MannequinChallenge
A Dataset of Frozen People
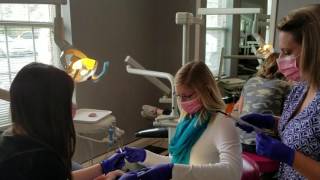











MannequinChallenge is a dataset of video clips of people imitating mannequins, i.e., freezing in diverse, natural poses, while a hand-held camera tours the scene. The dataset comprises of more than 170K frames and corresponding camera poses derived from about 2,000 YouTube videos. The camera poses were computed using SLAM and bundle adjustment algorithms.
For more details on how we created the dataset see our CVPR 2019 paper, Learning the Depths of Moving People by Watching Frozen People. The MannequinChallenge dataset was used to train a deep network model for predicting dense depth maps from ordinary videos where both the camera and the people in the scene are freely moving. Because people are stationary and captured from different viewpoints, Multi-View Stereo (MVS) was used to estimate dense depth maps, which serveed as supervision during training.
This dataset is intended to aid researchers in their work on view synthesis, 3D computer vision, and beyond.
Ready to start using MannequinChallenge?