Look Before you Speak: Visually Contextualized Utterances
Google Research

Visually Contextualised Future Utterance Prediction. Given an instructional video with paired text and video data, we predict the next utterance in the video using a Co-attentional Multimodal Video Transformer. Our model trained on this task also achieves state-of-the-art performance on downstream VideoQA benchmarks.
Abstract
While most conversational AI systems focus on textual dialogue only, conditioning utterances on visual context (when it's available) can lead to more realistic conversations. Unfortunately, a major challenge for incorporating visual context into conversational dialogue is the lack of large-scale labeled datasets. We provide a solution in the form of a new visually conditioned Future Utterance Prediction task. Our task involves predicting the next utterance in a video, using both visual frames and transcribed speech as context. By exploiting the large number of instructional videos online, we train a model to solve this task at scale, without the need for manual annotations. Leveraging recent advances in multimodal learning, our model consists of a novel co-attentional multimodal video transformer, and when trained on both textual and visual context, outperforms baselines that use textual inputs alone. Further, we demonstrate that our model trained for this task on unlabelled videos achieves state-of-the-art performance on a number of downstream VideoQA benchmarks such as MSRVTT-QA, MSVD-QA, ActivityNet-QA and How2QA.
Model
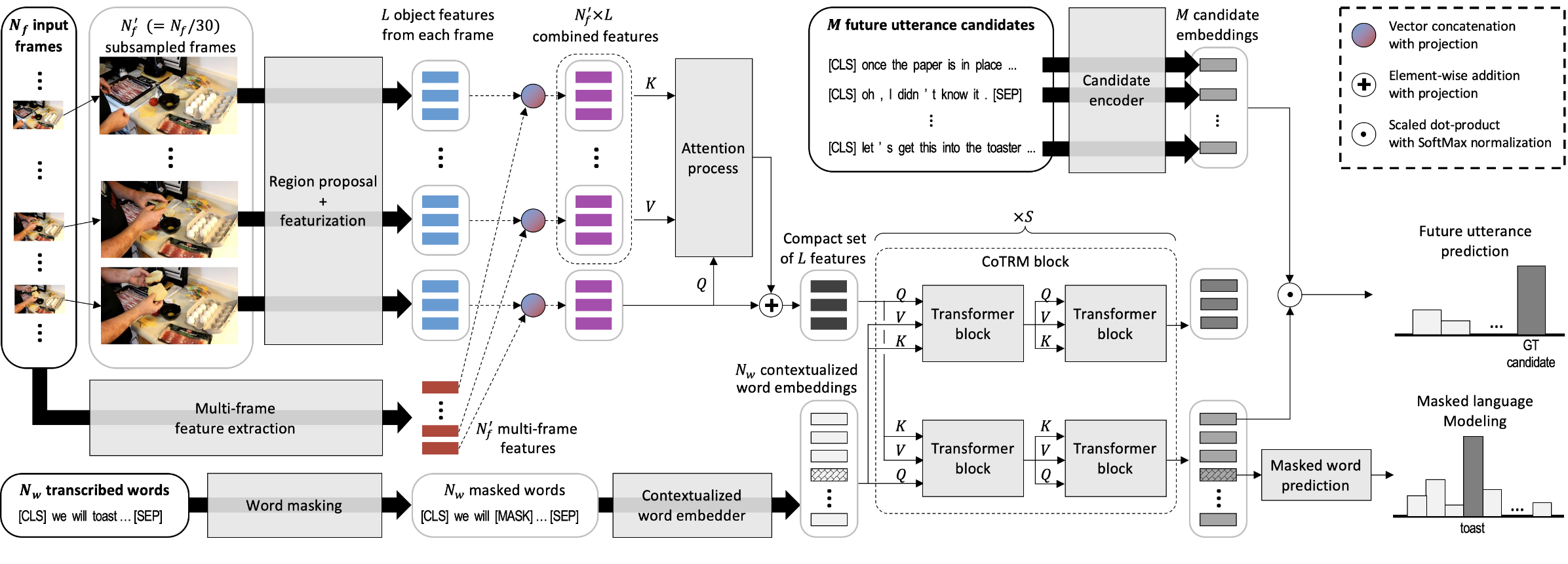
Our goal is to effectively learn from both vision and text in a video. We propose a Co-attentional Multimodal Video Transformer (CoMVT), which given a video clip, extracts contextualized word embeddings and visual features from transcribed words and video frames respectively, and fuses the extracted features to form a multimodal video feature using a co-attentional transformer. We train the network to predict the true next utterance from a set of candidate utterances by minimizing the negative log-likelihood of the true next utterance. Additionally, we also train with a BERT-style masked language modelling loss, which appears to have a regularisation effect.
Qualitative Results




Qualitative results on HowToFUP. On the right, we show the results of the baseline model that uses text inputs only (highlighted in red) and our multimodal model (highlighted in green). The GT utterance has a ✓ next to it. Note how the transcript often contains phrases with subtle indications to visual content, such as `here's another one' (second row) and `should come off right like that' (third row). In many of these cases, the correct future utterance refers to an object which can only be known from the visual context (highlighted in bold). The text only model often selects generics utterances, or those which are referred to specifically in previous dialogue (third row, selected candidate has the word `skin').
Bibtex
Contact phseo [AT] google [DOT] com for any queries.
Look Before you Speak assets are Copyright 2021 Google LLC, licensed under the CC-BY 4.0 license.