Architecture
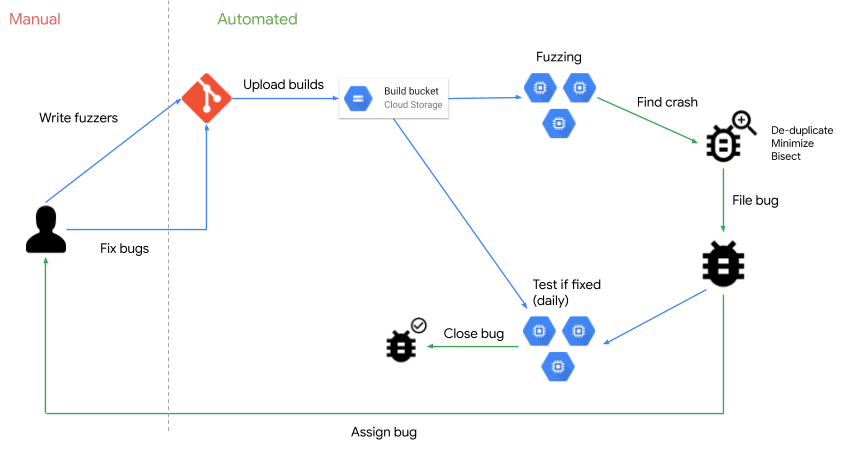
ClusterFuzz provides an automated end-to-end infrastructure for finding and triaging crashes, minimizing reproducers, bisecting, and verifying fixes.
Supported platforms
ClusterFuzz is written in Python. It runs on Linux, macOS, and Windows.
Requirements
ClusterFuzz runs on the Google Cloud Platform and depends on a number of services:
- Compute Engine (Not strictly necessary. Fuzzing bots can run anywhere.)
- App Engine
- Cloud Storage
- Cloud Datastore
- Cloud Pub/Sub
- BigQuery
- Stackdriver Logging and Monitoring
Note: The only bug tracker we currently support is the Chromium-hosted Monorail. Support for custom bug trackers will be added in the future.
Local instance
It’s possible to run ClusterFuzz locally without these dependencies by using local Google Cloud emulators. If you do, some features that depend on BigQuery and Stackdriver will be disabled due to lack of emulator support.
Note: Local instances are only supported on Linux and macOS.
Operation
The two main components of ClusterFuzz are:
- App Engine instance
- A pool of fuzzing bots
App Engine
The App Engine instance provides a web interface to access crashes, stats and other information. It’s also responsible for scheduling regular cron jobs.
Fuzzing Bots
Fuzzing bots are machines that run scheduled tasks. They lease tasks from platform specific queues. The main tasks that bots run are:
fuzz: Run a fuzzing session.progression: Check if a testcase still reproduces or if it’s fixed.regression: Calculate the revision range in which a crash was introduced.minimize: Perform testcase minimization.corpus_pruning: Minimize a corpus to smallest size based on coverage (libFuzzer only).analyze: Run a manually uploaded testcase against a job to see if it crashes.
There are two kinds of bots on ClusterFuzz:
-
Preemptible: The machine can shut down at any time, and can only run the
fuzztask. These machines are often cheaper on cloud providers, so we recommended using them to scale. -
Non-preemptible: The machine is not expected to shut down. It can run all tasks, including critical ones like
progressionthat must run uninterrupted.