Paper: arXiv
Authors: Ye Jia *, Yu Zhang *, Ron J. Weiss *, Quan Wang, Jonathan Shen, Fei Ren, Zhifeng Chen, Patrick Nguyen, Ruoming Pang, Ignacio Lopez Moreno, Yonghui Wu. (*: equal contribution.)
Abstract: We describe a neural network-based system for text-to-speech (TTS) synthesis that is able to generate speech audio in the voice of many different speakers, including those unseen during training. Our system consists of three independently trained components: (1) a speaker encoder network, trained on a speaker verification task using an independent dataset of noisy speech from thousands of speakers without transcripts, to generate a fixed-dimensional embedding vector from seconds of reference speech from a target speaker; (2) a sequence-to-sequence synthesis network based on Tacotron 2, which generates a mel spectrogram from text, conditioned on the speaker embedding; (3) an auto-regressive WaveNet-based vocoder that converts the mel spectrogram into a sequence of time domain waveform samples. We demonstrate that the proposed model is able to transfer the knowledge of speaker variability learned by the discriminatively-trained speaker encoder to the new task, and is able to synthesize natural speech from speakers that were not seen during training. We quantify the importance of training the speaker encoder on a large and diverse speaker set in order to obtain the best generalization performance. Finally, we show that randomly sampled speaker embeddings can be used to synthesize speech in the voice of novel speakers dissimilar from those used in training, indicating that the model has learned a high quality speaker representation.
Click here for more from the Tacotron team.
Speaker Adaptation for Unseen Speakers
Each column corresponds to a single speaker. The speaker name is in "Dataset SpeakerID" format. All speakers are unseen during training. The first row is the reference audio used to compute the speaker embedding. The rows below that are synthesized by our model using that speaker embedding.
These examples are sampled from the evaluation set for Table 1 and Table 2 in the paper.
| VCTK p240 | VCTK p260 | LibriSpeech 1320 | LibriSpeech 3575 | LibriSpeech 6829 | LibriSpeech 8230 |
|---|---|---|---|---|---|
| Reference: | |||||
| Synthesized: | |||||
| 0: Take a look at these pages for crooked creek drive. | |||||
| 1: There are several listings for gas station. | |||||
| 2: Here's the forecast for the next four days. | |||||
| 3: Here is some information about the Gospel of John. | |||||
| 4: His motives were more pragmatic and political. | |||||
| 5: She had three brothers and two sisters. | |||||
| 6: This work reflects a quest for lost identity, a recuperation of an unknown past. | |||||
| 7: There were many editions of these works still being used in the nineteenth century. | |||||
| 8: Modern birds are classified as coelurosaurs by nearly all palaeontologists. | |||||
| 9: He was being fitted for ruling the state, in the words of his biographer. | |||||
Example Synthesis of a Sentence in Different Voices
We compare the same sentence synthesized using different speaker embeddings.
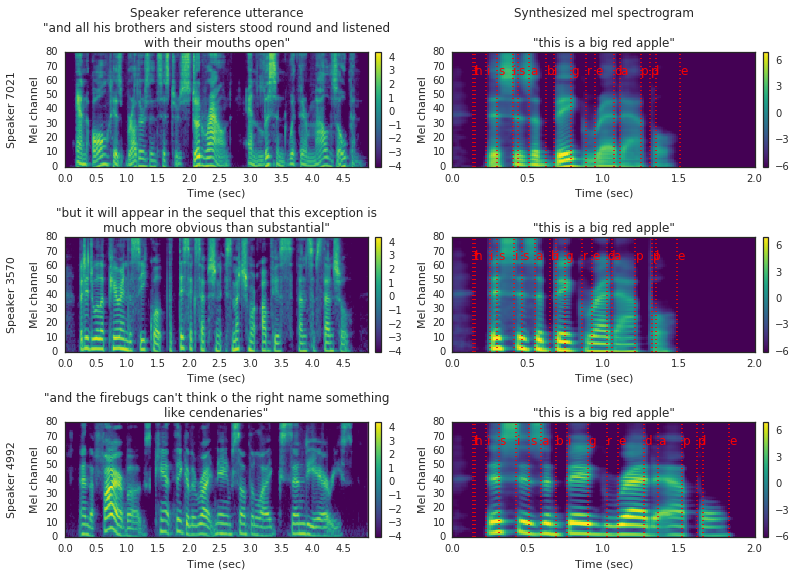
These examples correspond to Figure 2 in the paper. The mel spectrograms are visualized for reference utterances used to generate speaker embeddings (left), and the corresponding synthesizer outputs (right). The text-to-spectrogram alignment is shown in red. Three speakers held out of the train sets are used: one male (top) and two female (center and bottom).
| Reference | Synthesized |
|---|---|
Fictitious Speakers
Brand new voices created by randomly sampling from the embedding space. The synthesizer is trained on the LibriSpeech dataset. These examples correspond to Figure 5 in the paper.
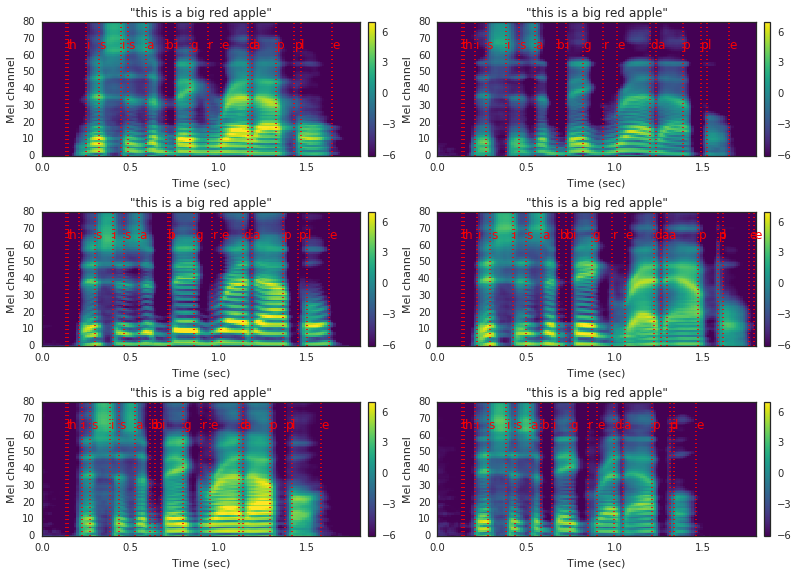
| Synthesized | |
|---|---|
Transferring Across Language
Reference audios are recorded by paper authors. The synthesizer is trained on the LibriSpeech dataset. The speaker encoder is only trained on US English dataset.
| Reference | Synthesized | Text |
|---|---|---|
| a long time ago, the second December, a cup of water. | ||
| a long time ago, the second December, a cup of water. | ||
| a long time ago, the second December, a cup of water. | ||
| a long time ago, the second December, a cup of water. |