Running ClusterFuzzLite
Before running ClusterFuzzLite, you must integrate your project with ClusterFuzzLite’s build system to build your project’s fuzzers. See Step 1: Build Integration if you haven’t already taken this step.
Overview
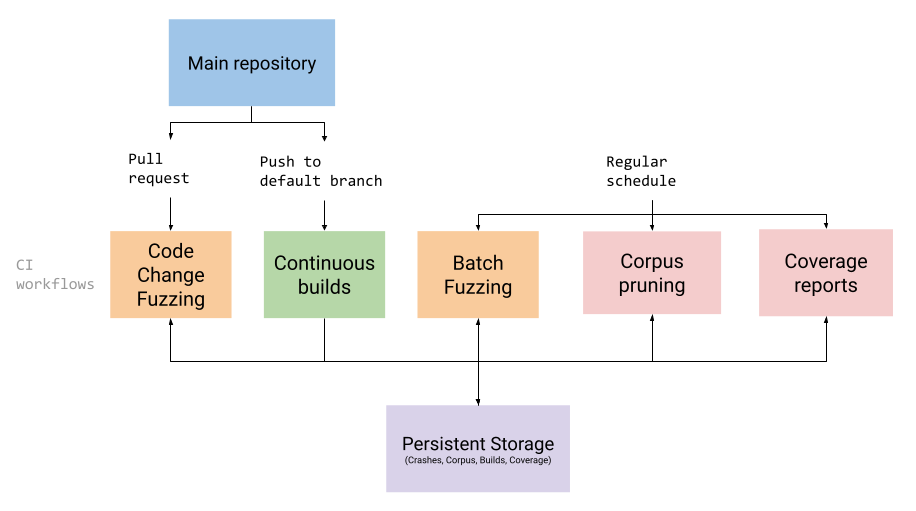
The exact method for running ClusterFuzzLite will depend on which CI system you are using. The rest of this page explains important concepts and configuration options that are agnostic to which CI system you are using. After reading this page, see the subguides for instructions specific to your particular CI system (e.g. GitHub Actions or Google Cloud Build).
ClusterFuzzLite Modes
ClusterFuzzLite offers two primary modes of fuzzing: code change fuzzing and batch fuzzing. ClusterFuzzLite also offers two helper modes for running fuzzers that don’t actually fuzz but provide useful functionality: prune and coverage. ClusterFuzzLite can be instructed to perform any of these functions using the “mode” option.
Code Change Fuzzing (“code-change”)
The core way to use ClusterFuzzLite is to fuzz code changes that were introduced in a pull request/code review or commit. Code change fuzzing allows ClusterFuzzLite to find bugs before they are commited into your code and while they are easiest to fix.
Code change fuzzing is designed to be fast so that it integrates easily into your development workcycle:
- It defaults to fuzzing for 10 minutes, though this can be changed.
- It quits after finding a single crash, even if there are other fuzzers to run.
Running only code change fuzzing is the easiest way to use ClusterFuzzLite. However, we suggest using code change fuzzing in conjunction with other modes to gain ClusterFuzzLite’s full benefits.
For example, running batch fuzzing will develop a corpus that can be used by code change fuzzing. (If no corpus is available from batch fuzzing, code change fuzzing will start from nothing or the provided seed corpus.) Furthermore, when you first use ClusterFuzzLite, code change fuzzing will not report the bugs that already exist in your codebase, while batch fuzzing will. See also Code Coverage Report Generation and Continuous Builds for additional functionalities. 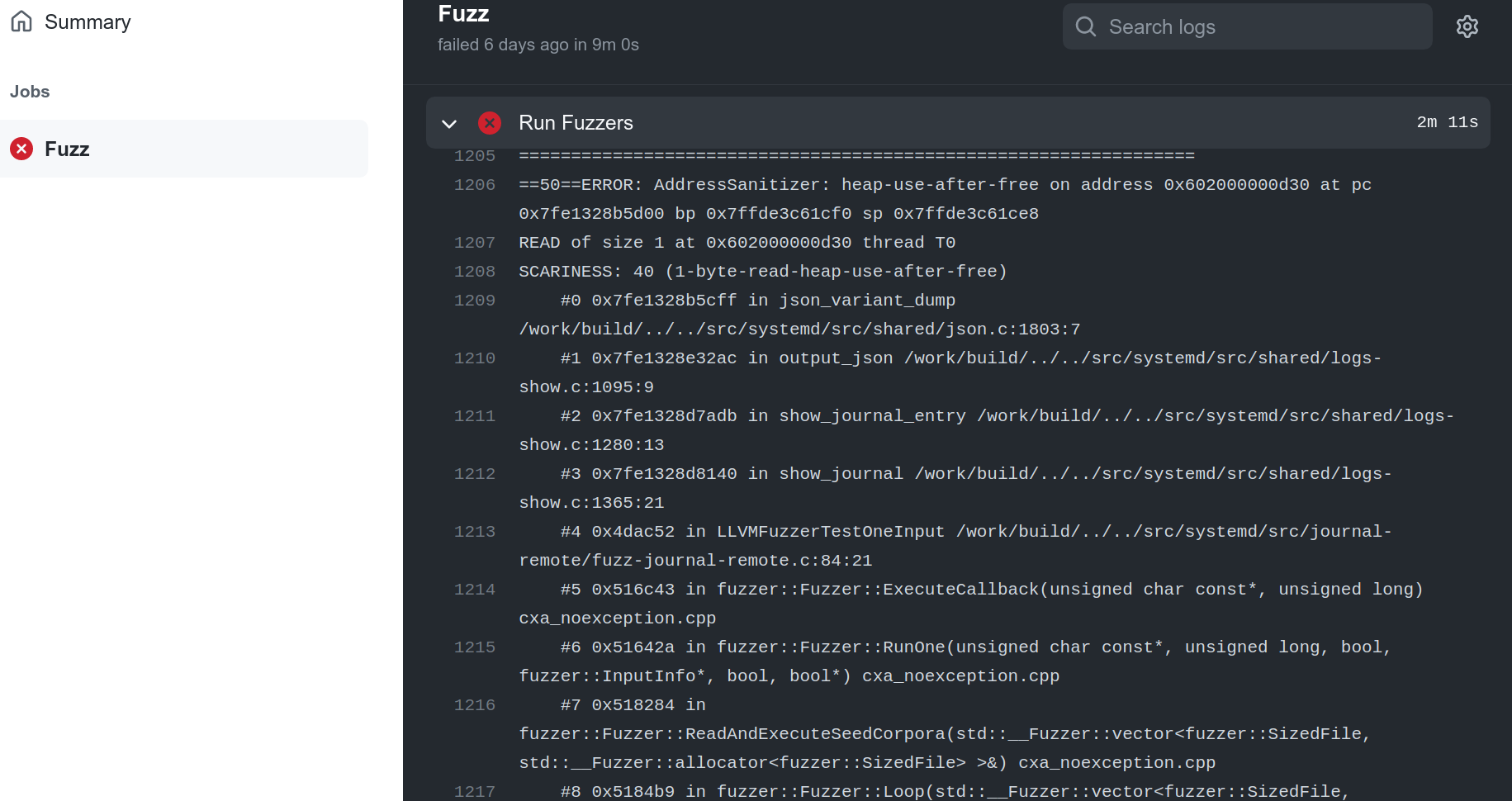
Batch Fuzzing (“batch”)
In batch fuzzing mode all fuzzers are run for a preset, longer, amount of time. Unlike in code change mode, batch fuzzing will not exit immediately upon discovering a bug. It will keep running other fuzzers until reaching the allotted fuzzing time.
Given the longer runtime, we suggest batch fuzzing should be run on a schedule such as once daily, rather than on code changes.
By running for a longer amount of time, batch fuzzing serves two important purposes:
- It can find bugs that are missed or are not reported by code change fuzzing. Note that batch fuzzing reports all crashes, not just “new” ones.
- It builds a corpus for each of your fuzz targets, leading to more code coverage and better bug discovery. This corpus will be used by Code coverage report generation, code change fuzzing, and later runs of batch fuzzing. The corpus is saved using your CI system’s feature for storing files.
Corpus Pruning (“prune”)
Over time, redundant testcases will get introduced into your fuzzer’s corpuses during batch fuzzing.
Corpus pruning is a helper function that minimizes the corpuses by removing corpus files (testcases) that do not increase the fuzzer’s code coverage.
If you are using batch fuzzing, you should run corpus pruning once a day to prevent buildup of these redundant testcases and keep fuzzing efficient. Corpus pruning should be considered mandatory when you are using batch fuzzing but otherwise should not be used.
Code Coverage Report Generation (“coverage”)
Code coverage report generation is a helper function that can be used when batch fuzzing is enabled. This mode uses the corpus developed during batch fuzzing to generate an HTML coverage report that shows which parts of your code are covered by fuzzing.
The data from coverage reports is also used by code change fuzzing to determine which fuzzers are affected by a code change. If code change fuzzing can determine which fuzzers are affected, it will run only those fuzzers. Otherwise, it will run all of them. Coverage report generation uses the corpuses saved by batch fuzzing and therefore should only be used if batch fuzzing is enabled. It is not required if batch fuzzing is enabled, but is strongly recommended. 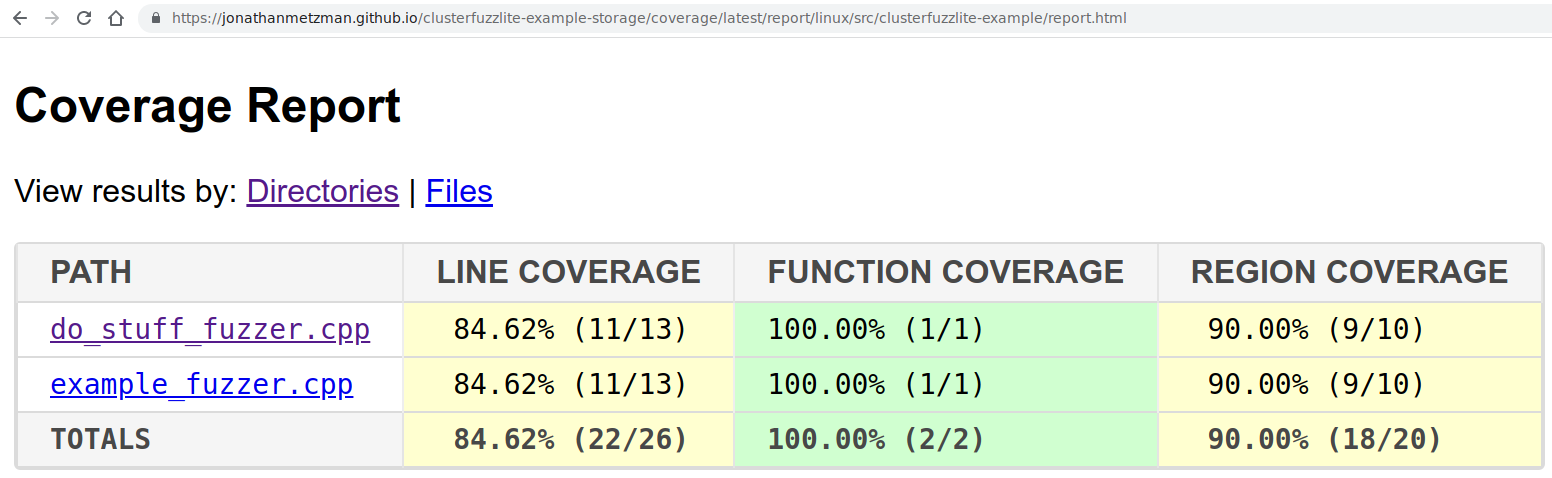
Continuous Builds
Continuous builds are not actually a mode of running fuzzers but is an additional “task” for ClusterFuzzLite that you can set up. Instead of running the fuzzers after building them, the continuous builds task saves the builds for later use by the code change fuzzing mode.
The continuous builds task enables code change fuzzing to identify whether the cause of a crash was introduced by the code change. With the continuous builds task, if the cause of the crash was pre-existing, the crash is not reported by code change fuzzing. If code change fuzzing is run without the continuous builds task, all crashes will be reported.
Configuration Options
This section is an overview of the configuration options you can set when running ClusterFuzzLite. See the subguides for details on how to set each configuration within your specific CI system.
-
language: The language your target code is written in. Defaults toc++. This should be the same as the value you set inproject.yaml. See this explanation for more details. -
fuzz-seconds: Instructs ClusterFuzzLite on how long to spend fuzzing, in seconds. The default is 600 seconds, which is an appropriate starting point for code change fuzzing. You should increase this number to spend more time batch fuzzing. -
sanitizer: Determines the sanitizer to build and run fuzz targets with. The choices are'address','undefined','memory'and'coverage'(for coverage report generation). The default is'address'. See Sanitizers for more information. -
parallel-fuzzing: Whether to use all available CPU cores for fuzzing. The default value isfalse, which only uses a single CPU core. When set totrue, ClusterFuzzLite runs multiple fuzzer processes in parallel with a shared corpus directory. New inputs found by one fuzzer process will be available to the other fuzzer processes. The number of cores available depends on your specific CI system. -
report-unreproducible-crashes: Whether to report unreproducible crashes. The default value isfalse. ClusterFuzzLite will always attempt to reproduce new crashes. Sometimes crashes can not be reproduced reliably, e.g., because the fuzz target is in a different state. Read more on non-reproducible bugs in this section. When set totrue, even non-reproducable bugs will be reported a as failure. -
minimize-crashes: Iftrue, reportable crashes will be minimized. The default value isfalse. Minimizing crashes reduces fuzzing time in batch fuzzing. -
mode: The mode for ClusterFuzzLite to execute.code-changeby default. See ClusterFuzzLite modes for more details on how to run different modes. -
dry-run: Determines if ClusterFuzzLite reports bugs/crashes. The default value isfalse. When set totrue, ClusterFuzzLite will never report a failure even if it finds a crash in your project, and users will have to manually check the logs for detected bugs. This should only be used for testing ClusterFuzzLite.
Note: Your specific CI system will determine how options are passed to ClusterFuzzLite. Because some CI systems will pass them using environment variables, the names of the environment variables can be slightly different than names of the corresponding options. In particular, environment variables will be all uppercase and use underscores (_) instead of hyphens (-). For example: the environment variable for fuzz-seconds is FUZZ_SECONDS.
At this point you are ready to run ClusterFuzzLite using your specific CI system!
Next: choose the subguide for your CI system.