Design for Recovery
Modern distributed systems are subject to many types of failures—failures that result from both unintentional errors and deliberately malicious actions. When exposed to accumulating errors, rare failure modes, or malicious actions by attackers, humans must intervene to recover even the most secure and resilient systems.
The act of recovering a failed or compromised system into a stable and secure state can be complex in unanticipated ways. For example, rolling back an unstable release may reintroduce security vulnerabilities. Rolling out a new release to patch a security vulnerability may introduce reliability issues. Risky mitigations like these are full of more subtle tradeoffs. For example, when deciding how quickly to deploy changes, a quick rollout is more likely to win the race against attackers, but also limits the amount of testing you’re able to do on it. You might end up widely deploying new code with critical stability bugs.
It’s far from ideal to begin considering these subtleties—and your system’s lack of preparedness to handle them—during a stressful security or reliability incident. Only conscious design decisions can prepare your system to have the reliability and the flexibility it needs to natively support varying recovery needs. This chapter covers some design principles that we’ve found effective in preparing our systems to facilitate recovery efforts. Many of these principles apply across a range of scales, from planet-scale systems to firmware environments within individual machines.
What Are We Recovering From?
Before we dive into design strategies to facilitate recovery, we’ll cover some scenarios that lead a system to require recovery. These scenarios fall into several basic categories: random errors, accidental errors, malicious actions, and software errors.
Random Errors
All distributed systems are built from physical hardware, and all physical hardware fails. The unreliable nature of physical devices and the unpredictable physical environment in which they operate lead to random errors. As the amount of physical hardware supporting the system grows, the likelihood that a distributed system will experience random errors increases. Aging hardware also leads to more errors.
Some random errors are easier to recover from than others. Total failure or isolation of some part of the system, such as a power supply or a critical network router, is one of the simplest failures to handle.1 It’s more complicated to address short-lived corruption caused by unexpected bit flips,2 or long-lived corruption caused by a failing instruction on one core in a multicore CPU. These errors are especially insidious when they occur silently.
Fundamentally unpredictable events outside a system can also introduce random errors into modern digital systems. A tornado or earthquake may cause you to suddenly and permanently lose a particular part of the system. A power station or substation failure or an anomaly in a UPS or battery may compromise the delivery of electrical power to one or many machines. This can introduce a voltage sag or swell that can lead to memory corruption or other transient errors.
Accidental Errors
All distributed systems are operated by humans, either directly or indirectly, and all humans make mistakes. We define accidental errors as errors caused by humans with good intent. The human error rate varies according to the type of task. Roughly speaking, as the complexity of a task increases, the error rate increases.3 An internal analysis of Google outages from 2015 through 2018 indicated that a meaningful fraction of outages (though not most outages) were caused by a unilateral human action that wasn’t subject to an engineering or procedural safety check.
Humans can make errors in relation to any portion of your system, so you need to consider how human error can occur throughout the entire stack of tools, systems, and job processes in the system lifecycle. Accidental errors may also impact your system in a random way that’s external to the system—for example, if a backhoe used for unrelated construction cuts through a fiber-optic cable.
Software Errors
You can address the error types we’ve discussed so far with design changes and/or software. To paraphrase a classic quote4 and its corollary,5 all errors can be solved with software…except bugs in software. Software errors are really just a special, delayed case of accidental errors: errors made during software development. Your code will have bugs, and you’ll need to fix these bugs. Some basic and well-discussed design principles—for example, modular software design, testing, code review, and validating the inputs and outputs of dependent APIs—help you address bugs. Chapters Chapter 6 and Chapter 12 cover these topics in more depth.
In some cases, software bugs mimic other types of errors. For example, automation lacking a safety check may make sudden and dramatic changes to production, mimicking a malicious actor. Software errors also magnify other types of errors—for example, sensor errors that return unexpected values that the software can’t handle properly, or unexpected behavior that looks like a malicious attack when users circumvent a faulty mechanism during the normal course of their work.
Malicious Actions
Humans can also work against your systems deliberately. These people may be privileged and highly knowledgeable insiders with the intent to do harm. Malicious actors refer to an entire category of humans actively working to subvert the security controls and reliability of your system(s), or possibly working to imitate random, accidental, or other kinds of errors. Automation can reduce, but not eliminate, the need for human involvement. As the size and complexity of your distributed system scales, the size of the organization maintaining it has to scale alongside the system (ideally, in a sublinear way). At the same time, the likelihood of one of the humans in that organization violating the trust you place in them also grows.
These violations of trust may come from an insider who abuses their legitimate authority over the system by reading user data not pertinent to their job, leaking or exposing company secrets, or even actively working to cause a prolonged outage. The person may have a brief lapse of good decision making, have a genuine desire to cause harm, fall victim to a social engineering attack, or even be coerced by an external actor.
A third-party compromise of a system can also introduce malicious errors. Chapter 2 covers the range of malicious actors in depth. When it comes to system design, mitigation strategies are the same regardless of whether the malicious actor is an insider or a third-party attacker who compromises system credentials.
Design Principles for Recovery
The following sections provide some design principles for recovery based upon our years of experience with distributed systems. This list isn’t meant to be exhaustive—we’ll provide recommendations for further reading. These principles also apply across a range of organizations, not just to Google-scale organizations. Overall, when designing for recovery, it’s important to be open-minded about the breadth and variety of problems that might arise. In other words, don’t spend time worrying about how to classify nuanced edge cases of errors; focus on being ready to recover from them.
Design to Go as Quickly as Possible (Guarded by Policy)
During a compromise or a system outage, there’s a lot of pressure to recover your system to its intended working state as soon as possible. However, the mechanisms you use to make rapid changes to systems can themselves risk making the wrong changes too quickly, exacerbating the issue. Likewise, if your systems are maliciously compromised, premature recovery or cleanup actions can cause other problems—for example, your actions might tip off an adversary that they’ve been discovered.6 We’ve found a few approaches effective in balancing the tradeoffs involved in designing systems to support variable rates of recovery.
To recover your system from any of our four classes of errors—or better yet, to avoid the need for recovery—you must be able to change the state of the system. When building an update mechanism (for example, a software/firmware rollout process, configuration change management procedure, or batch scheduling service), we recommend designing the update system to operate as fast as you can imagine it might ever need to operate (or faster, to the limits of practicality). Then, add controls to constrain the rate of change to match your current policy for risk and disruption. There are several advantages to decoupling your ability to perform rollouts from your rate and frequency policies for rollouts.
The rollout needs and policies of any organization change over time. For example, in its early days, a company might perform rollouts monthly, and never on nights or weekends. If the rollout system is designed around policy changes, a change in policy might entail difficult refactoring and intrusive code changes. If the design of a rollout system instead clearly separates the timing and rate of change from the action and content of that change, it’s much easier to adjust to inevitable policy changes that govern timing and rates of change.
Sometimes, new information you receive halfway through a rollout affects how you respond. Imagine that in response to an internally discovered security vulnerability, you’re deploying an internally developed patch. Typically, you wouldn’t need to deploy this change rapidly enough to risk destabilizing your service. However, your risk calculation may change in response to a landscape change (see Chapter 7): if you discover halfway through the rollout that the vulnerability is now public knowledge and being actively exploited in the wild, you may want to accelerate the procedure.
Inevitably, there will come a time when a sudden or unexpected event changes the risk you’re willing to accept. As a result, you want to push out a change very, very quickly. Examples can range from security bugs (ShellShock,7 Heartbleed,8 etc.) to discovering an active compromise. We recommend designing your emergency push system to simply be your regular push system turned up to maximum. This also means that your normal rollout system and emergency rollback system are one and the same. We often say that untested emergency practices won’t work when you need them. Enabling your regular system to handle emergencies means that you don’t have to maintain two separate push systems, and that you exercise your emergency release system often.9
If responding to a stressful situation only requires you to modify rate limits in order to quickly push a change, you’ll have much more confidence that your rollout tooling works as expected. You can then focus your energy on other unavoidable risks, such as potential bugs in quickly deployed changes, or making sure you close the vulnerabilities attackers may have used to access your systems.
We learned these lessons as the rollout of our internal Linux distribution evolved. Until recently, Google installed all the machines in our datacenters with a “base” or “golden” image, which contained a known set of static files. There were a few specific customizations, such as hostname, network configuration, and credentials, per machine. Our policy was to roll out a new “base” image across the fleet every month. Over several years, we built a set of tools and a software update system around that policy and workflow: bundle all of the files into a compressed archive, have the set of changes reviewed by a senior SRE, and then gradually update the fleet of machines to the new image.
We built our rollout tooling around this policy, and designed the tooling to map a particular base image to a collection of machines. We designed the configuration language to express how to change that mapping over the course of several weeks, and then used a few mechanisms to layer exceptions on top of the base image. One exception included security patches for a growing number of individual software packages: as the list of exceptions grew more complicated, it made less sense for our tooling to follow a monthly pattern.
In response, we decided to abandon the assumption of a monthly update to the base image. We designed more granular release units that corresponded to each software package. We also built a clean new API that specified the exact set of packages to install, one machine at a time, on top of the existing rollout mechanism. As shown in Figure 9-1, this API decoupled the software that defined a few different aspects:
-
The rollout and the rate at which each package was supposed to change
-
The configuration store that defined the current config of all machines
-
The rollout actuator that manages applying updates to each machine
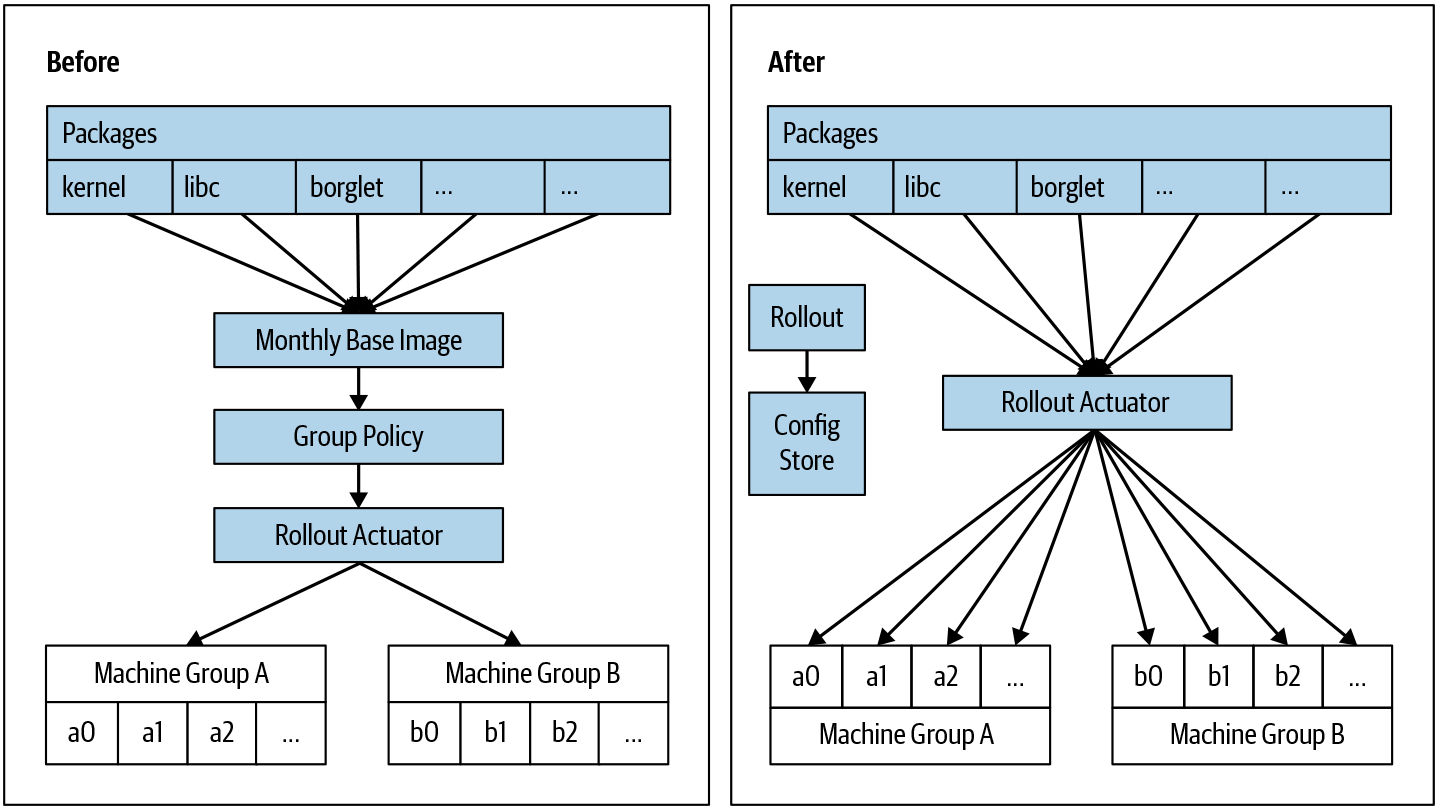
As a result, we could develop each aspect independently. We then repurposed an existing config store to specify the configuration of all the packages applied to each machine, and built a rollout system to track and update the independent rollouts of each package.
By decoupling the image build from the monthly rollout policy, we could enable a much wider range of release velocities for different packages. At the same time, while still preserving a stable and consistent rollout to most machines in the fleet, some test machines could follow the latest builds of all the software. Better still, decoupling the policy unlocked new uses of the whole system. We now use it to distribute a subset of carefully vetted files to the whole fleet regularly. We can also use our normal tooling for emergency releases simply by adjusting some rate limits and approving the release of one type of package to proceed faster than normal. The end result was simpler, more useful, and safer.
Limit Your Dependencies on External Notions of Time
Time—that is, ordinary time of day as reported by devices like wristwatches and wall clocks—is a form of state. Because you’re generally unable to alter how your system experiences the passage of time, any location where your system incorporates wall-clock time can potentially threaten your ability to complete a recovery. Mismatches between the time when you undertake your recovery effort and the time when the system was last operating normally can lead to unexpected system behaviors. For example, a recovery that involves replaying digitally signed transactions may fail if some transactions are signed by expired certificates, unless you design the recovery process to consider the original transaction date when validating certificates.
Your system’s time dependence may be even more likely to introduce security or reliability issues if it depends on an external notion of time that you don’t control. This pattern arises in the form of multiple types of errors—for example, software errors like Y2K, the Unix epoch rollover, or accidental errors where developers choose certificate expiration times so far in the future that it’s “not their problem anymore.” Clear-text or unauthenticated NTP connections also introduce risk if an attacker is able to control the network. A fixed date or time offset in code exhibits a code smell indicating that you may be creating a time bomb.
Tying events to wall-clock time is often an anti-pattern. Instead of wall-clock time, we recommend using one of the following:
-
Rates
-
Manually advanced notions of forward progress like epoch numbers or version numbers
-
Validity lists
As mentioned in Chapter 8, Google’s ALTS transport security system does not use expiration time in its digital certificates, and instead relies on a revocation system. The active revocation list is made up of vectors that define valid versus revoked ranges of certificate serial numbers, and works without depending on wall-clock time. You can achieve isolation goals through healthy, periodic pushes of updated revocation lists to create time compartments. You can perform an emergency push of a new revocation list to revoke certificates if you suspect an adversary may have gained access to underlying keys, and you can stop the periodic pushes during unusual circumstances to enable debugging or forensics. See Use an Explicit Revocation Mechanism for more discussion of that particular topic.
Design choices that depend on wall-clock time may also lead to security weaknesses. Because of reliability constraints, you may be tempted to disable certificate validity checking in order to perform a recovery. However, in this case, the cure is worse than the disease—it would be better to omit the certificate expiration (from the SSH key pair that allows login access to a cluster of servers) than to skip validity checking. To provide one notable exception, wall-clock time is useful for deliberately time-bounded access. For example, you might want to require that most employees reauthenticate daily. In cases like this, it’s important to have a path for repairing the system that doesn’t rely on wall-clock time.
Relying on absolute time can also lead to problems when you attempt to recover from crashes, or when databases that expect monotonically increasing time attempt to recover from corruption. Recovery may require an exhaustive transaction replay (which rapidly becomes infeasible as data sets grow) or an attempt to roll back time in a coordinated way across multiple systems. To provide a simpler example: correlating logs across systems that have inaccurate notions of time burdens your engineers with an unnecessary layer of indirection, which makes accidental errors more common.
You can also eliminate wall-clock time dependencies by using epoch or version advancement, which requires all parts of a system to coordinate around an integer value that represents a forward progression of “valid” versus “expired.” An epoch might be an integer stored in a distributed systems component like a lock service, or machine-local state that is ratcheted forward (allowed to move in only a forward direction) according to policy. To enable your systems to perform releases as quickly as possible, you might design them to allow rapid epoch advancement. A single service may be responsible for announcing the current epoch or initiating an epoch advancement. In the face of trouble, you can halt epoch advancement until you understand and remediate the issue. To return to our earlier public-key example: although certificates may age, you won’t be tempted to entirely disable certificate verification because you can stop epoch advancement. Epochs have some similarities with the MASVN scheme discussed in Minimum Acceptable Security Version Numbers.
Aggressively incremented epoch values could roll over or overflow. Be wary of how fast your system deploys changes, and how many intermediate epoch or version values you can tolerably skip.
An adversary with temporary control of your system might inflict lasting damage to the system by dramatically accelerating epoch advancement or causing an epoch rollover. A common solution to this problem is to choose an epoch value with a sufficiently large range and build in an underlying backstop rate limit—for example, a 64-bit integer rate limited to increment no more than once per second. Hardcoding a backstop rate limit is an exception to our earlier design recommendation to roll out changes as quickly as possible and to add policy to designate the rate of change. However, in this case, it’s difficult to imagine a reason to change the system state more than once per second, since you’re going to be dealing with billions of years. This strategy is also reasonable because a 64-bit integer is generally inexpensive on modern hardware.
Even in scenarios where waiting for elapsed wall-clock time is desirable, consider simply measuring elapsed time without requiring the actual time of day. A backstop rate limit will work even when the system isn’t aware of wall-clock time.
Rollbacks Represent a Tradeoff Between Security and Reliability
The first step to recovery during incident response is to mitigate the incident, typically by safely rolling back any suspect changes. A large fraction of production issues that require human attention are self-inflicted (see Accidental Errors and Software Errors), meaning that an intended change to the system contains a bug or other misconfiguration that causes an incident. When this happens, basic tenets of reliability call for a system rollback to the last known good state as quickly and safely as possible.
In other cases, you need to prevent rollbacks. When patching security vulnerabilities, you are often racing against attackers, trying to deploy a patch before an attacker exploits the vulnerability. Once the patch is successfully deployed and shown to be stable, you need to prevent attackers from applying a rollback that reintroduces the vulnerability, while still leaving yourself the option to voluntarily roll back—because security patches themselves are code changes, they may contain their own bugs or vulnerabilities.
In light of these considerations, determining the appropriate conditions for a rollback can be complicated. Application-layer software is a more straightforward case. System software, like an operating system or privileged package management daemon, can easily kill and restart tasks or processes. You can collect the names of undesirable versions (usually unique label strings, numbers, or hashes10) into a deny list, which you can then incorporate into your deployment system’s release policies. Alternatively, you can manage an allow list and build your automation to include deployed application software on that list.
Privileged or low-level system components that are responsible for processing their own updates are more challenging. We call these components self-updating. Examples include a package management daemon that updates itself by overwriting its own executable file and then reexecuting itself, or a firmware image such as a BIOS that reflashes a replacement image on top of itself and then forces a reboot. These components may actively prevent themselves from being updated if they are maliciously modified. Hardware-specific implementation requirements add to the challenge. You need rollback control mechanisms that work even for these components, but the intended behavior itself may be challenging to define. Let’s consider two example policies and their flaws to better appreciate the problem:
- Allow arbitrary rollbacks
- This solution is not secure, because any factor that prompts you to perform a rollback may reintroduce a known security vulnerability. The older or more visible the vulnerability, the more likely it is that stable, weaponized exploitations of that vulnerability are readily available.
- Never allow rollbacks
- This solution eliminates the path to return to a known stable state, and only allows you to move forward to newer states. It’s unreliable because if an update introduces a bug, you can no longer roll back to the last known good version. This approach implicitly requires the build system to generate new versions to which you can roll forward, adding time and avoidable dependencies to the build and release engineering infrastructure.
Many alternatives to these two extreme approaches offer practical tradeoffs. These include the following:
-
Using deny lists
-
Using Security Version Numbers (SVNs) and Minimum Acceptable Security Version Numbers (MASVNs)
-
Rotating signing keys
In the following discussion, we assume in all cases that updates are cryptographically signed and that the signature covers the component image and its version metadata.
A combination of all three techniques discussed here may best manage the security/reliability tradeoffs for self-updating components. However, the complexity of this combination, and its reliance on ComponentState, makes this approach a huge undertaking. We recommend introducing one functionality at a time, and allowing sufficient time to identify any bugs or corner cases for each component you introduce. Ultimately, all healthy organizations should use key rotation, but deny list and MASVN capabilities are useful for high-velocity responses.
Deny lists
As you discover bugs or vulnerabilities in release versions, you may want to build a deny list to prevent known bad versions from being (re)activated, perhaps by hardcoding the deny list in the component itself. In the following example, we write this as Release[DenyList]. After the component is updated to a newly released version, it refuses an update to a deny-listed version:
def IsUpdateAllowed(self, Release) -> bool: return Release[Version] not in self[DenyList]
Unfortunately, this solution addresses only accidental errors, because hardcoded deny lists present an unresolvable security/reliability tradeoff. If the deny list always leaves room for rollback to at least one older, known good image, the scheme is vulnerable to unzipping—an attacker can incrementally roll back versions until they arrive at an older version that contains a known vulnerability that they can exploit. This scenario essentially collapses to the “allow arbitrary rollbacks” extreme described earlier, with intermediate hops along the way. Alternatively, configuring the deny list to altogether prevent rollbacks for critical security updates leads to the “never allow rollbacks” extreme, with its accompanying reliability pitfalls.
If you’re recovering from a security or reliability incident when multiple updates may be in progress across your fleet, hardcoded deny lists are a good choice for setting up your system to avoid accidental errors. It’s quick and relatively easy to append a single version to a list, since doing so has little or no impact on the validity of any other versions. However, you need a more robust strategy to resist malicious attacks.
A better deny-listing solution encodes the deny list outside of the self-updating component itself. In the following example, we write this as ComponentState[DenyList]. This deny list survives across component upgrades and downgrades because it’s independent of any single release—but the component still needs logic in order to maintain the deny list. Each release may reasonably encode the most comprehensive deny list known at the time of its release: Release[DenyList]. The maintenance logic then unites these lists and stores them locally (note that we write self[DenyList] instead of Release[DenyList] to indicate that "self" is installed and actively running):
ComponentState[DenyList] = ComponentState[DenyList].union(self[DenyList))
Check tentative updates for validity against the list, and refuse deny-listed updates (don’t explicitly reference "self" because its contribution to the deny list is already reflected in ComponentState, where it remains even after future versions are installed):
def IsUpdateAllowed(self, Release, ComponentState) -> bool: return Release[Version] not in ComponentState[DenyList]
Now you can make the security/reliability tradeoff deliberately as a matter of policy. When you’re deciding what to include in Release[DenyList], you can weigh the risk of unzipping attacks against the risk of an unstable release.
This approach also has drawbacks, even when you encode deny lists in a ComponentState data structure that’s maintained outside of the self-updating component itself:
-
Even though the deny list exists outside the configured intent of your centralized deployment system, you still have to monitor and consider it.
-
If an entry is ever accidentally added to the deny list, you may want to remove that entry from the list. However, introducing a removal capability may open the door to unzipping attacks.
-
The deny list may grow without bound, eventually hitting the size limits of storage. How do you manage garbage collection of a deny list?
Minimum Acceptable Security Version Numbers
Over time, deny lists become large and unwieldy as entries are appended. You can use a separate Security Version Number, written as Release[SVN], to drop older entries from the deny list, while still preventing them from being installed. As a result, you reduce the cognitive load on the humans responsible for the system.
Keeping Release[SVN] independent of other version notions allows a compact and mathematically comparable way to logically follow large numbers of releases without requiring the overhead space a deny list needs. Whenever you apply a critical security fix and demonstrate its stability, you increment Release[SVN], marking a security milestone that you use to regulate rollback decisions. Because you have a straightforward indicator of each version’s security status, you have the flexibility to conduct ordinary release testing and qualification, and the confidence that you can quickly and safely make rollback decisions when you discover bugs or stability issues.
Remember that you also want to prevent malicious actors from somehow rolling your systems back to known bad or vulnerable versions.11 To prevent these actors from getting a foothold in your infrastructure and using that foothold to prevent recovery, you can use a MASVN to define a low-water mark below which your systems should never operate.12 This must be an ordered value (not a cryptographic hash), preferably a simple integer. You can manage the MASVN similarly to how you manage the deny list:
-
Each release version includes a MASVN value that reflects the acceptable versions at its time of release.
-
You maintain a global value outside of the deployment system, written as
ComponentState[MASVN].
As a precondition for applying the update, all releases include logic verifying that a tentative update’s Release[SVN] is at least as high as the ComponentState[MASVN]. It is expressed as pseudocode as follows:
def IsUpdateAllowed(self, Release, ComponentState) -> bool: return Release[SVN] >= ComponentState[MASVN]
The maintenance operation for the global ComponentState[MASVN] is not part of the deployment process. Instead, maintenance takes place as the new release initializes for the first time. You hardcode a target MASVN into each release—the MASVN that you want to enforce for that component at the time when that release is created, written as Release[MASVN].
When a new release is deployed and executed for the first time, it compares its Release[MASVN] (written as self[MASVN], to reference the release that is installed and running) with ComponentState[MASVN]. If Release[MASVN] is higher than the existing ComponentState[MASVN], then ComponentState[MASVN] updates to the new larger value. In fact, this logic runs every time the component initializes, but ComponentState[MASVN] only changes following a successful update with a higher Release[MASVN]. It is expressed as pseudocode as follows:
ComponentState[MASVN] = max(self[MASVN], ComponentState[MASVN])
This scheme can emulate either of the extreme policies mentioned earlier:
-
Allowing arbitrary rollback, by never modifying
Release[MASVN] -
Never allowing rollback, by modifying
Release[MASVN]in lockstep withRelease[SVN]
In practice, Release[MASVN] is often raised in release i+1, following a release that mitigates a security issue. This ensures that i–1 or older versions are never executed again. Since ComponentState[MASVN] is external to the release itself, version i no longer allows downgrade to i–1 after i+1 has been installed, even though it did allow such downgrades when it was initially deployed. Figure 9-2 illustrates sample values for a sequence of three releases and their impact on ComponentState[MASVN].
![Figure 9-2: A sequence of three releases and their impact on ComponentState[MASVN]](images/bsrs_0902.png)
To mitigate a security vulnerability in release i–1, release i includes the security patch and an incremented Release[SVN]. Release[MASVN] doesn’t change in release i, because even security patches can have bugs. Once release i is proven to be stable in production, the next release, i+1, increments the MASVN. This indicates that the security patch is now mandatory, and releases without it are disallowed.
In keeping with the “go as quickly as possible” design tenet, the MASVN scheme separates the policy for reasonable rollback targets from the infrastructure that performs the rollbacks. It’s technically feasible to introduce a specific API in the self-updating component and receive a command from the centralized deployment management system to increment ComponentState[MASVN]. With that command, you might raise ComponentState[MASVN] on components that receive an update late in the deployment pipeline, after qualifying the release on enough devices that you have high confidence that it will work as planned. An API like this may be useful when you’re responding to an active compromise or a particularly severe vulnerability, where velocity is critical and risk tolerance is higher than normal for availability issues.
So far, this example has avoided introducing a dedicated API to mutate ComponentState. ComponentState is a delicate collection of values that impacts your ability to recover systems through updates or rollbacks. It is component-local, and external to the configured intent that a centralized piece of automation directly controls. The actual sequence of software/firmware versions experienced by each individual component may vary across a fleet of similar or identical devices, in the face of concurrent development, testing, canary analysis, and rollout. Some components or devices may walk the full set of releases, while others may experience many rollbacks. Still others may experience minimal change, and hop directly from a buggy or vulnerable version to the next stable, qualified release.
Using MASVNs is therefore a useful technique to combine with deny listing for self-updating components. In this scenario, you may perform deny listing very rapidly—potentially under incident response conditions. You then perform MASVN maintenance under calmer circumstances, to garbage-collect the deny list and permanently exclude (on a per-component-instance basis) any releases that are vulnerable or sufficiently old, and are never intended to execute again on a given component instance.
Rotating signing keys
Many self-updating components include support to cryptographically authenticate tentative updates—in other words, part of the release cycle for a component includes cryptographically signing that release. These components often include a hardcoded list of known public keys, or support for an independent key database, as part of ComponentState. For example:
def IsUpdateAllowed(self, Release, KeyDatabase) -> bool: return VerifySignature(Release, KeyDatabase)
You can prevent rollback by modifying the set of public keys trusted by a component, typically to remove an old or compromised key or to introduce a new key for signing future releases. Older releases are invalidated because newer releases no longer trust the public signature verification key needed to verify the signatures on the older releases. You must manage key rotation carefully, however, because a sudden change from one signing key to another can leave systems perilously exposed to reliability issues.
Alternatively, you can rotate keys more gradually by introducing a new update signature verification key, k+1, alongside an older verification key, k, and allowing updates that authenticate with either key to proceed. Once stability is demonstrated, you drop trust in key k. This scheme requires support for multiple signatures over a release artifact, and for multiple verification keys when authenticating candidate updates. It also has the advantage that signing key rotation—a best practice for cryptographic key management—is exercised regularly and therefore likely to work when needed in the wake of an incident.
Key rotation can help you recover from a very serious compromise whereby an attacker manages to temporarily control release management and sign and deploy a release with Release[MASVN] set to the maximum value. In this type of attack, by setting ComponentState[MASVN] to its maximum value, the attacker forces you to set Release[SVN] to its maximum in order for future releases to be viable, thereby rendering the whole MASVN scheme useless. In response, you can revoke the compromised public key in new releases signed by a new key, and add dedicated logic to recognize the unusually high ComponentState[MASVN] and reset it. Since this logic is itself subtle and potentially dangerous, you should use it with care, and aggressively revoke any releases that include it as soon as they’ve served their purpose.
This chapter does not cover the full complexity of incident response for a serious and targeted compromise. See Chapter 18 for more information.
Rolling back firmware and other hardware-centric constraints
Hardware devices with their own corresponding firmware—such as a machine and its BIOS, or a network interface card (NIC) and its firmware—are common manifestations of self-updating components. These devices present additional challenges for robust MASVN or key rotation schemes, which we touch on briefly here. These details play an important role in recovery because they help to enable scalable or automated recovery from potentially malicious actions.
Sometimes, one-time-programmable (OTP) devices like fuses are used by ROM or firmware to implement a forward-only MASVN scheme by storing ComponentState[MASVN]. These schemes have significant reliability risks because rollback is infeasible. Additional software layers help address the constraints of physical hardware. For example, the OTP-backed ComponentState[MASVN] covers a small, single-purpose bootloader that contains its own MASVN logic and has exclusive access to a separate mutable MASVN storage region. This bootloader then exposes the more robust MASVN semantics to the higher-level software stack.
For authenticating signed updates, hardware devices sometimes use OTP memory to store public keys (or their hashes) and revocation information related to those keys. The number of key rotations or revocations supported is typically heavily limited. In these cases, a common pattern is again to use the OTP-encoded public key and revocation information to validate a small bootloader. This bootloader then contains its own layer of verification and key management logic, analogous to the MASVN example.
When dealing with a large fleet of hardware devices that actively leverage these mechanisms, managing spare parts can be a challenge. Spare parts that sit in inventory for years before they’re deployed will necessarily have very old firmware when they’re put to use. This old firmware must be updated. If older keys are completely disused, and newer releases are signed only by newer keys that didn’t exist when the spare part was originally manufactured, then the new update won’t verify.
One solution is to walk devices through a sequence of upgrades, making sure that they make a stop at all releases that trust both an old and a new key during a key rotation event. Another solution is to support multiple signatures per release. Even though newer images (and devices that have been updated to run these newer images) don’t trust an older verification key, these newer images can still carry a signature by that older key. Only older firmware versions can validate that signature—a desired action that allows them to recover after being starved of updates.
Consider how many keys are likely to be used across the lifetime of a device, and make sure that the device has sufficient space for keys and signatures. For example, some FPGA products support multiple keys for authenticating or encrypting their bitstreams.13
Use an Explicit Revocation Mechanism
A revocation system’s primary role is to stop some kind of access or function. In the face of an active compromise, a revocation system can be a lifesaver, allowing you to quickly revoke attacker-controlled credentials and recover control of your systems. However, once a revocation system is in place, accidental or malicious behavior may lead to reliability and security consequences. If possible, consider these issues during the design phase. Ideally, the revocation system should serve its purpose at all times without introducing too many security and reliability risks of its own.
To illustrate general concepts about revocation, we’ll consider the following unfortunate but common scenario: you discover that an attacker has somehow gained control of valid credentials (such as a client SSH key pair that allows login access to a cluster of servers), and you want to revoke these credentials.14
Revocation is a complex topic that touches on many aspects of resilience, security, and recovery. This section discusses only some aspects of revocation that are relevant for recovery. Additional topics to explore include when to use an allow list versus a deny list, how to hygienically rotate certificates in a crash-resilient manner, and how to safely canary new changes during rollout. Other chapters in this book offer guidance on many of these topics, but bear in mind that no single book is an adequate reference in and of itself.
A centralized service to revoke certificates
You might choose to use a centralized service to revoke certificates. This mechanism prioritizes security by requiring your systems to communicate with a centralized certificate validity database that stores certificate validity information. You must carefully monitor and maintain this database in the interest of keeping your systems secure, as it becomes the authoritative store of record for which certificates are valid. This approach is similar to building a separate rate-limiting service independent from the service designed to enact changes, as discussed earlier in the chapter. Requiring communication with a certificate validity database does have a shortcoming, however: if the database is ever down, all the other dependent systems also go down. There’s a strong temptation to fail open if the certificate validity database is unavailable, so that other systems won’t also become unavailable. Proceed with great caution!
Failing open
Failing open avoids lockout and simplifies recovery, but also poses a dangerous tradeoff: this strategy circumvents an important access protection against misuse or attack. Even partial fail-open scenarios may cause problems. For example, imagine that a system the certificate validity database depends on goes down. Let’s suppose the database depends on a time or epoch service, but accepts all properly signed credentials. If the certificate validity database cannot reach the time/epoch service, then an attacker who performs a relatively simple denial-of-service attack—such as overwhelming network links to the time/epoch service—may be able to reuse even extremely old revoked credentials. This attack works because revoked certificates are once again valid while the DoS attack persists. An attacker may breach your network or find new ways to propagate through the network while you’re trying to recover.
Instead of failing open, you may want to distribute known good data from the revocation service to individual servers in the form of a revocation list, which nodes can cache locally. Nodes then proceed with their best understanding of the state of the world until they obtain better data. This choice is far more secure than a time-out-and-fail-open policy.
Handling emergencies directly
In order to revoke keys and certificates quickly, you may want to design infrastructure to handle emergencies directly by deploying changes to a server’s authorized_users or Key Revocation List (KRL) files.15 This solution is troublesome for recovery in several ways.
It’s especially tempting to manage authorized_keys or known_hosts files directly when dealing with small numbers of nodes, but doing so scales poorly and smears ground truth across your entire fleet. It is very difficult to ensure that a given set of keys has been removed from the files on all servers, particularly if those files are the sole source of truth.
Instead of managing authorized_keys or known_hosts files directly, you can ensure update processes are consistent by centrally managing keys and certificates, and distributing state to servers through a revocation list. In fact, deploying explicit revocation lists is an opportunity to minimize uncertainty during risky situations when you’re moving at maximum speed: you can use your usual mechanisms for updating and monitoring files—including your rate-limiting mechanisms—on individual nodes.
Removing dependency on accurate notions of time
Using explicit revocation has another advantage: for certificate validation, this approach removes the dependency on accurate notions of time. Whether it’s caused by accident or malice, incorrect time wreaks havoc on certificate validation. For example, old certificates may suddenly become valid again, letting in attackers, and correct certificates may suddenly fail validation, causing a service outage. These are complications you don’t want to experience during a stressful compromise or service outage.
It’s better for your system’s certificate validation to depend on aspects you directly control, such as pushing out files containing root authority public keys or files containing revocation lists. The systems that push the files, the files themselves, and the central source of truth are likely to be much better secured, maintained, and monitored than the distribution of time. Recovery then becomes a matter of simply pushing out files, and monitoring only needs to check whether these are the intended files—standard processes that your systems already use.
Revoking credentials at scale
When using explicit revocation, it’s important to consider the implications of scalability. Scalable revocation requires care, because an attacker who has partially compromised your systems can use this partial compromise as a powerful tool to deny further service—maybe even revoking every valid credential in your entire infrastructure. Continuing the SSH example mentioned earlier, an attacker may try to revoke all SSH host certificates, but your machines need to support operations like updating a KRL file in order to apply new revocation information. How do you safeguard those operations against abuse?
When updating a KRL file, blindly replacing the old file with a new one is a recipe for trouble16—a single push can revoke every valid credential in your entire infrastructure. One safeguard is to have the target server evaluate the new KRL before applying it, and refuse any update that revokes its own credentials. A KRL that revokes the credentials of all hosts is ignored by all hosts. Because an attacker’s best strategy is to revoke half your machines, you have a worst-case guarantee that at the very least, half of your machines will still function after each KRL push. It’s much easier to recover and restore half of your infrastructure than all of it.17
Avoiding risky exceptions
Because of their size, large distributed systems may encounter issues distributing revocation lists. These issues may limit how quickly you can deploy a new revocation list, and slow your response time when removing compromised credentials.
To address this shortcoming, you might be tempted to build a dedicated “emergency” revocation list. However, this solution may be less than ideal. Since you will rarely use that emergency list, the mechanism is less likely to work when you need it the most. A better solution is to shard your revocation list so that you update it incrementally. That way, revoking credentials during an emergency requires updating only a subset of the data. Consistently using sharding means that your system always uses a multipart revocation list, and you use the same mechanisms under both normal and emergency circumstances.
Similarly, beware of adding “special” accounts (such as accounts offering direct access to senior employees) that circumvent revocation mechanisms. These accounts are very attractive targets for attackers—a successful attack on such an account might render all of your revocation mechanisms ineffective.
Know Your Intended State, Down to the Bytes
Recovery from any category of errors—whether they’re random, accidental, malicious, or software errors—requires returning the system to a known good state. Doing so is much easier if you actually know the intended state of the system and have a means to read the deployed state. This point may seem obvious, but not knowing the intended state is a common source of problems. The more thoroughly you encode the intended state and reduce the mutable state at every layer—per service, per host, per device, and so on—the easier it is to recognize when you return to a good working state. Ultimately, thoroughly encoding the intended state is the foundation of excellent automation, security, intrusion detection, and recovery to a known state.
Host management
Let’s say you manage an individual host, such as a physical machine, a virtual machine, or even a simple Docker container. You’ve set up the infrastructure to perform automated recovery, and this brings a lot of value because it efficiently handles many of the issues that may occur, such as those discussed in detail in Chapter 7 of the SRE book. In order to enable automation, you need to encode the state of that individual machine, including the workloads running on it. You encode enough of this information to let automation safely return the machine to a good state. At Google, we apply this paradigm at every layer of abstraction, up and down the hardware and software stack.
Google’s system that distributes our host’s software packages to the fleet of machines, as described in Design to Go as Quickly as Possible (Guarded by Policy), continually monitors the entire state of the system in an unconventional way. Each machine continually watches its local filesystem, maintaining a map that includes the name and a cryptographic checksum of each file in the filesystem. We gather those maps with a central service and compare them with the assigned set of packages—that is, the intended state—for each machine. When we find a deviation between the intended state and the current state, we append that information to a list of deviations.
Because it unifies various means of recovery into one process, the strategy of capturing the state of the machine gives powerful advantages for recovery. If a cosmic ray randomly corrupts a bit on disk, we discover the checksum mismatch and repair the deviation. If the intended state of the machine changes because a software rollout for one component inadvertently changes a file for a different component, altering the contents of that file, we repair the deviation. If someone attempts to modify the local configuration of a machine outside of the normal management tooling and review process (either accidentally or maliciously), we repair that deviation too. You might instead choose to repair deviations by reimaging the entire system—an approach that’s less sophisticated and easier to implement, but more disruptive at scale.
In addition to capturing the state of files on disk, many applications also have a corresponding in-memory state. An automated recovery must repair both states. For example, when an SSH daemon starts, it reads its configuration from disk and does not reload the configuration unless instructed to do so. To ensure that in-memory state is updated as needed, each package is required to have an idempotent post_install command,18 which runs whenever a deviation in its files is being repaired. The OpenSSH package’s post_install restarts the SSH daemon. A similar pre_rm command cleans up any in-memory state before the files are removed. These simple mechanisms can maintain all of the in-memory state of the machine, and report and repair deviations.
Encoding this state lets automation inspect every deviation for any malicious discrepancies. The rich information on the state of your machines is also extremely valuable during the forensic analysis that follows a security incident, helping you better understand the attacker’s actions and intent. For example, perhaps the attacker found a way to deposit malicious shellcode on some of your machines, but wasn’t able to reverse-engineer the monitoring and repair system, which reverted the unexpected changes on one or more machines. It will be much harder for the attacker to cover their tracks because the central service will have noticed and logged the deviations reported by the host.19
In summary, all state changes are equal at this level of abstraction. You can automate, secure, and validate all state changes in a similar way, treating both a rollback of a binary that failed canary analysis and an emergency rollout of an updated bash binary as routine changes. Using the same infrastructure enables you to make consistent policy decisions about how quickly to apply each change. Rate limits at this level protect against unintended collisions between the types of changes and establish a maximum acceptable rate of change.
Device firmware
For firmware updates, you may also capture state further down the stack. The individual pieces of hardware in a modern computer have their own software and configuration parameters. In the interest of safety and reliability, you should at least track the version of each device’s firmware. Ideally, you should capture all the settings available to that firmware, and ensure they’re set to their expected values.
When managing the firmware and its configuration on Google’s machines, we leverage the same systems and processes that we use to manage updates to our host software and for deviation analysis (see Host management). Automation securely distributes the intended state for all the firmware as a package, reports back any deviations, and repairs the deviations according to our rate-limiting policies and other policies on handling disruption.
The intended state is often not directly exposed to the local daemon monitoring the filesystem, which has no special knowledge of device firmware. We decouple the complexity of interacting with the hardware from this daemon by allowing each package to reference an activation check—a script or binary in the package that runs periodically to determine if the package is correctly installed. The script or binary does whatever is necessary to talk to the hardware and compare the firmware version and configuration parameters, and then reports any unexpected deviations. This functionality is especially useful for recovery, because it empowers subject matter experts (i.e., subsystem owners) to take appropriate steps to remedy problems in their area of expertise. For example, automation keeps track of target state, current state, and deviations. If a machine is targeted to run BIOS version 3 but is currently running BIOS version 1, the automation has no opinion about BIOS version 2. The package management scripts determine if they can upgrade the BIOS to version 3, or if unique constraints require walking a subsystem through multiple installed versions.
A few specific examples illustrate why managing the intended state is critical for both security and reliability. Google uses special vendor-supplied hardware to interface with external time sources (for example, GNSS/GPS systems and atomic clocks) to facilitate accurate timekeeping in production—a precondition for Spanner.20 Our hardware stores two different firmware versions, on two different chips on the device. In order to correctly operate these time sources, we need to carefully configure these firmware versions. As an added complication, some versions of the firmware have known bugs that affect how they handle leap seconds and other edge cases. If we don’t carefully maintain the firmware and settings on these devices, we can’t provide accurate time in production. It’s important that state management also covers fallback, secondary, or otherwise inactive code or configuration that may suddenly become live during recovery—recovery is a bad time to start figuring out what bugs reside in an inactive image. In this case, if the machines boot but the clock hardware doesn’t provide an accurate enough time to run our services, then our system hasn’t sufficiently recovered.
To provide another example, a modern BIOS has numerous parameters critical to the security of a booting (and a booted) system. For instance, you may want the boot order to prefer SATA over USB boot devices in order to prevent a malicious actor in a datacenter from easily booting the system from a USB drive. More advanced deployments track and maintain the database of keys allowed to sign BIOS updates, both to manage rotations and to guard against tampering. If your primary boot device experiences a hardware failure during recovery, you don’t want to discover that your BIOS is stuck waiting for keyboard input because you forgot to monitor and specify the settings for the secondary boot device.
Global services
The highest layer of abstraction in your service, and the most persistent parts of your infrastructure—for example, storage, naming, and identity—may be the hardest areas for your system to recover. The paradigm of capturing state also applies to these high levels of the stack. When building or deploying new global singleton systems like Spanner or Hadoop, make sure you support multiple instances—even if you never plan to use more than one instance, and even for the very first deployment. Beyond backups and restores, you might need to rebuild a new instance of the entire system to restore the data on that system.
Instead of setting up your services by hand, you might set them up by writing imperative turnup automation or using a declarative high-level configuration language (e.g., a container orchestration configuration tool like Terraform). In these scenarios, you should capture the state of how the service is created. Doing so is analogous to the way test-driven development captures the intended behavior of your code, which then guides your implementation and helps clarify the public API. Both practices lead to more maintainable systems.
The popularity of containers, which are often hermetically built and deployed from source, means that the state of many building blocks of global services is captured by default. While automatically capturing “most” of a service’s state is great, don’t be lulled into a false sense of security. Restoring your infrastructure from scratch requires exercising a complex chain of dependencies. This may lead you to uncover unexpected capacity problems or circular dependencies. If you run on physical infrastructure, ask yourself: do you have enough spare machines, disk space, and network capacity to bring up a second copy of your infrastructure? If you run on a large cloud platform like GCP or AWS, you may be able to purchase as many physical resources as you need, but do you have enough quota to use these resources on short notice? Have your systems organically grown any interdependencies that prevent a clean startup from scratch? It can be useful to conduct disaster testing under controlled circumstances to make sure you’re prepared for the unexpected.21
Persistent data
No one cares about backups; they only care about restores.22
So far, we’ve focused on securely restoring the infrastructure necessary to run your service. This is sufficient for some stateless services, but many services also store persistent data, which adds a special set of challenges. There’s a lot of excellent information out there on the challenges of backing up and restoring persistent data.23 Here, we discuss some key aspects in relation to security and reliability.
To defend against the types of errors mentioned earlier—especially malicious errors—your backups need the same level of integrity protection as your primary storage. A malicious insider may change the contents of your backups, and then force a restore from a corrupted backup. Even if you have strong cryptographic signatures that cover your backups, those signatures are useless if your restore tooling doesn’t validate them as part of the restore process, or if your internal access controls don’t properly restrict the set of humans who can manually make signatures.
It’s important to compartmentalize the security protection of persistent data where possible. If you detect corruption in your serving copy of the data, you should isolate the corruption to the smallest subset of data that’s practical. Restoring 0.01% of your persistent data is much faster if you can identify that subset of the backup data and validate its integrity without reading and validating the other 99.99% of the data. This ability becomes especially important as the size of the persistent data grows, although if you’re following best practices for large distributed system design, compartmentalization generally occurs naturally. Calculating the chunk size for compartmentalization often requires a tradeoff between storage and compute overhead, but you should also consider the effect of chunk size on MTTR.
You should account for how frequently your system requires partial restores, too. Consider how much common infrastructure is shared between your systems that are involved in restores and data migrations: a data migration is usually very similar to a low-priority partial restore. If every data migration—whether to another machine, rack, cluster, or datacenter—exercises and builds confidence in the critical parts of your recovery system, you’ll know that the infrastructure involved is more likely to work and be understood when you need it the most.
Data restores may also introduce their own security and privacy issues. Deleting data is a necessary and often legally required function for many systems.24 Make sure that your data recovery systems don’t inadvertently allow you to restore data that’s assumed to be destroyed. Be conscious of the distinction between deleting encryption keys and deleting encrypted data. It may be efficient to render data inaccessible by destroying the relevant encryption keys, but this approach requires compartmentalizing the keys used for various types of data in a way that’s compatible with the requirements of granular data deletion.
Design for Testing and Continuous Validation
As discussed in Chapter 8, continuous validation can help maintain a robust system. To be prepared for recovery, your testing strategy needs to include tests of recovery processes. By their nature, recovery processes perform unusual tasks under unfamiliar conditions, and without testing they will encounter unforeseen challenges. For example, if you are automating the creation of a clean system instance, a good test design may uncover an assumption that a particular service will have only one global instance, and so help identify situations where it’s difficult to create a second instance for the restoration of that service. Consider testing conceivable recovery scenarios so that you strike the right balance between test efficiency and production realism.
You may also consider testing niche situations where recovery is especially difficult. For example, at Google we implement a cryptographic key management protocol in a diverse set of environments: Arm and x86 CPUs, UEFI and bare-metal firmware, Microsoft Visual C++ (MSVC), Clang, GCC compilers, and so on. We knew that exercising all the failure modes for this logic would be challenging—even with substantial investment in end-to-end testing, it’s difficult to realistically emulate hardware failures or interrupted communication. Instead, we opted to implement the core logic once, in a portable, compiler-neutral, bit width–neutral way. We unit tested the logic extensively, and paid attention to the interface design for abstract external components. For example, in order to fake individual components and exercise their failure behavior, we created interfaces for reading and writing bytes from flash, for cryptographic key storage, and for performance-monitoring primitives. This method of testing environmental conditions has withstood the test of time, since it explicitly captures the classes of failure from which we want to recover.
Finally, look for ways to build confidence in your recovery methods via continuous validation. Recovery involves actions taken by humans, and humans are unreliable and unpredictable. Unit tests alone, or even continuous integration/delivery/deployment, cannot catch mistakes resulting from human skills or habits. For example, in addition to validating the effectiveness and interoperability of recovery workflows, you must validate that recovery instructions are readable and easy to comprehend.
Emergency Access
The recovery methods described in this chapter rely on a responder’s ability to interact with the system, and we’ve advocated for recovery processes that exercise the same primary services as normal operations. However, you may need to design a special-purpose solution to deploy when normal access methods are completely broken.
Organizations usually have unique needs and options for emergency access. The key is to have a plan and build mechanisms that maintain and protect that access. In addition, you need to be aware of system layers outside your control—any failures in those layers are not actionable, even though they impact you. In these cases, you may need to stand by while someone else fixes the services your company depends on. To minimize the impact of third-party outages on your service, look for any potential cost-effective redundancies you can deploy at any level of your infrastructure. Of course, there may not be any cost-effective alternatives, or you may already have reached the top SLA your service provider guarantees. In that case, remember that you’re only as available as the sum of your dependencies.25
Google’s remote access strategy centers around deploying self-contained critical services to geographically distributed racks. To anchor recovery efforts, we aim to provide remote access control, efficient local communications, alternative networking, and critical fortified points in the infrastructure. During a global outage, since each rack remains available to at least some portion of responders, responders can start to fix the services on the racks they can access, then radially expand the recovery progress. In other words, when global collaboration is practically impossible, arbitrary smaller regions can to try to fix the issues themselves. Despite the fact that responders may lack the context to discover where they’re needed the most, and the risk of regions diverging, this approach may meaningfully accelerate recovery.
Access Controls
It’s critical that the organization’s access control services don’t become single points of failure for all remote access. Ideally, you’ll be able to implement alternative components that avoid the same dependencies, but the reliability of these alternative components may require different security solutions. While their access policies must be equally strong, they may be less convenient and/or have a degraded feature set, for technical or pragmatic reasons.
Because they rely on dependencies that may be unavailable, remote access credentials cannot depend on typical credential services. Therefore, you can’t derive access credentials from the dynamic components of access infrastructure, like single sign-on (SSO) or federated identity providers, unless you can replace those components with low-dependency implementations. In addition, choosing the lifetime of those credentials poses a difficult risk management tradeoff: the good practice of enforcing short-term access credentials for users or devices becomes a time bomb if the outage outlasts them, so you’re forced to expand the lifetime of the credentials to exceed the length of any anticipated outages, despite the additional security risk (see Time Separation). Furthermore, if you are issuing remote access credentials proactively on a fixed schedule rather than activating them on demand at the start of an outage, an outage may begin just as they are about to expire.
If the network access employs user or device authorization, any reliance on dynamic components has risks similar to the risks the credentials service faces. As increasingly more networks use dynamic protocols,26 you may need to provide alternatives that are more static. Your list of available network providers may limit your options. If dedicated network connections with static network access controls are feasible, make sure their periodic updates don’t break either routing or authorization. It may be especially important to implement sufficient monitoring to detect where inside the network access breaks, or to help distinguish network access issues from the issues in the layers above the network.
Communications
Emergency communication channels are the next critical factor in emergency response. What should on-callers do when their usual chat service is down or unreachable? What if that chat service is compromised or being eavesdropped on by the attacker?
Pick a communications technology (e.g., Google Chat, Skype, or Slack) that has as few dependencies as possible and is useful enough for the size of your responder teams. If that technology is outsourced, is the system reachable by the responders, even if the system layers outside your control are broken? Phone bridges, though inefficient, also exist as an old-school option, though they’re increasingly deployed using IP telephony that depends on the internet. Internet Relay Chat (IRC) infrastructure is reliable and self-contained if your company wants to deploy its own solution, but it lacks some security aspects. Additionally, you still have to make sure your IRC servers remain somewhat accessible during network outages. When your communication channels are hosted outside your own infrastructure, you may also want to consider whether the providers guarantee enough authentication and confidentiality for your company’s needs.
Responder Habits
The uniqueness of emergency access technologies often results in practices distinct from normal day-to-day operations. If you don’t prioritize the end-to-end usability of these technologies, responders may not know how to use them in an emergency, and you’ll lose the benefits of those technologies. It may be difficult to integrate low-dependency alternatives, but that’s only part of the problem—once you mix in human confusion under stress with rarely used processes and tools, the resulting complexity may obstruct all access. In other words, humans, rather than technology, may render breakglass tools ineffective.27
The more you can minimize the distinction between normal and emergency processes, the more responders are able to draw on habit. This frees up more of their cognitive capacity to focus on what does differ. As a result, organizational resilience to outages may improve. For example, at Google, we centralized on Chrome, its extensions, and any controls and tools associated with it as the single platform sufficient for remote access. Introducing an emergency mode into Chrome extensions allowed us to achieve the minimum possible increase in cognitive load up front, while retaining the option to integrate it into more extensions later.
To ensure that your responders exercise emergency access practices regularly, introduce policies that integrate emergency access into the daily habits of on-call staff, and continuously validate the usability of the relevant systems. For example, define and enforce a minimum period between required exercises. The team lead can send email notifications when a team member needs to complete required credential-refresh or training tasks, or may choose to waive the exercise if they determine that the individual regularly engages in equivalent activities. This increases confidence that when an incident occurs, the rest of the team does have the relevant credentials and has recently completed the necessary training. Otherwise, make practicing breakglass operations and any related processes mandatory for your staff.
Finally, make sure that relevant documentation, such as policies, standards, and how-to guides, is available. People tend to forget details that are rarely used, and such documentation also relieves stress and doubt under pressure. Architecture overviews and diagrams are also helpful for incident responders, and bring people who are unfamiliar with the subject up to speed without too much dependence on subject matter experts.
Unexpected Benefits
The design principles described in this chapter, built on top of principles of resilient design, improve your system’s ability to recover. Unexpected benefits beyond reliability and security might help you convince your organization to adopt these practices. Consider a server engineered for firmware update authentication, rollback, locking, and attestation mechanisms. With these primitives, you may confidently recover a machine from a detected compromise. Now consider using this machine in a “bare metal” cloud hosting service, where the provider wants to clean and resell machines using automation. The machines engineered with recovery in mind already have a secure and automated solution in place.
The benefits compound even further with respect to supply chain security. When machines are assembled from many different components, you need to pay less attention to supply chain security for components whose integrity is recovered in an automated way. Your first-touch operations simply require running a recovery procedure. As an extra bonus, repurposing the recovery procedure means that you exercise your critical recovery capabilities regularly, so your staff is ready to act when an incident occurs.
Designing systems for recovery is considered an advanced topic, whose business value is proven only when a system is out of its intended state. But, given that we recommend operating systems use an error budget to maximize cost efficiency,28 we expect such systems to be in an error state regularly. We hope your teams will slowly start investing in rate-limiting or rollback mechanisms as early in the development process as possible. For more insights about how to influence your organization, see Chapter 21.
Conclusion
This chapter explored various aspects of designing systems for recovery. We explained why systems should be flexible in terms of the rate at which they deploy changes: this flexibility allows you to roll out changes slowly when possible and avoid coordinated failures, but also to roll out changes quickly and confidently when you have to accept more risk to meet security objectives. The ability to roll back changes is essential for building reliable systems, but sometimes you may need to prevent rollback to versions that are insecure or sufficiently old. Understanding, monitoring, and reproducing the state of your system to the greatest extent possible—through software versions, memory, wall-clock time, and so on—is key to reliably recovering the system to any previously working state, and ensuring that its current state matches your security requirements. As a last resort, emergency access permits responders to remain connected, assess a system, and mitigate the situation. Thoughtfully managing policy versus procedure, the central source of truth versus local functions, and the expected state versus the system’s actual state paves the way to recoverable systems, while also promoting resilience and robust everyday operations.