Abstract
Despite the longstanding adage "an image is worth a thousand words," creating accurate and hyper-detailed image descriptions for training Vision-Language models remains challenging. Current datasets typically have web-scraped descriptions that are short, low-granularity, and often contain details unrelated to the visual content. As a result, models trained on such data generate descriptions replete with missing information, visual inconsistencies, and hallucinations. To address these issues, we introduce ImageInWords (IIW), a carefully designed human-in-the-loop annotation framework for curating hyper-detailed image descriptions and a new dataset resulting from this process. We validate the framework through evaluations focused on the quality of the dataset and its utility for fine-tuning with considerations for readability, comprehensiveness, specificity, hallucinations, and human-likeness. Our dataset significantly improves across these dimensions compared to recently released datasets (+66%) and GPT-4V outputs (+48%). Furthermore, models fine-tuned with IIW data excel by +31% against prior work along the same human evaluation dimensions. Given our fine-tuned models, we also evaluate text-to-image generation and vision-language reasoning. Our model's descriptions can generate images closest to the original, as judged by both automated and human metrics. We also find our model produces more compositionally rich descriptions, outperforming the best baseline by up to 6% on ARO, SVO-Probes, and Winoground datasets.


Dataset
IIW hyper-detailed image description dataset is collected through a new Model Seeded, Sequential Human Augmentation paradigm. Our new annotation guidelines and framework result in descriptions with significantly longer length, containing a greater number of nouns, adjectives, adverbs, and verbs compared to those in prior work.

Human Authored Data Quality
The dataset achieves State-of-the-art (SoTA) results when evaluated on automated and Human Side-by-Side (SxS) metrics. The automatic readability metrics reflect a more verbose style requiring higher levels of education.
ImageInWords human SxS uses five metrics for evaluation: Comprehensiveness, Specificity, Hallucinations, TLDR quality, and Human-Likeness. Compared to prior work, IIW is rated as significantly better on all metrics with respect to DCI and DOCCI annotations from prior work. Below are the SxS results for human authored IIW data.
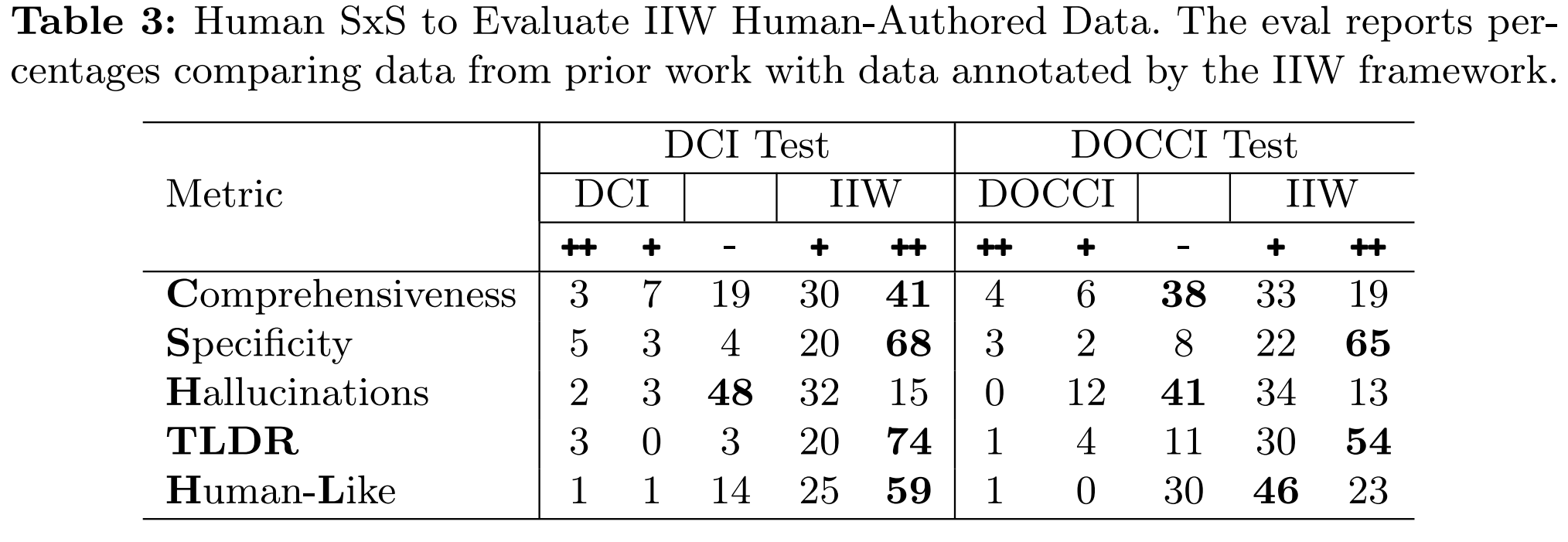
Fine-tuned Model Quality
Below we also report human SxS on descriptions generated by the IIW trained model. IIW descriptions are compared with models trained with DCI, DOCCI, or GPT-4V.

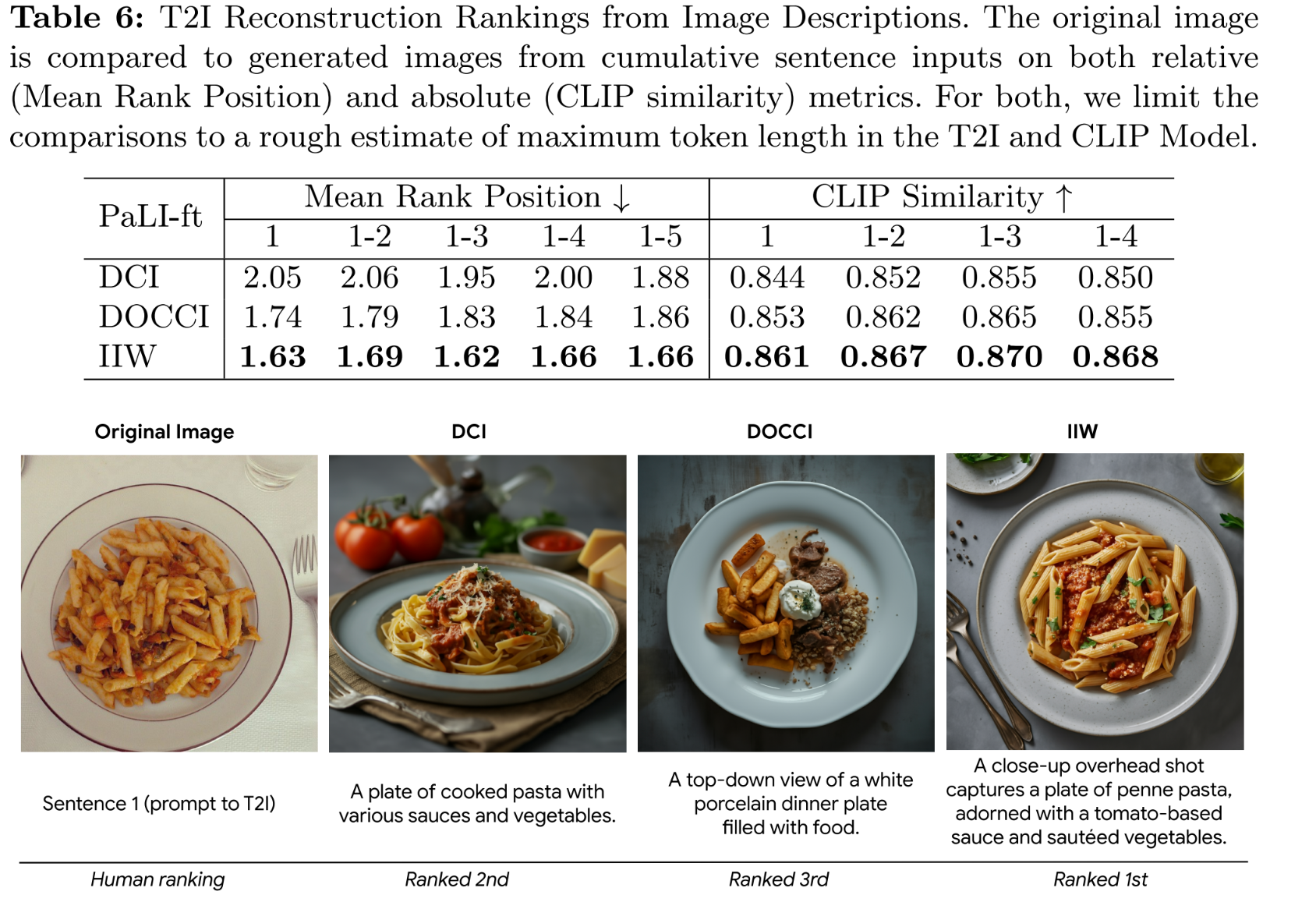
Reconstructing Images with Descriptions
ImageInWords models are also evaluated in terms of their utility to generate descriptions for downstream tasks such as text-to-image reconstruction. We find that IIW descriptions result in more accurate generated images, as shown by higher mean rank and clip similarity metrics.
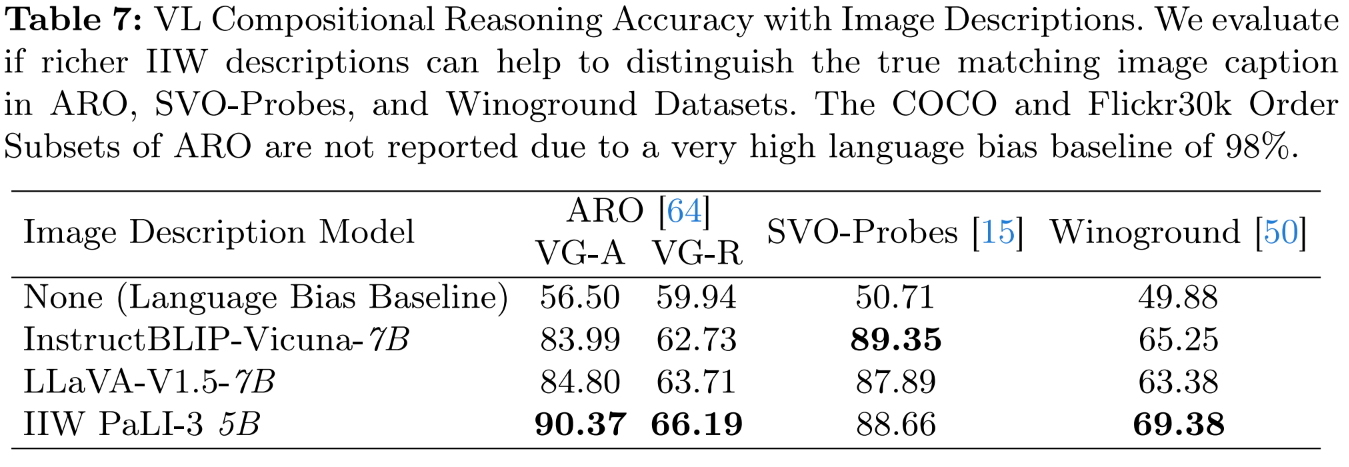
Compositional Reasoning with IIW Descriptions
Lastly, IIW finetuned model generated descriptions are evaluated for compositional reasoning tasks. IIW is able to improve accuracy on vision-language compositional reasoning benchmarks ARO and Winoground by several points compared to prior work by generating descriptions with finer grained content.
Dataset Viewer
Download
We release the IIW-Benchmark Eval Dataset, IIW human-authored descriptions (image and object level annotations) and comparison to prior work (DCI, DOCCI), machine generated enriched versions of the LocNar and XM3600 datasets are open sourced. The statistics below reflect the extent of the data enrichment (e.g., large increase in length and richness in each part of speech).
The datasets are released under a CC-BY-4.0 license and can be found at GitHub or be downloaded from Hugging Face in a `jsonl` format.

BibTeX
@misc{garg2024imageinwords,
title={ImageInWords: Unlocking Hyper-Detailed Image Descriptions},
author={Roopal Garg and Andrea Burns and Burcu Karagol Ayan and Yonatan Bitton and Ceslee Montgomery and Yasumasa Onoe and Andrew Bunner and Ranjay Krishna and Jason Baldridge and Radu Soricut},
year={2024},
eprint={2405.02793},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Dataset
IIW hyper-detailed image description dataset is collected through a new Model Seeded, Sequential Human Augmentation paradigm. Our new annotation guidelines and framework result in descriptions with significantly longer length, containing a greater number of nouns, adjectives, adverbs, and verbs compared to those in prior work.
Human Authored Data Quality
The dataset achieves State-of-the-art (SoTA) results when evaluated on automated and Human Side-by-Side (SxS) metrics. The automatic readability metrics reflect a more verbose style requiring higher levels of education. ImageInWords human SxS uses five metrics for evaluation: Comprehensiveness, Specificity, Hallucinations, TLDR quality, and Human-Likeness. Compared to prior work, IIW is rated as significantly better on all metrics with respect to DCI and DOCCI annotations from prior work. Below are the SxS results for human authored IIW data.
Fine-tuned Model Quality
Below we also report human SxS on descriptions generated by the IIW trained model. IIW descriptions are compared with models trained with DCI, DOCCI, or GPT-4V.
Reconstructing Images with Descriptions
ImageInWords models are also evaluated in terms of their utility to generate descriptions for downstream tasks such as text-to-image reconstruction. We find that IIW descriptions result in more accurate generated images, as shown by higher mean rank and clip similarity metrics.
Compositional Reasoning with IIW Descriptions
Lastly, IIW finetuned model generated descriptions are evaluated for compositional reasoning tasks. IIW is able to improve accuracy on vision-language compositional reasoning benchmarks ARO and Winoground by several points compared to prior work by generating descriptions with finer grained content.
Dataset Viewer
Download
We release the IIW-Benchmark Eval Dataset, IIW human-authored descriptions (image and object level annotations) and comparison to prior work (DCI, DOCCI), machine generated enriched versions of the LocNar and XM3600 datasets are open sourced. The statistics below reflect the extent of the data enrichment (e.g., large increase in length and richness in each part of speech).
The datasets are released under a CC-BY-4.0 license and can be found at GitHub or be downloaded from Hugging Face in a `jsonl` format.
BibTeX
@misc{garg2024imageinwords,
title={ImageInWords: Unlocking Hyper-Detailed Image Descriptions},
author={Roopal Garg and Andrea Burns and Burcu Karagol Ayan and Yonatan Bitton and Ceslee Montgomery and Yasumasa Onoe and Andrew Bunner and Ranjay Krishna and Jason Baldridge and Radu Soricut},
year={2024},
eprint={2405.02793},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
BibTeX
@misc{garg2024imageinwords,
title={ImageInWords: Unlocking Hyper-Detailed Image Descriptions},
author={Roopal Garg and Andrea Burns and Burcu Karagol Ayan and Yonatan Bitton and Ceslee Montgomery and Yasumasa Onoe and Andrew Bunner and Ranjay Krishna and Jason Baldridge and Radu Soricut},
year={2024},
eprint={2405.02793},
archivePrefix={arXiv},
primaryClass={cs.CV}
}