Country",
"codeList": [
{
"@id": "#country=at",
"@type": [
"DimensionValue",
"Country"
],
"name": "Austria",
"codeValue": "at",
"dimension": "#country",
"alternateName": "AT",
"additionalProperty": [
{
"@type": "PropertyValue",
"propID": "latitude",
"value": 47.6965545
},
{
"@type": "PropertyValue",
"propID": "longitude",
"value": 13.34598005
}
]
}
]
},
{
"@id": "#month",
"@type": "TimeDimension",
"dataset": "#europe_unemployment",
"equivalentType": "xsd:gYearMonth"
}
],
"measure": [
{
"@id": "#unemployment",
"@type": "StatisticalMeasure",
"name": "Unemployment (monthly)",
"description": "The total number of people unemployed",
"url": "http://ec.europa.eu/eurostat/product?code=une_nb_m&language=en",
"dataset": "#europe_unemployment",
"sameAs": "https://www.wikidata.org/wiki/Q41171",
"unitCode": "IE"
},
{
"@id": "#unemployment_rate",
"@type": "StatisticalMeasure",
"name": "Unemployment rate (monthly)",
"description": "The unemployment rate represents unemployed persons as a percentage of the labour force. The labour force is the total number of people employed and unemployed.",
"url": "http://ec.europa.eu/eurostat/product?code=une_rt_m&language=en",
"dataset": "#europe_unemployment",
"sameAs": "https://www.wikidata.org/wiki/Q1787954",
"unitCode": "P1"
}
],
"annotation": [
{
"@id": "#annotation=p",
"@type": "StatisticalAnnotation",
"dataset": "#europe_unemployment",
"codeValue": "p",
"description": "This value is a projection"
},
{
"@id": "#annotation=r",
"@type": "StatisticalAnnotation",
"dataset": "#europe_unemployment",
"codeValue": "r",
"description": "This value has been revised"
}
],
"slice": [
{
"@type": "DataSlice",
"@id": "#country_total",
"dataset": "#europe_unemployment",
"dimension": ["#country", "#month"],
"measure": ["#unemployment", "#unemployment_rate"],
"data": [
{
"@id": "#country=at/month=1993-01",
"@type": "Observation",
"slice": "#country_total",
"dimensionValue": [
{
"@type": "DimensionValue",
"dimension": "#country",
"codeValue": "uk"
},
{
"@type": "DimensionValue",
"dimension": "#month",
"value": "1993-01"
}
],
"measureValue": [
{
"@type": "MeasureValue",
"measure": "#unemployment",
"value": 171000,
"unitCode": "IE",
"annotation": "#annotation=p"
},
{
"@type": "MeasureValue",
"measure": "#unemployment_rate",
"value": 4.5,
"unitCode": "P1"
}
]
}
]
}
]
}
JSON API considerations
Per the JSON-LD API best practices draft, a first consideration of JSON-LD APIs is to produce developer-friendly JSON.
The DSPL 2 JSON format described above has a number of inconvenient features for use as the output of a JSON API. These center around its use of arrays instead of objects for a number of properties, making lookups cumbersome. Several of these can be simplified by customizing value indexing in the JSON-LD context. Although the features are described separately, we anticipate they will be most useful when combined.
Language indexing
Fields like name and description support JSON-LD literal values for multilingual values:
"name": [
{"@value": "Germany", "@language": "en"},
{"@value": "Deutschland", "@language": "de"},
{"@value": "Allemania", "@language": "fr"}
]
we can make this friendlier for data consumers by writing it as a map using language indexing. With this context,
"@context": [
{
"description": {"@container": "@language"}
"name": {"@container": "@language"}
},
"http://schema.org"
]
we can write:
"name": {
"en": "Germany",
"de": "Deutschland",
"fr": "Allemange"
}
Data indexing
Dimension code lists and annotations have a codeValue field, and footnote
and additionalProperty a propertyID, which users will commonly want to look
up:
"annotation": [
{
"@id": "#annotation=p",
"@type": "StatisticalAnnotation",
"dataset": "#europe_unemployment",
"codeValue": "p",
"description": "This value is a projection"
},
{
"@id": "#annotation=r",
"@type": "StatisticalAnnotation",
"dataset": "#europe_unemployment",
"codeValue": "r",
"description": "This value has been revised"
}
]
We can use apply JSON-LD 1.1 property-based data indexing in this case. E.g.,
"@context": [
{
"@version": 1.1,
"codeList": {
"@container": "@index",
"@index": "schema:codeValue"
}
"annotation": {
"@container": "@index",
"@index": "schema:codeValue"
}
},
"http://schema.org"
]
lets us write
"annotation": {
"p": {
"@id": "#annotation=p",
"@type": "StatisticalAnnotation",
"dataset": "#europe_unemployment",
"description": "This value is a projection"
},
"r": {
"@id": "#annotation=r",
"@type": "StatisticalAnnotation",
"dataset": "#europe_unemployment",
"description": "This value has been revised"
}
}
}
Node identifier indexing
In other cases, such as dimensions and measures, a DSPL 2 dataset might have lists of these values which would need to be looked up by ID, e.g., to resolve the dimensions or measures in a slice:
"measure": [
{
"@id": "#unemployment",
"@type": "StatisticalMeasure",
"name": "Unemployment (monthly)",
"description": "The total number of people unemployed",
"url": "http://ec.europa.eu/eurostat/product?code=une_nb_m&language=en",
"dataset": "#europe_unemployment",
"sameAs": "https://www.wikidata.org/wiki/Q41171",
"unitCode": "IE"
},
{
"@id": "#unemployment_rate",
"@type": "StatisticalMeasure",
"name": "Unemployment rate (monthly)",
"description": "The unemployment rate represents unemployed persons as a percentage of the labour force. The labour force is the total number of people employed and unemployed.",
"url": "http://ec.europa.eu/eurostat/product?code=une_rt_m&language=en",
"dataset": "#europe_unemployment",
"sameAs": "https://www.wikidata.org/wiki/Q1787954",
"unitCode": "P1"
}
]
We can use (node identifier indexing)[https://w3c.github.io/json-ld-syntax/#node-identifier-indexing] to write these as ID-keyed objects instead of lists. E.g,
"@context": [
{
"dimension": {
"@container": "@id"
},
"measure": {
"@container": "@id"
},
"slice": {
"@container": "@id"
}
},
"http://schema.org"
]
lets us write:
"measure": {
"#unemployment": {
"@type": "StatisticalMeasure",
"name": "Unemployment (monthly)",
"description": "The total number of people unemployed",
"url": "http://ec.europa.eu/eurostat/product?code=une_nb_m&language=en",
"dataset": "#europe_unemployment",
"sameAs": "https://www.wikidata.org/wiki/Q41171",
"unitCode": "IE"
},
"#unemployment_rate": {
"@type": "StatisticalMeasure",
"name": "Unemployment rate (monthly)",
"description": "The unemployment rate represents unemployed persons as a percentage of the labour force. The labour force is the total number of people employed and unemployed.",
"url": "http://ec.europa.eu/eurostat/product?code=une_rt_m&language=en",
"dataset": "#europe_unemployment",
"sameAs": "https://www.wikidata.org/wiki/Q1787954",
"unitCode": "P1"
}
}