GitHub Actions
This page explains how to set up ClusterFuzzLite to run on GitHub Actions. To get the most of this page, you should have already set up your build integration and read the more high-level document on running ClusterFuzzLite.
Workflow Files
For basic ClusterFuzzLite functionality, all you need is a single workflow file to enable fuzzing on your pull requests.
.github/workflows/cflite_pr.yml(for PR fuzzing)
To enable more features, we recommend having these additional files:
.github/workflows/cflite_build.yml(for continuous builds).github/workflows/cflite_batch.yml(for batch fuzzing).github/workflows/cflite_cron.yml(for tasks done on a cron schedule: pruning and coverage)
These workflow files are used by GitHub actions to run the ClusterFuzzLite actions. For a complete example on a real project, see https://github.com/oliverchang/curl.
Mode Configurations
The following configuration guides show default configuration settings for each workflow file. Simply copying the default settings should work for most projects, or you can choose to edit the files to customize the settings.
PR fuzzing
To add a fuzzing workflow that fuzzes all pull requests to your repo, add the following default configurations to .github/workflows/cflite_pr.yml:
name: ClusterFuzzLite PR fuzzing
on:
pull_request:
paths:
- '**'
permissions: read-all
jobs:
PR:
runs-on: ubuntu-latest
concurrency:
group: ${{ github.workflow }}-${{ matrix.sanitizer }}-${{ github.ref }}
cancel-in-progress: true
strategy:
fail-fast: false
matrix:
sanitizer:
- address
# Override this with the sanitizers you want.
# - undefined
# - memory
steps:
- name: Build Fuzzers (${{ matrix.sanitizer }})
id: build
uses: google/clusterfuzzlite/actions/build_fuzzers@v1
with:
language: c++ # Change this to the language you are fuzzing.
github-token: ${{ secrets.GITHUB_TOKEN }}
sanitizer: ${{ matrix.sanitizer }}
# Optional but recommended: used to only run fuzzers that are affected
# by the PR.
# See later section on "Git repo for storage".
# storage-repo: https://${{ secrets.PERSONAL_ACCESS_TOKEN }}@github.com/OWNER/STORAGE-REPO-NAME.git
# storage-repo-branch: main # Optional. Defaults to "main"
# storage-repo-branch-coverage: gh-pages # Optional. Defaults to "gh-pages".
- name: Run Fuzzers (${{ matrix.sanitizer }})
id: run
uses: google/clusterfuzzlite/actions/run_fuzzers@v1
with:
github-token: ${{ secrets.GITHUB_TOKEN }}
fuzz-seconds: 600
mode: 'code-change'
sanitizer: ${{ matrix.sanitizer }}
output-sarif: true
# Optional but recommended: used to download the corpus produced by
# batch fuzzing.
# See later section on "Git repo for storage".
# storage-repo: https://${{ secrets.PERSONAL_ACCESS_TOKEN }}@github.com/OWNER/STORAGE-REPO-NAME.git
# storage-repo-branch: main # Optional. Defaults to "main"
# storage-repo-branch-coverage: gh-pages # Optional. Defaults to "gh-pages".
Optionally, edit the following fields to customize your settings:
languageChange to the language of your target code.sanitizersChange or enable more sanitizers.fuzz-secondsChange the amount of time spent fuzzing.parallel-fuzzing: Use all available CPU cores for fuzzing.storage-repo,storage-repo-branch,storage-repo-branch-coverageEnable a storage repo (not necessary for initial runs, but a useful feature discussed later on).
Merge this file into your GitHub repo. To test the workflow, open a pull request to your project.
To download crashes from code change fuzzing, please see the section on downloading artifacts.
Batch fuzzing
Batch fuzzing enables continuous, regular fuzzing on your latest HEAD and allows a corpus of inputs to build up over time, which greatly improves the effectiveness of fuzzing. Batch fuzzing can be run on a cron schedule.
To enable batch fuzzing, add the following to .github/workflows/cflite_batch.yml:
name: ClusterFuzzLite batch fuzzing
on:
schedule:
- cron: '0 0/6 * * *' # Every 6th hour. Change this to whatever is suitable.
permissions: read-all
jobs:
BatchFuzzing:
runs-on: ubuntu-latest
strategy:
fail-fast: false
matrix:
sanitizer:
- address
# Override this with the sanitizers you want.
# - undefined
# - memory
steps:
- name: Build Fuzzers (${{ matrix.sanitizer }})
id: build
uses: google/clusterfuzzlite/actions/build_fuzzers@v1
with:
language: c++ # Change this to the language you are fuzzing.
sanitizer: ${{ matrix.sanitizer }}
- name: Run Fuzzers (${{ matrix.sanitizer }})
id: run
uses: google/clusterfuzzlite/actions/run_fuzzers@v1
with:
github-token: ${{ secrets.GITHUB_TOKEN }}
fuzz-seconds: 3600
mode: 'batch'
sanitizer: ${{ matrix.sanitizer }}
output-sarif: true
# Optional but recommended: For storing certain artifacts from fuzzing.
# See later section on "Git repo for storage".
# storage-repo: https://${{ secrets.PERSONAL_ACCESS_TOKEN }}@github.com/OWNER/STORAGE-REPO-NAME.git
# storage-repo-branch: main # Optional. Defaults to "main"
# storage-repo-branch-coverage: gh-pages # Optional. Defaults to "gh-pages".
Optionally, edit the following fields to customize your settings:
languageChange to the language of your target code.cronChange how frequently batch fuzzing is run. See GitHub’s documentation on this.sanitizersChange or enable more sanitizers.fuzz-secondsChange the amount of time spent fuzzing.parallel-fuzzing: Use all available CPU cores for fuzzing.storage-repo,storage-repo-branch,storage-repo-branch-coverageEnable a storage repo.
Though not recommended, you can configure batch fuzzing to run on each push to your main branch, change the on field to:
on:
push:
branches:
- main # Use your actual default branch here.
Make sure to change branches to the actual branch(es) you wish to fuzz.
NOTE: If batch fuzzing is running, you must also run corpus pruning.
Continuous builds
The continuous build task causes a build to be triggered and uploaded as a GitHub Actions artifact whenever a new push is done to main/default branch.
Continuous builds are used when a crash is found during PR fuzzing to determine whether the crash was newly introduced. If the crash is not novel, PR fuzzing will not report it. This means that there will be fewer unrelated failures when running code change fuzzing.
Disclaimer: If your builds are large they may exceed the free GitHub actions quotas. In this case it’s recommended to not enable continuous builds.
To set up continuous builds, add the following to .github/workflows/cflite_build.yml:
name: ClusterFuzzLite continuous builds
on:
push:
branches:
- main # Use your actual default branch here.
permissions: read-all
jobs:
Build:
runs-on: ubuntu-latest
concurrency:
group: ${{ github.workflow }}-${{ matrix.sanitizer }}-${{ github.ref }}
cancel-in-progress: true
strategy:
fail-fast: false
matrix:
sanitizer:
- address
# Override this with the sanitizers you want.
# - undefined
# - memory
steps:
- name: Build Fuzzers (${{ matrix.sanitizer }})
id: build
uses: google/clusterfuzzlite/actions/build_fuzzers@v1
with:
language: c++ # Change this to the language you are fuzzing.
sanitizer: ${{ matrix.sanitizer }}
upload-build: true
NOTE: Be sure to change the branches field to match your project’s main branch.
If you plan to use multiple sanitizers, add them all to the sanitizer field (to enable builds for each sanitizer)
Corpus pruning
Corpus pruning minimizes the corpus produced by batch fuzzing by removing redundant items while keeping the same code coverage. To enable this, add the following to .github/workflows/cflite_cron.yml:
name: ClusterFuzzLite cron tasks
on:
schedule:
- cron: '0 0 * * *' # Once a day at midnight.
permissions: read-all
jobs:
Pruning:
runs-on: ubuntu-latest
steps:
- name: Build Fuzzers
id: build
uses: google/clusterfuzzlite/actions/build_fuzzers@v1
with:
language: c++ # Change this to the language you are fuzzing
- name: Run Fuzzers
id: run
uses: google/clusterfuzzlite/actions/run_fuzzers@v1
with:
github-token: ${{ secrets.GITHUB_TOKEN }}
fuzz-seconds: 600
mode: 'prune'
output-sarif: true
# Optional but recommended.
# See later section on "Git repo for storage".
# storage-repo: https://${{ secrets.PERSONAL_ACCESS_TOKEN }}@github.com/OWNER/STORAGE-REPO-NAME.git
# storage-repo-branch: main # Optional. Defaults to "main"
# storage-repo-branch-coverage: gh-pages # Optional. Defaults to "gh-pages".
Optionally, edit the following field to customize your settings:
languageChange to the language of your target code.storage-repo,storage-repo-branch,storage-repo-branch-coverageEnable a storage repo.
Coverage reports
To generate periodic coverage reports, add the following to the jobs field in .github/workflows/cflite_cron.yml after the Pruning job:
jobs:
Coverage:
runs-on: ubuntu-latest
steps:
- name: Build Fuzzers
id: build
uses: google/clusterfuzzlite/actions/build_fuzzers@v1
with:
language: c++ # Change this to the language you are fuzzing.
sanitizer: coverage
- name: Run Fuzzers
id: run
uses: google/clusterfuzzlite/actions/run_fuzzers@v1
with:
github-token: ${{ secrets.GITHUB_TOKEN }}
fuzz-seconds: 600
mode: 'coverage'
sanitizer: 'coverage'
# Optional but recommended.
# See later section on "Git repo for storage".
# storage-repo: https://${{ secrets.PERSONAL_ACCESS_TOKEN }}@github.com/OWNER/STORAGE-REPO-NAME.git
# storage-repo-branch: main # Optional. Defaults to "main"
# storage-repo-branch-coverage: gh-pages # Optional. Defaults to "gh-pages".
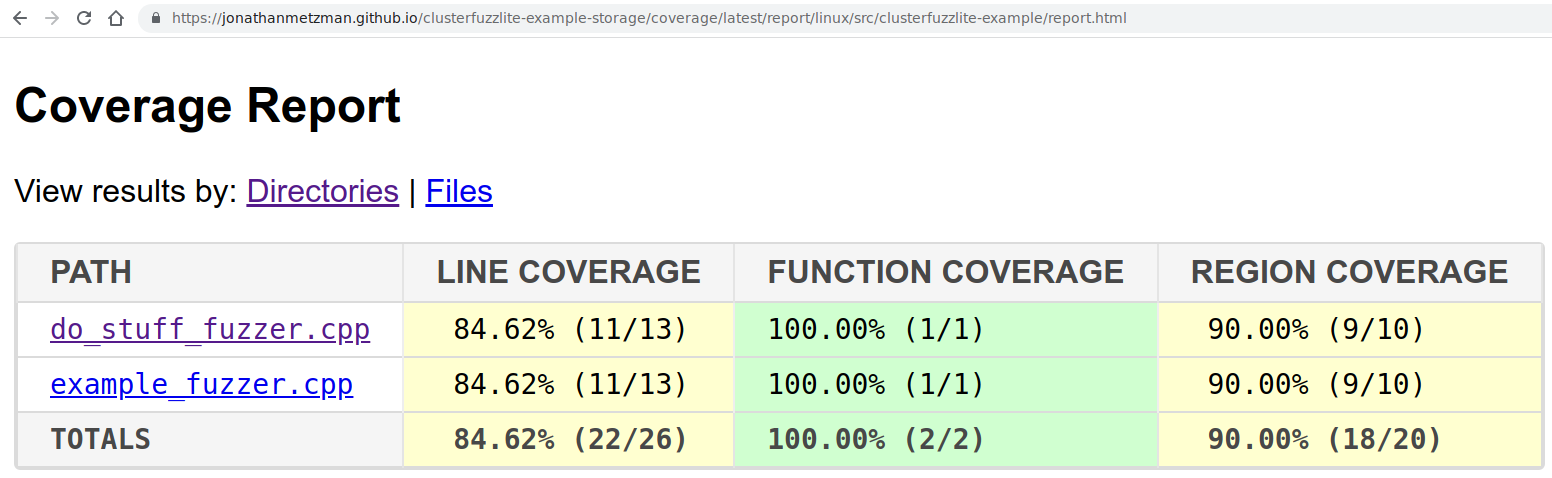
Make sure to change to the language to that of your target code. Optionally, edit the following fields to view coverage reports at https://USERNAME.github.io/STORAGE-REPO-NAME/coverage/latest/report/linux/report.html:
- set
storage-repo(instructions here) - set
storage-repo-branch-coverageto “gh-pages” (the default) - set
ownerandstorage-repo-nameto the appropriate values for your storage repo
Downloading artifacts
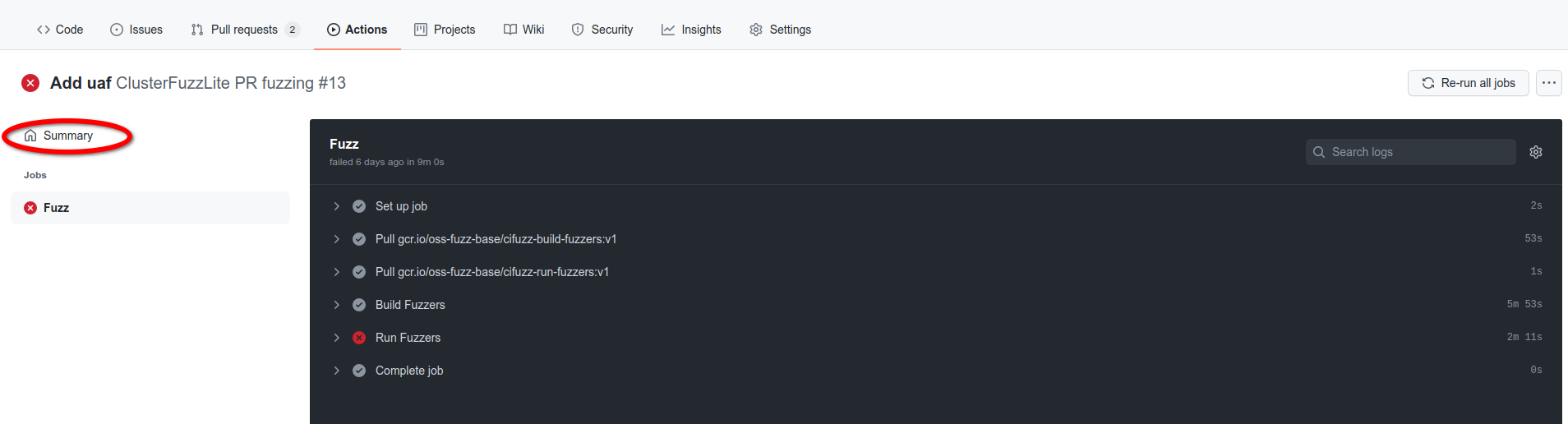
When the fuzzer crashes the input file that causes the crash is uploaded as an artifact. To download the artifact, do the following steps:
- Click on the summary from the run, as illustrated in the screenshot below:
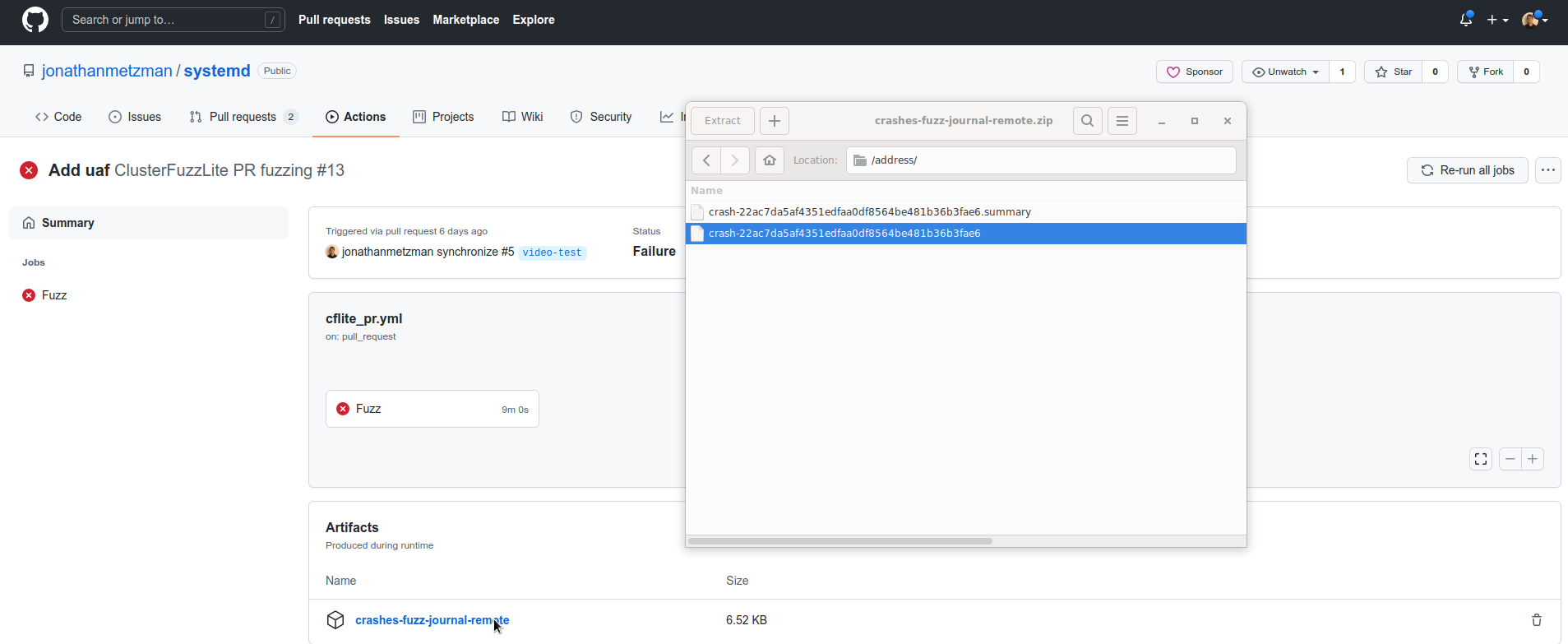
- Click on the artifact you wish to download from the summary page, as illustrated in the screenshot below:
Extra configuration
Git repo for storage
It’s optional but recommended that you set up a separate git repo for storing corpora and coverage reports. The storage repo will make corpus management better in some scenarios and will allow you to view coverage reports on the web rather than downloading them as artifacts.
An empty repository for this is sufficient. The corpus have to be uploaded in the repository under the folder /corpus/<fuzz_target>/ for each fuzzer.
You’ll need to set up a personal access token with write permissions to the storage repo and add it as a repository secret called PERSONAL_ACCESS_TOKEN. This is because the default GitHub auth token is not able to write to other repositories. Note: if you run into issues with the storage repo, you may have accidentally set the secret as an environment secret instead of a repository secret. 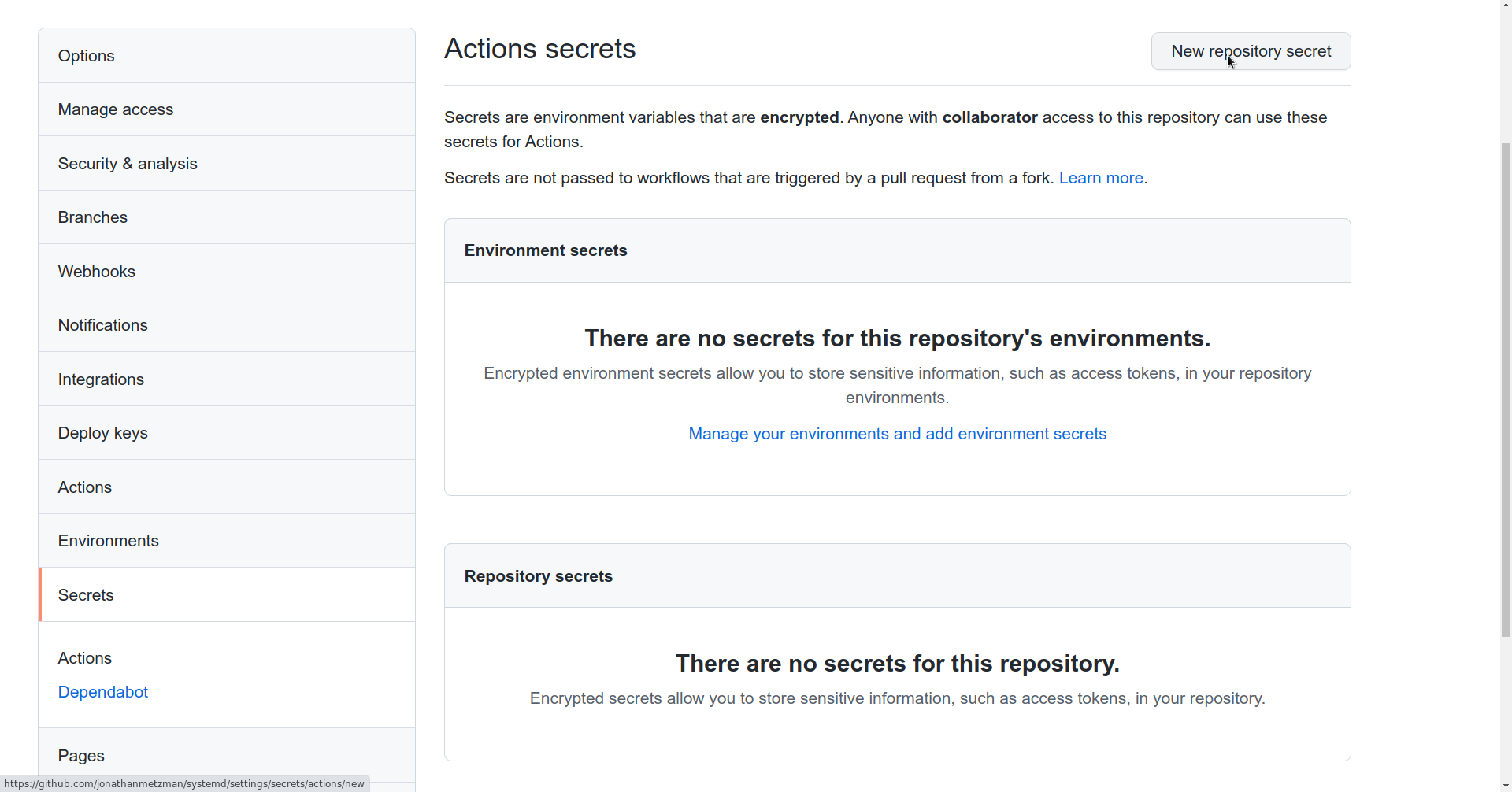
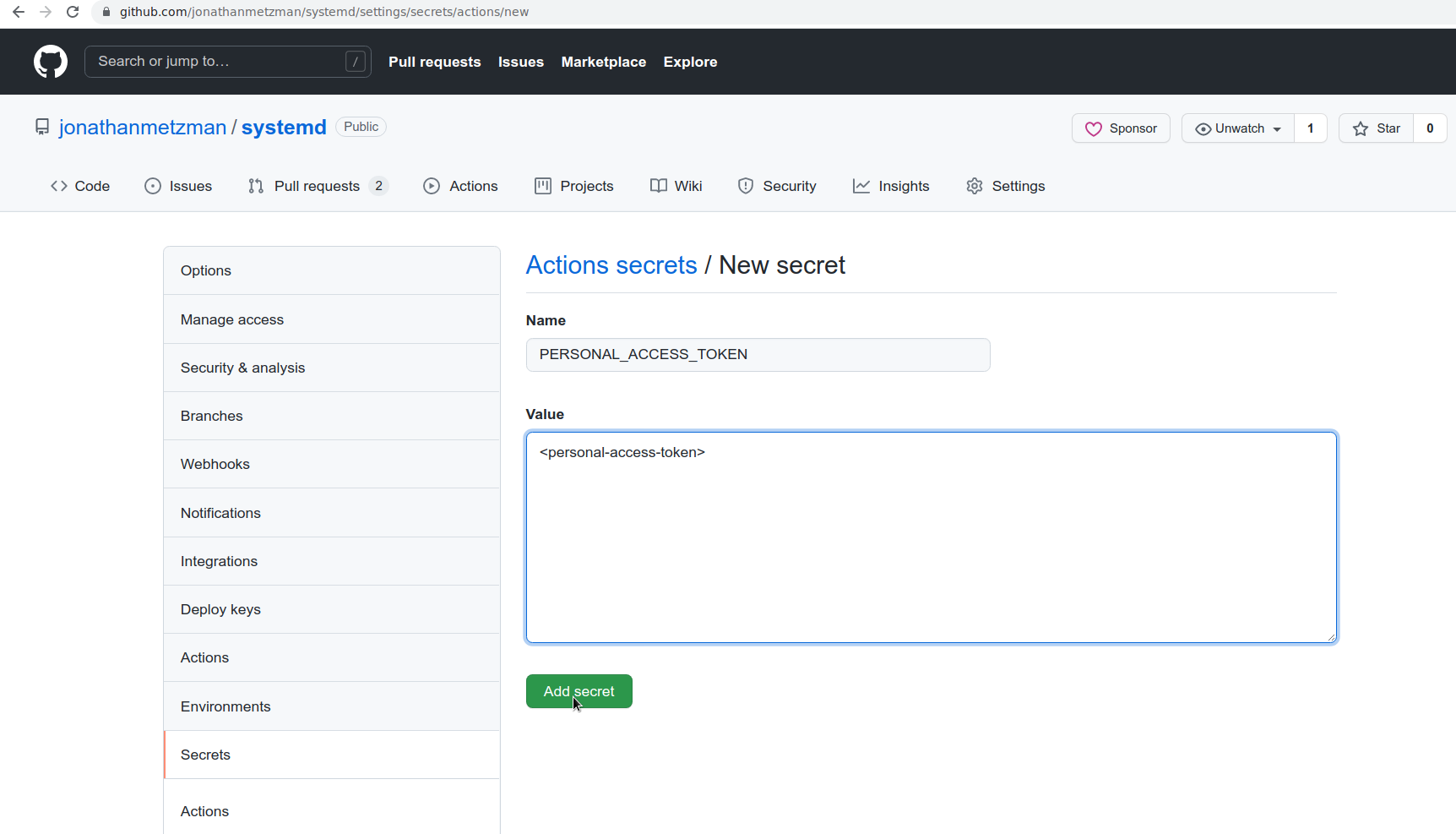
If you would like PR fuzzing to run only the fuzzers affected by the current change, you’ll need to add these same options to the “Build Fuzzers” step above. The “affected fuzzers” are determined by using coverage reports.
If a storage repo isn’t specified, corpora and coverage reports will be uploaded as GitHub artifacts instead.
Private repos
In order for ClusterFuzzLite to use private repos, the GitHub token needs to be passed to the build and run steps. This token is automaticallly set by GitHub actions so no extra action is required from you except passing it to build fuzzers and run fuzzers in each workflow file:
steps:
- name: Build Fuzzers
id: build
uses: google/clusterfuzzlite/actions/build_fuzzers@v1
with:
github-token: ${{ secrets.GITHUB_TOKEN }}
...
- name: Run Fuzzers
id: run
uses: google/clusterfuzzlite/actions/run_fuzzers@v1
with:
github-token: ${{ secrets.GITHUB_TOKEN }}
...
Note that if your storage repo is private, you should pass this token to every step that uses the storage repo.