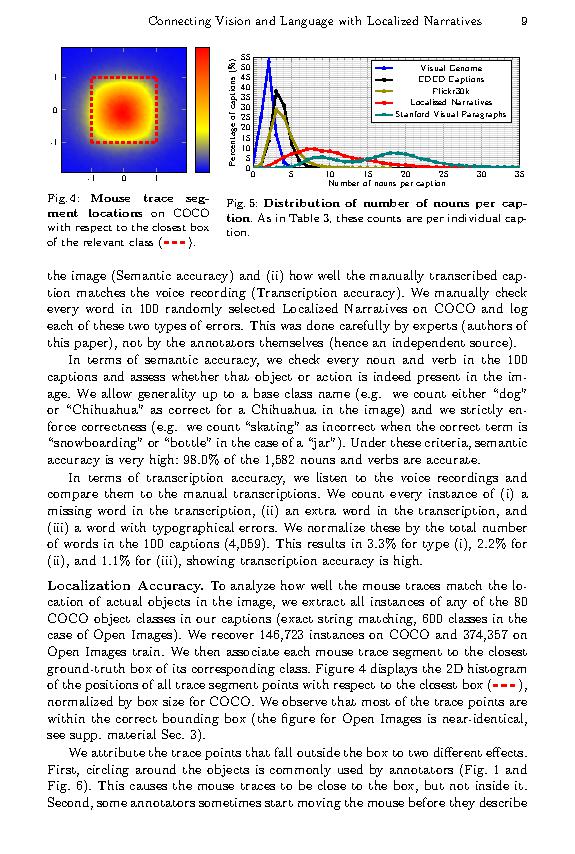
[[title]]
Client Coordinates: ([[clientPoint_.x]], [[clientPoint_.y]])
Canvas Coordinates: ([[canvasPoint_.x]], [[canvasPoint_.y]])
Image Coordinates: ([[imagePoint.x]], [[imagePoint.y]])
ViewBox Coordinates: ([[viewBoxPoint_.x]], [[viewBoxPoint_.y]])
imageTransform translation: ([[imageTransform_.x]],[[imageTransform_.y]])>
imageTransform scale: [[imageTransform_.scale]]
ScaleRatio_: [[scaleRatio]]
Canvas Coordinates: ([[canvasPoint_.x]], [[canvasPoint_.y]])
Image Coordinates: ([[imagePoint.x]], [[imagePoint.y]])
ViewBox Coordinates: ([[viewBoxPoint_.x]], [[viewBoxPoint_.y]])
imageTransform translation: ([[imageTransform_.x]],[[imageTransform_.y]])>
imageTransform scale: [[imageTransform_.scale]]
ScaleRatio_: [[scaleRatio]]