How it works
This document provides a high-level description of how FuzzBench works end-to-end. It isn’t necessary for users of the FuzzBench service to know most of these details.
Overview
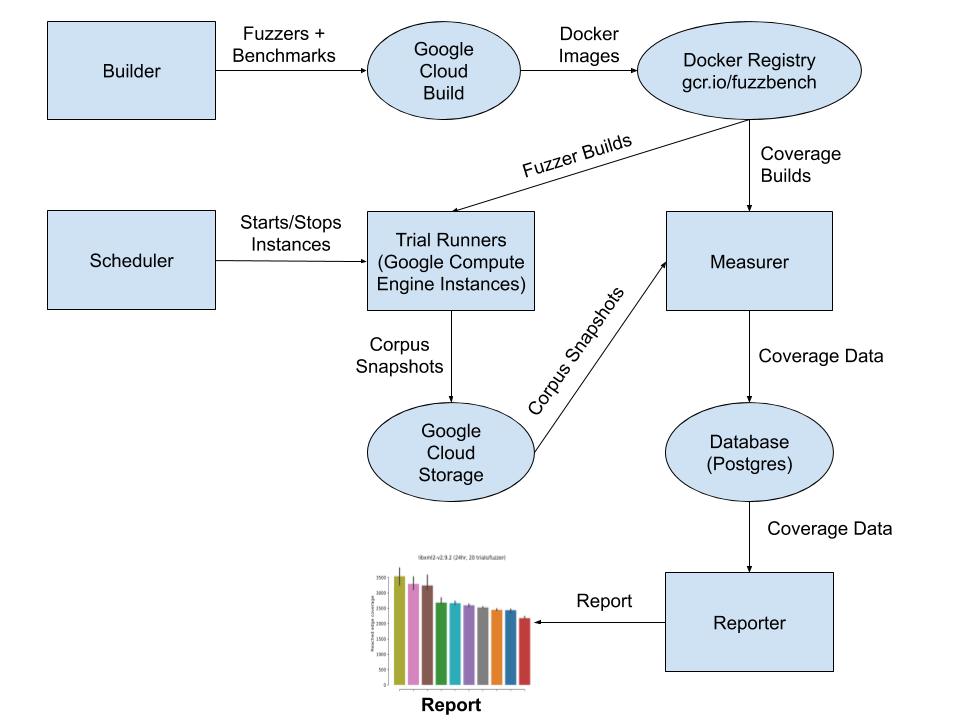
Dispatcher
As mentioned in the guide to running an experiment, run_experiment.py creates a Google Compute Engine (GCE) instance called the dispatcher to run an experiment. In addition to referring to the instance, “dispatcher” can also refer to the script/process the instance runs. The dispatcher (script) doesn’t actually do much on its own. It does some basic initialization like saving details about the experiment to the database and then starts four other major components - the builder, the scheduler, the measurer, and the reporter. All of these components run on the dispatcher instance (note that we don’t include it in the architecture diagram because of its unique role).
Builder
The builder produces a build for each fuzzer-benchmark pair needed by the experiment and does a coverage build for each benchmark. The builder uses the Google Cloud Build service for building the docker images needed by the experiment since it is faster and simpler than building them on GCE instances. When the builder finishes doing the needed builds, it terminates. Thus, unlike other components, it isn’t running for the duration of an experiment.
Builds
Details on how builds work are provided in the guide to adding a new fuzzer and the guide to adding a new benchmark. Note that we use AddressSanitizer for the benchmark builds of most fuzzers (i.e. all of them support it) so that it will be easier to add support for measuring performance based on crashes.
Scheduler
Once the builder has finished, the dispatcher starts the scheduler. The scheduler is responsible for starting and stopping trial runners, which are instances on GCE. The scheduler will continuously try to create instances for trials that haven’t run yet. This means that if an experiment requires too many resources from Google Cloud to complete at once, it can still be run anyway after some resources are freed up by trials that have finished running. The scheduler stops trials after they have run for the amount of time specified when starting the experiment. The scheduler stops running after all trials finish running.
Trial runners
Trial runners are GCE instances that fuzz benchmarks. They start by pulling the docker images that were produced by the builder and uploaded to the container registry. Then, from within the container, they run runner.py which calls the fuzz function from the fuzzer.py file for the specified fuzzer (example). The runner will also periodically archive the current output_corpus and sync it to Google Cloud Storage (this is sometimes referred to as a “corpus snapshot”). The runner terminates when it has run the fuzz function for the time specified for each trial when starting the experiment.
Measurer
The role of the measurer is to take the output of the trial runners and make it usable for generating reports. To do this, the measurer downloads coverage builds for each benchmark and then continuously downloads corpus snapshots, measures their coverage, and saves the result to the database, a PostgreSQL instance running on Google Cloud SQL. The measurer terminates when there is no corpus snapshot for this experiment that hasn’t been measured. Because the measurer is run on the dispatcher instance, it can’t scale with the size of an experiment, so it can actually finish after the experiment is done (usually a few hours after the end of an experiment). The dispatcher instance terminates after the measurer terminates itself.
Coverage builds
Running coverage builds does not require any dependencies that aren’t available on the dispatcher. One reason for this is because OSS-Fuzz only allows projects (which are used as benchmarks) to install dependencies in the docker container they use for building, and not in the one they use for fuzzing. Therefore, the measurer, doesn’t actually use the images from coverage builds, it simply runs the binaries directly on the dispatcher.
Reporter
The role of the reporter is to convert coverage (and other data in the future) data output by the measurer into a human consumable report. It runs continuously in a loop while the dispatcher is alive, consuming the coverage data from the SQL database and then outputting an HTML report which it saves to a Google Cloud Storage bucket (which you can access by going to fuzzbench.com/reports/).