VoiceFilter: Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking
News:
- Please check out our latest work on VoiceFilter-Lite
- Our recent paper on using VoiceFilter-Lite for speaker recognition and personalized keyphrase detection
- Our recent paper and follow-up improvement on multi-user VoiceFilter-Lite
Paper: arXiv
Authors: Quan Wang *, Hannah Muckenhirn *, Kevin Wilson, Prashant Sridhar, Zelin Wu, John Hershey, Rif A. Saurous, Ron J. Weiss, Ye Jia, Ignacio Lopez Moreno. (*: Equal contribution.)
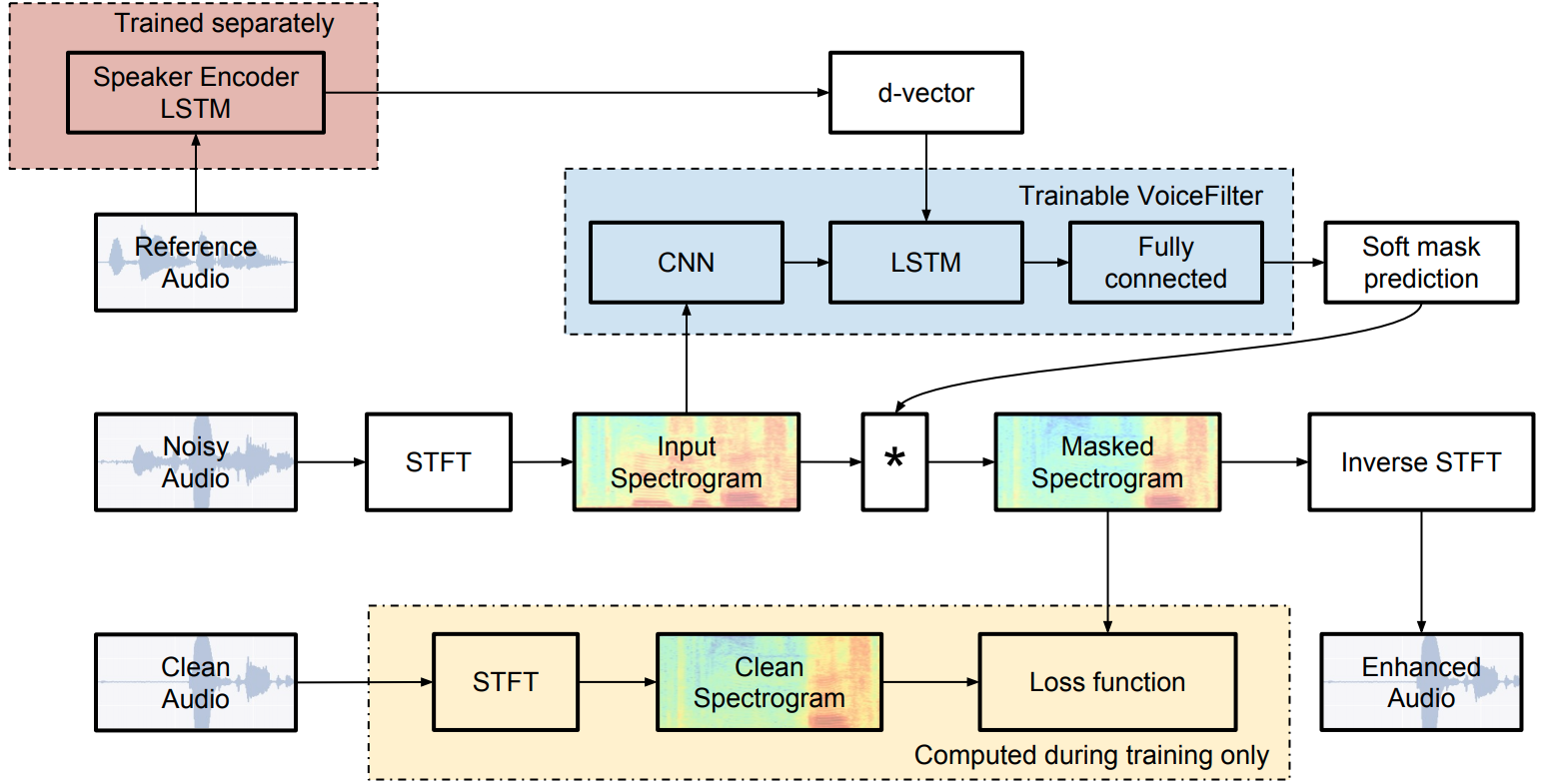
Abstract: In this paper, we present a novel system that separates the voice of a target speaker from multi-speaker signals, by making use of a reference signal from the target speaker. We achieve this by training two separate neural networks: (1) A speaker recognition network that produces speaker-discriminative embeddings; (2) A spectrogram masking network that takes both noisy spectrogram and speaker embedding as input, and produces a mask. Our system significantly reduces the speech recognition WER on multi-speaker signals, with minimal WER degradation on single-speaker signals.
System architecture:
Lectures:
Video demos:
Citation:
@inproceedings{Wang2019,
author={Quan Wang and Hannah Muckenhirn and Kevin Wilson and Prashant Sridhar and Zelin Wu and John R. Hershey and
Rif A. Saurous and Ron J. Weiss and Ye Jia and Ignacio Lopez Moreno},
title={{VoiceFilter: Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking}},
year=2019,
booktitle={Proc. Interspeech 2019},
pages={2728--2732},
doi={10.21437/Interspeech.2019-1101},
url={http://dx.doi.org/10.21437/Interspeech.2019-1101}
}
Random audio samples from LibriSpeech testing set
VoiceFilter model: CNN + bi-LSTM + fully connected
Apply VoiceFilter on noisy audio (2 speakers)
Meaning of the columns in the table below:
- The noisy audio input to the VoiceFilter. It's generated by summing the clean audio with an interference audio from another speaker.
- The output from the VoiceFilter.
- The reference audio from which we extract the d-vector. The d-vector is another input to the VoiceFilter. This audio comes from the same speaker as the clean audio.
- The clean audio, which is the ground truth.
| Noisy audio input | Enhanced audio output | Reference audio for d-vector | Clean audio (ground truth) |
|---|---|---|---|
Apply VoiceFilter on clean audio (single speaker)
Meaning of the columns in the table below:
- The clean audio, which we feed as the input to the VoiceFilter.
- The output from the VoiceFilter.
- The reference audio from which we extract the d-vector. The d-vector is another input to the VoiceFilter. This audio comes from the same speaker as the clean audio.
| Clean audio input | Enhanced audio output | Reference audio for d-vector |
|---|---|---|
FAQ
Can you share your code?
Unfortunately, the original VoiceFilter system heavily depends on Google's internal infrastructure and data, thus cannot be open sourced.
However, thanks for the efforts by Seungwon Park, a third-party unofficial implementation using PyTorch is available on GitHub:
https://github.com/mindslab-ai/voicefilter
Please note that we are not responsible for the correctness or quality of third-party implementations. Please use your own judgement to decide whether you want to use these implementations.
In Table 4 of your paper, why SDR of "No VoiceFilter" is so high? Does it mean your problem is very easy?
No. The high SDR is because of the way we prepare our training data - we trim the noisy audio to be the same length as the clean audio for training.
For example, if the clean audio is 5 seconds, the interference audio is 1 second, then the resulting noisy audio will consist of 1 second of really noisy audio, and 4 seconds of actually clean audio. Thus a big part of our "noisy" audios are actually clean, and when we compute the SDR statistically, we get very large numbers (especially the mean).
However, since we use the same volume for clean and interference audios, if we only look at the really noisy parts of the noisy audio, the theoretical SDR should be 0.
So the conclusion: We are NOT solving a problem which is easier than others.
Dataset information
For training and evaluating our VoiceFilter models, we had been using the VCTK and LibriSpeech datasets.
Here we provide the division of training-vs-testing as CSV files. Each line of the CSV files is a tuple of three utterance IDs:
(clean utterance, utterance for computing d-vector, interference utterance)